В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны! Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна. Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2-х бит, на кофеварке с подкачкой на микроволновку.
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт). Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Текущим трендом на данный момент являются мультимодальные модели, это когда к основной LLM сбоку приделывают модуль распознавания изображений, что в теории должно позволять LLM понимать изображение, отвечать на вопросы по нему, а в будущем и манипулировать им.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
Сейчас существует несколько версий весов, не совместимых между собой, смотри не перепутай! 0) Оригинальные .pth файлы, работают только с оригинальным репозиторием. Формат имени consolidated.00.pth 1) Веса, сконвертированные в формат Hugging Face. Формат имени pytorch_model-00001-of-00033.bin 2) Веса, квантизированные в GGML/GGUF. Работают со сборками на процессорах. Имеют несколько подформатов, совместимость поддерживает только koboldcpp, Герганов меняет форматы каждый месяц и дропает поддержку предыдущих, так что лучше качать последние. Формат имени ggml-model-q4_0, расширение файла bin для GGML и gguf для GGUF. Суффикс q4_0 означает квантование, в данном случае в 4 бита, версия 0. Чем больше число бит, тем выше точность и расход памяти. Чем новее версия, тем лучше (не всегда). Рекомендуется скачивать версии K (K_S или K_M) на конце. 3) Веса, квантизированные в GPTQ. Работают на видеокарте, наивысшая производительность (особенно в Exllama) но сложности с оффлоадом, возможность распределить по нескольким видеокартам суммируя их память. Имеют имя типа llama-7b-4bit.safetensors (формат .pt скачивать не стоит), при себе содержат конфиги, которые нужны для запуска, их тоже качаем. Могут быть квантованы в 3-4-8 бит (Exllama 2 поддерживает адаптивное квантование, тогда среднее число бит может быть дробным), квантование отличается по числу групп (1-128-64-32 в порядке возрастания качества и расхода ресурсов).
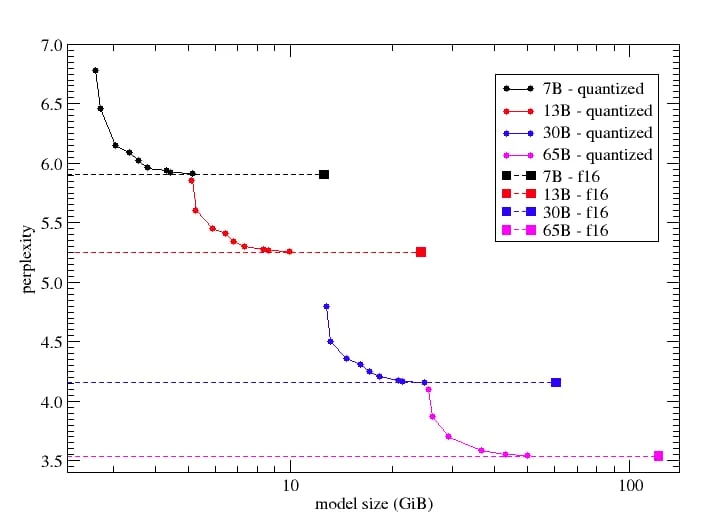
Основные форматы это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной. В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090. Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это серьёзно замедлит работу. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой: 1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии. 2. Скачиваем модель в gguf формате. Например вот эту: https://huggingface.co/TheBloke/Frostwind-10.7B-v1-GGUF/blob/main/frostwind-10.7b-v1.Q5_K_M.gguf Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt 3. Запускаем koboldcpp.exe и выбираем скачанную модель. 4. Заходим в браузере на http://localhost:5001/ 5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI 1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern 2. Запускаем всё добро 3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001 4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca 5. Радуемся
>>635448 → >Ну дай ты помечтать, а? Никакого коупинга, только суровый реализм. Коупинг оставим пользователям коммерческих нейронок, которые надеются, что у них доступ будет всегда и без цензуры, лол. >>635448 → >весь вопрос в том, как делать выбор токенов Именно. В настоящем мое тренируют отдельные слои, то есть часть входных и выходных слоёв общая. И ты никак не сделаешь из двух обычных слоёв спец-слой с выбором, ну не смержатся так они, и всё на этом. >>635449 → Пенальти пропиши. >>635451 → >Ебало северного моста представил Благо его устранили давно, да и южный сейчас уже почти полностью деградировал.
>>635451 → > На токены в секунду насрать если честно, если их не менее 1. Нууу, типа ждать 5 минут среднее сообщение - успеешь забыть что там было. Суть текстового рп в погружении, замедлиться для осмысления момента ты всегда можешь, но слишком долгое ожидание сразу нахер все заруинит. Но с задержкой обработки контекста соглашусь, на жоре даже с гпу это можно прочувствовать. >>635457 > Коупинг оставим пользователям коммерческих нейронок Тут нужна шутка про победы 7б. > В настоящем мое тренируют отдельные слои, то есть часть входных и выходных слоёв общая. Вон сотни колхозных мое из всратых замесов, хотябы что-то подобное наделать. Или вообще нейронка что по содержанию текста будет решать на какую сетку подавать. Или применить совместную генерацию, оценивая токены 3й сеткой. Варианты есть, но ресурсоемкость не для васянов-инджоеров.
>>635469 >Тут нужна шутка про победы 7б. У меня уже синяки от бесконечных фейспалмов от этих побед. Впрочем, дно за дном уже пробито, и заявления о поебде всего и вся звучат уже от 3B и даже 2B. >Вон сотни колхозных мое из всратых замесов Жаль я хлебушек, а так бы оценил, какие части слоёв принимают участие. Вангую, там одна сетка работает, остальные память занимают, лол.
>>635488 > от бесконечных фейспалмов от этих побед А ты иди арену посмотри еще! > заявления о поебде всего и вся звучат уже от 3B и даже 2B С этого уже неиллюзорный проигрыш можно ловить. Запилить под эти тесты что-то типа векторной базы - победоносца. > Вангую, там одна сетка работает, остальные память занимают, лол. Может и так лол. Пару 34б вроде хвалили что лучше одиночных, но представить себе экспертов на довольно горячей yi - это нужно богатое воображение. Хоть качай и пробуй. Нужно погружаться, изучать и т.д., сложно и пугает перспектива в итоге понять что оно на самом деле еще сложнее и все это напрасно.
>>635452 (OP) О а пик4 наш чел в треде? Я в первый раз эту пикчу увидел в треде 3д печати. Тоже хочу в 3д принтеры вкатиться, интересно сколько это по деньгам.
Любого занюхивателя коупиума, крутящего на своем 1050ti звере 7б и утверждающего что гпт сосет я все равно буду уважать куда больше чем ретардов которые у барина генерации крутят. Как вообще человек может мирится с цензурой такого толка я хз. Это как однажды у меня кореш с айфоном ходил и сказал "бля я чет не могу в этот телеграмм канал зайти мне телефон запрещает". Телефон запрещает, понимаете? Вот у барина такие же сидят. У меня даже слов нет чтобы описать какое это дно.
>>635555 >Я в первый раз эту пикчу увидел в треде 3д печати Это моя вчерашняя пикча, я ее постил только в прошлом треде, в тред 3D печати видимо вбросил кто-то еще.
>Тоже хочу в 3д принтеры вкатиться, интересно сколько это по деньгам. Если не планируешь фигачить что-то сложное, требующее высокой точности, то хватит недорогих моделей, тот же Ender 3, как писал анон выше. У меня китайская дельта Flsun QQ-S Pro, которую я купил с рук за 10к с тремя катушками пластика в комплекте. Так что есть смысл поискать на авито, многим людям не заходит и они продают свои девайсы не дорого.
>>635562 Уважать нужно тех, кто осознает-понимает что делает а не искажает реальность ради оправдания своих ограничений. Шарящий раздобывший пару авс/ключ впопенов и спокойно применяющий ее, выбирая из-за возможностей сети для задачи или ограничений собственного железа - ничуть не хуже чем копиумный варебух, лелеющий мечту о том что вот вот сейчас сделают 7б, которая всех-всех подебит, и наконец-то он заживет а все остальные прибегут к нему сокрушаться и просить совета. Сравнивая же последнего с "проксечку писечку@флагшток за аксесс токен@фу ваши локалки не нужны они тупые@дайте жб прошлый протух я не локуст" - не ясно кто кого, слишком уж ужасные сорта. >>635637 > У меня китайская дельта Божечки, за що? Но лучше чем ничего >>635778 Если все аккуратно организовать - вполне, но ллама там будет выступать лишь частью, которая разбирает команды-запросы. По отзывам если модель нормальная, то последовательность уровня "открой занавески, поставь окно на проветривание на 5 минут и приглуши свет" обрабатывает, успешно превращая ее в 4 команды из которых одна с задержкой исполнения.
К слову про использование 1030 и p40 одновременно, я таки нашел способ - нужно заюзать дрова от Titan X, он подходит для 1030 и p40, просто на p40 его надо будет ставить руками через диспетчер устройств и выбрать из списка Titan X (Pascal). Правда потом придется сделать несколько твиков в реестре по этому гайду: github.com/JingShing/How-to-use-tesla-p40 Но зато потом все будет работать нормально.
>>635781 Ну, земля пухом. Квартира застрахована? >>635778 Да ничего, одной ЛЛМ тут мало, как минимум входную речь будет разбирать какой-нибудь вишпер, ответы озвучивать силеро, самим домом рулить хзАссистент (не помню как его), и ко всему этому будет прилагаться куча скриптов на каком-нибудь пайтоне. Вот скрипты тебе и придётся писать. А так GBNF Grammar, чтобы выдавал валидный json с нужными опциями, и вперёд. На такой разбор даже 7B подойдёт, сможешь удивлять тяночек командой "Хули так светло, сделай интимную обстанов очку". >>635786 А способ с отдельной последовательной установкой двух устройств уже не катит?
>>635791 А, тьфу, меня проглючило что ты про бп. Да, я знаю, что китайские дельты это такое себе, но он достался мне дешево и его уровня качества печати мне хватает более чем. Большая облась печати мне пригодилась только один раз, когда печатал на нем элемент бампера.
>>635813 >способ с отдельной последовательной установкой двух устройств уже не катит? У меня почему-то не взлетел, хотя, может быть я что-то делал не так.
>>635917 > самосборку Для нее нужен уже рабочий принтер. Появились там вообще готовые нормальные проекты? Ранее была сплошная кринжатина с расходом килограммов пластика вникуда, безумными конструкциями из профиля в больших габаритах, но при этом микростолика с консольным креплением(!) на тонкие валы из пластилина, или 15-ю каретку, что плохо воспринимает нагрузки в этом направлении. Если самому разрабатывать - топчик, весело, увлекательно, но будь готов к долгострою и собиранию граблей. >>635918 > и выше Можно загрузить q5_k_m с микроконтекстом, не более. С более менее вменяемым q4_km - потолок, но его достаточно.
>>635925 Дешевле выйдет врятли, но вроде в самой сборке нет ничего сложного. Единственное что я ебал какие-нибудь программы писать. >>635927 Ух бляяя пердолинг. Зато швабодка.
>>635934 Еще какой. Ну рили смысл самосбора в получении или особых характеристик (габариты), или в достижении высоких параметров без больших затрат и зависимости от кривого разработчика. Например, для печати разных деталей с претензией на прочность нужен большой габарит по самому столу, а высоты даже больше 150мм нечасто встретишь - ранее в любительских проектах было все наоборот с фокусом на высоту. По дефолту заложена херня вместо пары высокорасходных хотэндов, вывозящих сопла 0.8-1мм чтобы печатать габаритное на адекватных скоростях, и хотябы один из которых должен быть директом. Нормальных направляющих тоже офк никто не делает, в лучшем случае надежда на самовыравнивание corexy, которое не работает на ускорениях если тяжелый хотэнд уехал от центра. С другой стороны, объем пердолинга таков, что если тебе под конкретные задачи - лучше сразу отдай много денег за зарекомендовавшее готовое решение.
>>635778 Охуенная идея, заодно настрой автоматический постинг результатов, потому что не факт, что сможешь сам запостить в каком-то момент. =D Но очень интересно!
1. Качаешь дрова на свою видяху и на Tesla P40 (официальные, с сайта нвидиа). 2. Ставишь Теслу. 3. В реестре че-то там где-то там меняешь. Внести изменения в реестр по пути: HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\Control\Class{4d36e968-e325-11ce-bfc1-08002be10318}\ В папке относящийся к Тесле (например: 002. В ключе DriverDesc указано имя адаптера/Теслы) …установить драйверы Tesla, в папке "001" (относящийся к Тесле) удалить в реестре ключ AdapterType и установить EnableMsHybrid = 1, перезагрузить в безопасный режим, установить драйвер второй дискретной видеокарты, в папке "002" (относящийся к второй дискретной видеокарте) в реестре установить EnableMsHybrid = 2, перезагрузить. 4. Устанавливаешь дрова видяхи. 5. ??? 6. Профит! И твоя основная видяха, и Тесла работают одновременно, каждая со своими дровами.
Правда я не помню, что именно ставил — 1 или 2. Вроде EnableMsHybrid = 2 поставил и все.
>>635813 … а она тебе в ответ: Как ИИ-модель я осуждаю такую лексику, пидорас, пошел нахуй. И врубает на 100% все лампы во всех комнатах.
———
А если серьезно по поводу лламы и умного дома, то надо понимать, что модель сама пассивна и не разговаривает (и ничего не делает) самостоятельно. Нужны триггеры — например по времени. Но в общем, как сказали выше, да, обрабатывать команды и запихивать их в скрипты — вполне можно, если вдруг хочешь.
>>635972 Если кто-то не понял пунктов меню, а то неочевидно написано: Обе видяхи сразу в компе. В начале ставишь дрова на Теслу. Потом колдуешь в реестре. И доставляешь дрова на вторую-игровую видяху. Все это делается через диспетчер задач «найти дрова в папке» и папка, которая распаковывается из скачанных драйверов.
>>635972 > … а она тебе в ответ: Как ИИ-модель я осуждаю такую лексику, пидорас, пошел нахуй. И врубает на 100% все лампы во всех комнатах. Это ерунда, вот какой же кайф будет если она решит залупиться, мммм >>635974 Просто поставить студио версии драйверов не катит? Говорят работает. На прыщах карточки +- одной серии даже разных семейств вполне себе дружат, если машина прежде всего под такого рода расчеты - тащить туда шинду будет вредным.
>>635974 >И доставляешь дрова на вторую-игровую видяху. >Все это делается через диспетчер задач «найти дрова в папке» и папка, которая распаковывается из скачанных драйверов. Пробовал так, но тогда драйвер теслы отваливался с какой-то ошибкой.
>>635972 >Как ИИ-модель я осуждаю такую лексику Я про GBNF Grammar для кого упомянул? У модели выбор или открыть кавычку, или написать тег, или закрыть кавычку. Бурчать тупо некуда. >>635983 >Это ерунда, вот какой же кайф будет если она решит залупиться, мммм С чего бы? Если не мутить с лишним контекстом, то каждый раз будет чистый запуск.
>>636119 Там в запросе должен быть набор статусов, перечень планировщика и прочее чтобы могло адекватно работать. И тот же мистраль 7б любит скатиться в луп при удачном сочетании, на гриди энкодинге так очень часто, хотя, пожалуй, является наиболее рациональной моделью для подобного применения. В любом случае небольшой но шанс фейла есть, нужно придумывать как такое обрабатывать.
>>635469 >Нууу, типа ждать 5 минут среднее сообщение - успеешь забыть что там было. Суть текстового рп в погружении, замедлиться для осмысления момента ты всегда можешь, но слишком долгое ожидание сразу нахер все заруинит. Не совсем, 850мс на токен для 70В модели на самом пределе, но терпимо. При потоковом выводе. >Но с задержкой обработки контекста соглашусь, на жоре даже с гпу это можно прочувствовать. Context shift спасает. Но да, для того чтобы ускорить процесс многие люди идут на большие траты - например покупают 4090 и обламываются :)
>>635990 А в реестре-то все настраивал? У меня 4070ти с Теслой работало одновременно (тока грелся бутерброд так, что я ее убрал в итоге).
>>636119 Не, ну ведь она может и комментировать действия. Она может либо НЕ сделать то что ты просишь молча, либо НЕ сделать, и еще прокомментировать, если у тебя в граммаре это прописано. =) Ясненько?
> С чего бы? Если не мутить с лишним контекстом, Ну слушай, иногда контекст важен, ИМХО. Это то, чего не хватает в Алисе. Нельзя сказать «выключи свет… а, не, сделай слабее просто!» ну и вообще куча подобных моментиков. Только четкие одинарные команды.
>>636125 Были модельки, заточенные на команды, кста, насколько я помню. Но я тогда так и не попробовал. Но в общем, поддержу предыдущего оратора, без контекста ошибок будет крайне мало, ИМХО.
>>636191 > 850мс на токен > терпимо Может быть, зависит от болевого/терпильного порога. 7-8 уже медленновато, 4-5 - минимальная грань когда еще ощущается как "без ожидания". > например покупают 4090 и обламываются В чем облом? >>636252 > Были модельки, заточенные на команды, кста, насколько я помню. Те вроде из старых. Но если современные на подобное натренить будет лучше. Контекст априори будет, в начале нужно задать общие положения что и как, потом перечень доступных "команд и опций", формат их выдачи (json с набором команд для обработки по формату), текущие данные (время, температура, статус), перечень запланированного. Уже набегает и задача перестает быть такой простой. Можно, офк, подсократить, делая ветвления и множественные обращения, но всеравно прилично, это уже далеко не "зирошот на вопрос бывают ли синие апельсины".
>>636376 >miqu-70b реально на уровне гопоты? Разве что турбы. >>636379 >до 72B. Слава Богам, я уж думал не дождёмся. Впрочем это китайцы, у них качество дутое.
>>636304 > Q8 Это "расшакал@перешакал" или там что-то делали для восстановления? >>636321 > В том, что целиком модель не влезает. Так никто и не обещал, всего-то нужна вторая карточка. >>636379 > по тестам Ну хуй знает. Но релиз нового семейства моделей, тем более крупных это круто, пора качать. Оно совместимо с лламой или опять ждать патчей лаунчеров?
>>636407 Уже кванты подвезли и работают, красава. А чего в их спейсе не потестил? Чисто по 3.5 постав - на русском пытается говорить, по крайней мере нет явных ошибок стоило дать инструкцию посложнее, с которой справилась микелла - полезли ошибки и надмозги как у обычных 70б. На вопросы, что знают любые трененные с использованием фандом-вики не отвечает и галлюцинирует. Инструкцию по тому, кого знает, выполняет достаточно неплохо. В общем, перспективы есть. >>636424 > войдёт только малый квант А больше и не нужно, если кванты не косячные заметить явную разницу можно ниже 4х бит. Если использовать лаунчер белого человека - там 5 бит даже влезают с ~12к контекста.
>>636321 >В том, что целиком модель не влезает. Поясните мне фап на большие модели. Больше 34b пока не гонял, от 7b отличается минимально, меньше зацикливаний разве что, но это костылями полечить можно. По сути, мозгов у них одинаково.
>>636430 >Поясните мне фап на большие модели. Больше 34b пока не гонял Скажем так, с увеличением количества параметров модель приобретает новые свойства. Если учесть, что все модели разные, то и свойства эти разные. Но интересные.
>>636376 Под пиво в чем-то можно спутать, но то больше к 120б франкенштейну относится. >>636549 > по скорам Почему тогда может то, чего не могут они? Если в чем-то и выражается что там модель "ранняя" так это в в отсутствии надроченности на бенчмарки, которая всирает реальный экспириенс. > по РП вообще кал хуже некоторых 7В Где-то ошибся в настройках, она не настолько ужасна.
>>636556 > Почему тогда может то, чего не могут они? Что она может, лол? Ты для начала попробуй, а потом будешь говорить такое. Даже в реддитовских рп-тестах она проваливает все тесты, я тут вообще не причём.
>>636559 > Даже в реддитовских рп-тестах Эталон, который заслужили. Чего стоит их отчаянное поединие кактуса в виде всяких q4_k вместо gptq/exl2 при возможности "потому что другие также делают значит это лучше". Или тестирование рп в детерминистик режиме на немецком. Она может косячить если применять их инстракт формат, и то только в начале чата. Контекст способна обработать несравнимо лучше копиумной залупы-победоносца, которую любят нахваливать. > Ты для начала попробуй Чел...
>>635452 (OP) Анон, есть вопрос. У знакомой умирает дедушка, живёт в другой стране, она последние 2-3 года плотно общалась с ним в мессенджерах. Чисто теоретически можно ли обучить что-то из имеющегося на контексте их переписок, настроив как-то на особенности характера и тп? Чтобы оно отвечало по теме? Оставим этику, мне интересен сугубо технический момент.
>>636653 Что за похавшую схему ты там мутишь? В целом можно поднять для чата какую-нибудь болрую модель которой пользуются в треде. Чем больше модель тем лучше. Для этого нужно оборудование. Как минимум дохуя оперативки, как максимум специализированные видеокарты. Дальше компилируешь персонажа на основе имеющихся данных и запускаешь чат. У модели быстро будет заканчиваться контекст и чем обширнее прописан персонаж тем быстрее. Так что дедушка получится с деменцией кек. И то нужно будет человеку как-то модерировать все это, если хочешь чтобы человек в слепом тесте в деда поверил. Мне то похуй что модель пишет ахинею или начинает говорить за меня я подредачу.
Вариант 2. Сделать датасет из имеющихся сообщений и смешать уже готовую модель со свежесозданной. Это надо учить модель и я в это вообще не лез. Не персонаж станет поумнее.
>>636696 спасибо за развернутый ответ. Ничего поехавшего нет, просто такой эксперимент пришел в голову, типа вместо Алисы - дед со своими приколами >>636706 буду благодарен если дашь линк
>>636620 В спиче про реддитовские рп-тесты соглашусь. И про немецкий язык, и про кривые промпты и инстракт, и про q4, реддитеры не то чтобы сильно в тестах придерживались какой-либо методологии.
Не в защиту Мику, но как проблемы этих тестов.
>>636638 Можно. Вопрос размера датасеты, стоимости, способы и результата (может так случиться, что «хорошо» не получится никак), но сама возможность есть.
Соболезную.
Вероятно, самый простой способ — дообучить маленькую лору (LoRA) и самые яркие фразы впихнуть в промпт. Но я не сильно в этом шарю.
>>636688 LangChain или LlamaIndex, или их альтернативы, не поднимал до сих пор, не шарю.
>>636696 > модель … начинает говорить за меня Можно сделать промпт от первого лица. Тогда она будет писать от себя. Это же переписка, а не РП, действия описывать не надо.
>>636638 Чисто технически - да, но лучше использовать не обучение а управлять с помощью контекста и подключаемой базы. Здесь вроде и норм, но в других случаях может быть максимально nsfl и с 90+% привести к ркн. >>636653 Изучай промтинг в рп и карточки, изучай rag и ее реализации. По моделям - смотри в сторону гопоты/клоды, из локалок то что сможет реализовывать подобное не запустится на "железе девушки" и твоем. >>636696 > Сделать датасет из имеющихся сообщений Очень несбалансированный получается, сама задача сложна, и ресурсов потребуется очень много. Возможно, но точно не с этого стоит начинать.
>>636696 >Это надо учить модель и я в это вообще не лез. Не персонаж станет поумнее. Я лез. Обучать на персонажах гиблое дело. Хуй знает, как с одним будет, я учил сразу много. В итоге они смешались у нейронки в голове, иногда один персонаж говорил в стиле другого, иногда бот терялся, кто есть кто и как должен себя вести. Не исключено, что тому виной малый размер модели и\или датасета, но тут с наскока точно не получится. Как вариант, нужно было размечать лучше, у меня разметки контекста считай не было.
>>636739 >>636728 >>636723 Спасибо за ответы, приятно находиться с вами на одной доске. Буду изучать предмет более детально. Что касается железа, в целом есть возможность арендовать GPU в облаке для обучения, для последующего использования можно ведь будет сделать урезанную локалку? Без лишнего контекста
>>636559 >Что она может, лол? Ну, я кидал скрины, на все базовые вопросы она ответила, в том числе на тест с 10 книгами, кстати единственная локалка, которая подметила, что книги не исчезают. Все остальные считают оставшиеся непрочитанные книги, хотя в вопросе про это ни слова. >>636688 Делаешь вектора из абзацев, потом встраиваешь в контекст подходящие вопросу куски.
Посмотрел я на курс доллара и прогнозы по его росту, посмотрел на цену Тесла, и заказал вторую на алике у непроверенного продавца подешевле, чем на Озоне и с доставкой за 2 недели. С моей удачей, чекайте, завтра доллар поползет вниз. =D
Осталось материнку взять надежную и с двумя PCI-e.
И комплект на ближайший годик готов, думаю хватит.
Как же заебало что они тренируют модельки на отходах гопоты и клода. Да собери ты нормальный датасет блядь, мерджани с еребусом если не можешь сам собрать. Везде сука молодые ночи и министрации еще и от моей личности в ответе бота.
>>636945 >С моей удачей, чекайте, завтра доллар поползет вниз. =D Чувак с баксами, ты? >>636952 >Везде сука молодые ночи и министрации Ты так пишешь, как будто в порносетах от людей что-то лучше. Эти молодые ночи не от ИИ пошли. >>636969 >писали фразы на перемешенных языках, то есть фразы где во фразе допустим каждое слово на своем языке Но... Зачем? А главное нахуя. Впрочем всё равно скачаю, сразу на жесткач, в архив.
>>636753 > В итоге они смешались у нейронки в голове, иногда один персонаж говорил в стиле другого, иногда бот терялся, кто есть кто и как должен себя вести. Дай унадаю... > нужно было размечать лучше, у меня разметки контекста считай не было а, угадал. Считай ты буквально учил модель "говорить вот так или вот так" без какого-либо разделения. >>636754 > есть возможность арендовать GPU в облаке для обучения Да, но для самого нищего файнтюна 34-70б потребуется хотябы одна A100@80, для нормального файнтюна - 4+, а времени займет много. Считай попытка файнтюна - несколько сотен $ и она 100% будет неудачная. Всякие Q-lora на мелочи не потянут задачу. Ужать одну ллм в мелкую - считай что нельзя. Есть техники дистилляции и подобное, но пока слишком экспериментально и каттинг-эдж. На каком языке планируется общение то? Если русский то тут сразу к коммерческим сетям. Их, кстати, тоже можно "тренить", офк никаких весов ты никогда не увидишь, но можно "вставить туда денежку + датасет" а на выходе получить возможность арендовать то что там натренилось по особому тарифу. Офк рассматривать такой способ, как и в принципе тренировку для таких задач, не стоит, начни с rag. >>636945 > С моей удачей, чекайте Опускайте курс! А вообще если про удачу, то первое - не дойдет, второе - масса сценариев про > на ближайший годик из которых самый лайтовый - выход новых сеток, которые будут плохо работать на ней.
>>636952 > Да собери ты нормальный датасет блядь Собери! >>636998 > Я хитрый — я буду сидеть на старых! А как же новые победы? > А, как тебе? Огонь! Огонь? Хм...
Кстати, здесь чуть раньше аноны пытались угадать: что полетит на шару после p40. Мне кажется, что предполагаемые rtx 6000-8000 будут ещё долго актуальны, а вот tesla v100 с памятью огрызком 16гб имеет куда больший шанс стать ненужной. Хотя есть шанс, что их спишут в одно время, просто цена будет разной. В любом случае готовим много линий pci-e и блоки питания, которыми можно обогреваться.
>>637076 > предполагаемые rtx 6000-8000 будут ещё долго актуальны Они могут упасть в цене только в случае если появятся десктопные карты на 48гб с относительно доступные ценником. Если будут на 32-36 - несколько подешевеют, но останутся дорогими. Если хуанг решит оставить 24 - цена почти не изменится, только падение за счет возраста. > tesla v100 с памятью огрызком 16гб имеет куда больший шанс стать ненужной Она и мл-энтузиастам будет не нужна, когда есть 3090 что опережает по всем параметрам. >>637088 > dalai vs ollama vs LLaMA vs Alpaca > ишак vs упряжка vs bmw vs дорога Уровень связанности такой же. >>637104 Вот этого двачую и визардкодер. >>637125 7б шиз, брысь!
>>637134 > брысь Сам сосни хуйца. CodeLlama не умеет писать код. Самое смешное что она пишет код даже хуже чем чат-модель. Пикрилейтед в тесте скоры не просто по PPL, а по тому насколько валидный и правильный код пишет нейронка.
>>637076 >а вот tesla v100 с памятью огрызком 16гб имеет куда больший шанс стать ненужной Зато 32 гектарами HBM2 еще долго будет стоить космических денег.
>>637139 > Сам сосни хуйца. Твоя прерогатива. Кем нужно быть, чтобы соснув с использованием специализированной модели и получив результат хуже чат модели 7б - реально верить что проблема в ней, а не в тебе. > по тому насколько валидный и правильный код пишет нейронка Какой в этом смысл, если она не может понять инструкцию что от нее хотят какой код ей нужно написать? То, что одна команда решила нашаманить чтобы бустануть скор в лидерборде не делает их лучше, наоборот. Скоро и в "кодинге" пойдет эпоха побед, во будет рофел.
>>636995 >без какого-либо разделения. Но даже так нейронка, в целом, понимает, что от неё требуется. >Есть техники дистилляции и подобное Там нужен фулл датасет, на котором проходила тренировка. Если его нет, то любые "очищенные", "сжатые" и "ускоренные" модели - тупеют по умолчанию. Сжимал так модель в три раза, охуевал от loss в консоли 70+
>>637051 Да всё оно может, просто питон кривое говно. Тебе нужно найти место, которое вызывает ошибку и добавить туда кодировку utf-8 в явном виде.
>>637241 Не знаю на счёт гопоты, но визардкодер полный кал, в прошлом треде тыкал. Пиздобол, который не пишет код и на вопрос типа "ты специально говнишь и скидываешь кривой код?" отвечает "да".
>>637288 > не пишет код Ты хоть с корректным форматом визарда делал или на отъебись взял формат викуни/альпаки? Визард как раз топ по качеству кода, особенно если тебе надо реально рабочий код, а не бред.
>>637092 Спасибо анончик, правильно ли я разобрался, что мне нужна версия llama.cpp:full-cuda? Там еще есть llama.cpp:light-cuda. И я выбрал yi-34b.Q5_K_M.gguf. Которая 24.32 GB, large, very low quality loss - recommended. У меня 32 Гб RAM и 12 Гб VRAM
>>637288 > Но даже так нейронка, в целом, понимает, что от неё требуется. Верно, они умеют усваивать закономерности. Просто одной из закономерностей будет шизофазия аут оф контекст, такому лучше не обучать. Может не фулл датасет, но относительно большой полноценный сбалансированный, и знать все нюансы. > просто питон кривое говно > но визардкодер полный кал Очень похоже что тут четкая закономерность с убеждением > если инструмент нужно использовать вразрез с моими догмами - он плохой. Тогда не юзай их. > Не знаю на счёт гопоты Попробуй, даже интересно увидеть реакцию. >>637341 > правильно ли я разобрался, что мне нужна версия llama.cpp:full-cuda? Это где такое смотришь? Действительно нужна llamacpp с кудой, но обычно ее применяют или в составе text generation webui, или в koboldcpp. Можешь и другие обертки попробовать, но там свои нюансы. Чем жирнее квант тем медленнее будет работать и больше занимать, этот пойдет, можешь начать с q4_k_m. Не стоит использовать оригинальную yi, лучше ее файнтюны, например Tess-34B-v1.5b, Nous Hermes 2 - Yi-34B и другие. Почитай шапку и ссылку на вики, там все есть.
>>637425 Более позитивное восприятие результатов, которые генерируются быстро, не подмечал, или слишком занят кумом? С 20б сравни если не лень будет, и по самой этой модели выскажи. Действительно ли хороша, или шизит.
>>637426 За такие примеры меня, наверное, забанят, лол.
>>637431 По скорости генерации что тесла p40, что RX 6800 примерно одинаковы. Как раз с u-amethyst-20b.Q4_K_M и сравнивал, а он к слову, был лучшим из того, что влезало в рыксу.
Там на мику файнтюны появляются, 70б шизы должны быть рады А вот мамбу собаки никто не выкладывает, хотя времени натренировать было много, должны уже успеть сделать
>>637436 > Как раз с u-amethyst-20b.Q4_K_M и сравнивал, а он к слову, был лучшим из того, что влезало в рыксу Это заявочка, пора скачать тот дипсекс >>637442 > Скажет «нет ключа», чекаем? > Скажет «хуйня», чекаем? Возможно двойное бинго > Херня ваша гопота, какой-то ключ просит и никакого кода не сделала 0/10, а 7б пишет и по тестам рабочее >>637465 > Там на мику файнтюны появляются Нет какой-нибудь инфы о том, насколько они хуевые из-за применение квантованных весов вместо полных? Или, что еще может быть хуже, квант->квант и поверх него q-lora. > мамбу собаки никто не выкладывает Пиздец грусть. Может сами потреним? В 24 гига оно должно влезать.
>>637478 >Может сами потреним? В 24 гига оно должно влезать. Толку от еще одной 3b? Надо хотя бы базовую 7b, а их не выкладывают. Натренить тоже не выйдет Про файнтюны мику на реддитте писали, вроде понравилось им, хз как на самом деле
>>637478 >Может сами потреним? На чём? Как? Разве что пробрасывать pci-e to ip и организовать кластер p40 от анонов в треде и научить нейросеть самой базистой базе или задержки инторнета будут слишком большие? Как сильно нейросеть задрачивает pci-e во время обучения?
>>637479 > Толку от еще одной 3b? Так они "по тестам" ебут трансформерсы большей размерности. >>637482 > На чём? Как? Раскуриваешь доки мамбы, берешь их экзамплы, грузишь датасет, ждешь. Младшие из их размеров, а то и 3б должны помещаться в одну жирную видюху и обучаться с приемлемой скоростью. Офк речь о файнтюне а не создании базовой модели, хотя для последней машина с пачкой условных 3090 вполне подошла бы, за месяц что-нибудь бы вышло.
Анончики, тут LLaVA новую подвезли, говорят, 34В. Субъективно - хороша! Впрочем, я изврат и пытаюсь в сторителлинг по фотке тян, а ллава имеет привычку некоторых тян упорно посылать к психиатору... Пруфы:
>>637541 > Субъективно - хороша! Выкладывай тесты. Новую ллаву все никак не получается посмотреть. Мультимодалки от YI не особо понравились, 34б хоть умная но подслеповата и не понимает культуру. С жорой оно раньше не работало, но 24-48 гиговые могут ее запустить, немного поправив код из репы, добавив команды битснбайтса. > я изврат и пытаюсь в сторителлинг по фотке тян Как делаешь?
> Что на тему альтернативных моделей? cogvlm/cogagent, moondream, неиронично бакллава.
>>637535 >Так они "по тестам" ебут трансформерсы большей размерности. Запускать все равно не понятно как, даже файнтюны уже есть на эти 3b, а толку, я не смог, какие то ошибки вылезали Ну и не верю я в сетку с маленьким количеством слоев
>>637299 >Визард как раз топ по качеству кода Я не спорю, что он может быть топом. При условии, что все остальные ещё хуже. Это как в дурдоме выбирать топ пациента, дебилы все, но кто-то из них хотя бы не срёт под себя. >>637393 >относительно большой полноценный сбалансированный Если не тот же полноценный сбалансированный, на котором была тренировка, то результат будет заметно хуже оригинала. >четкая закономерность с убеждением Что тут сделаешь, если питон реально уёбище. >Попробуй, даже интересно увидеть реакцию. Задал пару вопросов, в целом заметно лучше всего, что тыкал локально, но в итоге на асинхронности посыпался и стал делать не то, что я просил. Но на вид код рабочий, код пишет, пояснения даёт, даже комментирует. Ради интереса написал ему, что код говно и не работает, ботяра извинился и прислал то же самое второй раз. По-моему, только дельфин реагировал на такое адекватно и пытался переписать код, а не высирать одно и то же.
>>637628 Оу май, это же рили сторитейл/рп с мультимодалками. С таком случае с 34б может и взлететь, там ясный взор особо не нужен. >>637634 > Но она не имеет режима чата. Нужно написать. Ну для такого уже они хз, сам их рассматривал для капшнинга и взаимодействия с другими ллм, для этого нужна четкая работа с пониманием разного и минимумом галюнов, а не умение красиво сочинять. >>637664 дельфин 7б лучше гопоты? В целом ожидаемо.
>>637666 Cкачал, сейчас попробую, сатана. Только квантованный качал, а то там 60+ гигов ради пяти минут, ну его нахуй. Я так yi скачал и до сих пор не знаю, что с ней делать.
>>637667 >дельфин 7б лучше гопоты? Кто сказал? С зацикливаниями у него лучше, а вот с рабочим кодом довольно печально. И там восемь штук по 7b.
>>637676 >сатана питоний проверял на своем говнокоде, он неплохо так его переделал, говорить что это лучшая сетка для кода не буду, не особо щупал другие но его хвалили в комментах
>>637676 > Я так yi скачал и до сих пор не знаю, что с ней делать Зачем качал? > Кто сказал? Немного экстраполировал сказанное тобой. Это все - самые худшие из возможных вариантов субъективизма: "если оно организовано не так как я привык - значит плохо" и "если не заработало у меня без разбирательств - значит плохо". Не предметные конкретные замечания по нюансам и ложные выводы. > И там восемь штук по 7b Крайне маловероятно что их всем скопом полноценно тренили для кодинга, а не подсадили один файнтюн в микстраль или слепили мое на коленке. Способности в кодинге последнего - грустноваты.
>>637682 Дай хоть времени оценить, лол. По первым запросам сложно сказать. Не обосрался, дал, что просили, прокомментировал. На провокацию "код говно, а ты пидорас" не повёлся, попросил ошибки. >говорить что это лучшая сетка для кода не буду Топ это всё равно копилот. Тренирован на всём жидхабе, может прочитать сразу весь твой проект, а не несколько строчек, подстраивается под твой стиль. Только он платный.
>>637684 >Зачем качал? Кто-то в треде хвалил, накатил себе, погонял пять минут. >Немного экстраполировал сказанное тобой. А мог бы контекст сохранить с начала сообщения. >в целом заметно лучше всего, что тыкал локально
>>637686 > Кто-то в треде хвалил, накатил себе, погонял пять минут. Там по контексту укадывалось что скачал неквантованнаю, оттого и вопрос. > А мог бы контекст сохранить с начала сообщения Он сохранен, то ведь рофл и развитие сказанного в конце. Если бы совсем не понравилась самая юзер-френдли ориентированная и обустроенная сетка - было бы странно. Хотя еще от версии зависит, старая турба туповата.
>>637689 Я с кодерами контекст обнуляю каждые пару минут, так лучше работает. Сетка может сбиваться, забывать, что и как было отредактировано, забывать, что, например, я хуй забил на асинхронность и хочу писать потоки. Или наоборот. Или вообще не знать, что я накодил без общения с ней. Проще заново объяснить, что у меня есть и чего я хочу. Так что контекст сайз в самый раз. По крайней мере, для моих запросов. Пока что лучше визарда, погнал его в специфическую хуиту, довольно абстрактно, но объясняет, что мне надо делать. Я бы вообще не удивился, пошли он меня нахуй с такими запросами.
>>637716 >по контексту укадывалось что скачал неквантованнаю Там квантованное, но не жёстко, довольно дохуя весит всё равно. Я заебался скачивать. >Если бы совсем не понравилась самая юзер-френдли ориентированная и обустроенная сетка - было бы странно. Если бы она гнала нерабочий код, то вообще бы не понравилась, но этого нет. Потом ещё, может, закину туда пару запросов, с которыми дипсик не справится. Они туповаты абсолютно все и на это нужно делать скидку, общаться с сеткой, как с каким-то специалистом кодинга всё равно не выйдёт. Но какие-то вещи, особенно в незнакомых языках, упростить она может.
>>637744 > квантованное, но не жёстко Это как? Обычно 4-5 бита, офк всеравно весит много. > Они туповаты абсолютно все и на это нужно делать скидку, общаться с сеткой, как с каким-то специалистом кодинга всё равно не выйдёт. Еще как, особенно если не следовать рекомендациям по формату и делать оценки имея предубеждения, целенаправленно их очень легко поломать. Чего-то сильно узкого вне контекста не любят, идиотоустойчивость низка, а глупый юзер может банально не знать что нечто очень близкое к его запросу есть в других областях, но обозначить рамки и выдать конкретный запрос не удосуживается. Однако, если по формату и ясно сформулировать требование - сделают запрошенное, напишут под, перепишут заданный, дадут пояснения, в итерациях исправят ошибки, предлагаю приличный комплишн.
Гопота не только нормально кодит, но и может воспринять тупые и некорректные вопросы, в этом ее плюс и копайлот так не сделает.
Моя главная проблема с маленькими моделями - все по шаблону все фразы идентичны и похуй на контекст, на детали, на сеттинг, похуй пишу одно и то же. Персонажи разговаривают одинаково, девки ебутся одинаково, какую карточку не вставляй одни и те же шаблоны.
>>637763 Все так. Как вариант, попробуй использовать рандом таверны для изменения частей промта и инструкций, хоть какой-то элемент неожиданности будет если модель сможет им следовать лол
Deepsex оказался годен не только для кума, лол. Вот серьезно, ни одного исправления, ни одной перегенерации, никаких косяков с разметкой, не пытается за меня пиздеть и действовать, не циклится и не скатывается в набор букв. Понятное дело, что максимально простые условия с одним действующим персонажем, но большая часть других сеток даже с одним персом начинали шизеть довольно быстро.
>>637935 > 400x1252 За що? > не пытается за меня пиздеть и действовать, не циклится и не скатывается в набор букв Страшные вещи описываешь, на каких моделях такое происходит?
Опа-опа, только отвернёшься на пару часиков, а тут тебе некий чёрный railgun samorez уже представляет новые высоты достижений в области квантования моделей (https://reddit.com/r/LocalLLaMA/comments/1al58xw/yet_another_state_of_the_art_in_llm_quantization/). Обещают running 70B models on an RTX 3090 or Mixtral\-like models on 4060 with significantly lower accuracy loss - notably, better than QuIP# and 3-bit GPTQ.
>>637754 >целенаправленно их очень легко поломать Я даже не с кода первые вопросы задаю, просто "Как сделать X на языке Y". Дальше уже по ситуации. Так что ни о каком целенаправленном ломании речь не идёт.
>>637771 Что на счёт умственных способностей в 7b? Что-то у меня скепсис. Хотя работать будет явно быстрее, я по минуте ответы ждал на забитом контексте. За полчаса чата так и не прислал мне что-то, на что я мог бы сказать "ага, попался, пидорас"
>>637924 Имеет смысл брать, если у меня сейчас видимокарта с процом выжирают в пике 550 ватт голдового 850 ваттника? В лучшем случае, есть ватт 200 запаса на всё про всё.
>>637959 >Что на счёт умственных способностей в 7b? Дипсикер норм и на 7b, но понятное дело слабее чем 33b Впрочем я то качал и проверял как раз него на питоне, проверь, не справится где то большого будешь крутить
>>637958 I want to believe. @ Oops, something went wrong, please try again later.
>>637959 Ну, P40 жрет 180 для текстовых и 250 под полной нагрузкой (стабла, условная). Видимо, память медленная (даже не X), поэтому и ядро не полностью напрягается. Типа, для LLM сойдет. Но учти, что греется, кулер колхозить, нагрев на соседнюю и т.д.
У меня в 850 биквайт становились 3900, 4070ti и P40, но у тебя что-то по-жощще.
>>638012 Позже немного, пока упоролся в TTS. Опять. Снова.
>>638057 >Ну, P40 жрет 180 для текстовых и 250 под полной нагрузкой В целом, терпимо. Вроде. >что греется, кулер колхозить, нагрев на соседнюю Соседняя сама что хочешь прогреет, лол. >3900, 4070ti и P40, но у тебя что-то по-жощще. Процессор по паспорту тоже 65 ватт, как твой, на деле в пике до 90, вроде, жрёт. А видимокарточка просто 30 серия, они не такие энергоэффективные, как 40, до 400 ватт разжирается. Нужно поскроллить прошлые треды, посмотреть, сколько на одной p40 t/s на разных моделях и сравнить с собой, чтобы примерно понимать все глубины наших глубин.
>>638098 Мой тоже в пике 95 бывает, а так 88 в среднем под нагрузкой.
У меня хотспот был 88 в рейтрейсинге, а с теслой стал 105, и я ее убрал в отдельный ПК в итоге. Без рт но с теслой был ну 95. Все равно слишком много, ИМХО. А без рт и без теслы — 76.
Короче, Тесла добавила моей 17-20 градусов.
Я брал 4070ti ради энергоэффективности. Но 12 гигов меня подвели. =') Но Тесла теперь решает проблему, к счастью. В итоге я остался доволен.
>>637959 > видимокарта с процом выжирают в пике 550 ватт голдового 850 ваттника? Норм бп без проблем вывозит 110% продолжительной нагрузки, офк ресурса конденсаторам это не прибавит если так гонять постоянно. Если делить одну ллм на 2 карты - будет всплеск тдп только на обработке контекста (и то только в бывшей), во время генерации нагрузка на карточку не более половины (или в соотношении в зависимости от мощности и количества слоев на ней). Если катать 2 ллм одновременно на разных картах или другие сети - уже можно считать по максимуму, но если 550вт посчитано верно и бп - не творение припезднутых шизов, все будет нормально. >>638098 > 30 серия, они не такие энергоэффективные, как 40, до 400 ватт разжирается Топы 40й энергоэффективными тоже не назовешь. >>638117 > а с теслой стал 105 Поставил ее вторым слотом, перекрыв воздух? Это не дело, максимальный зазор с интенсивной продувкой между, или выносить подальше на райзере.
>>638131 > Топы 40й энергоэффективными тоже не назовешь. 4090 под андервольтом ценой 3-5% перфоманса начинает жрать 250-300 ватт при максимальных нагрузках. Таких холодных карт у куртки ещё никогда не было, с учётом того что на 4090 ставят охлад чтоб рассеивать 600 ватт, а по факту оно в два раза ниже.
>>638132 > 3-5% перфоманса начинает жрать 250-300 ватт при максимальных нагрузках Ну да, ну да, seems legit > Таких холодных карт у куртки ещё никогда не было Ога, про паскалей с 800мв на чипе и частотами 1800+ в курваке уже забыли. > на 4090 ставят охлад чтоб рассеивать 600 ватт Тоже сильное заявление, при 100+ градусах на чипе?
>>638135 У амудэ-мусора там все еще печальнее часто бывает, как бы не пытались рассказывать о крутом качестве их божественного шапфайра по сравнению с "нищим" текстолитом хуанга. > в ллм Это во-первых, текстовые сети, кроме короткого всплеска на контекст, не могут ее нормально нагрузить. Во-вторых, ты попробуй в задачах где интенсивно используется куда, в обучении, классификации крупными моделями с нормально настроенным датафидом, или той же диффузии. Там будет упор в заданный тдп. В-третьих, 2445 это ни разу не 3-5% перфоманса от дефолтных 2900 В-четвертых, ты дай постоянную нагрузку а не ллм с регулярным простоем, и подожди минут 10 пока компоненты выйдут на температуру, если уж хочешь измерять.
Карточки то хорошие и адаптировать чтобы довольно урчать можно без проблем, но все не так сказачно как описал.
>>638149 > диффузии Почти 300 ватт там, всё равно нет прожарки, как тут пытаются шизики рассказывать. Самое большое что я видел - в киберпуке под трассировкой, 320 ватт. > дефолтных 2900 С каких пор они стали дефолтными? 2900 - это разгон до усрачки, оно даже не взлетит на стоковом напряжении. У рефа буст 2520, у других пикрилейтед. > компоненты выйдут на температуру Он просто будет обороты кулеров задирать, на 200 ваттах на минимальных оборотах обдувает или вообще останавливает при любых просадках нагрузки, оно не поднимется никуда с трёхкилограммовым куском меди на всю плату. Ты так рассказываешь про то как у меня, как будто рядом свечку держишь, лол.
>>638155 Случаем не обрезанный вариант у которого в комплекте переходник на 2-3 8пиновых вместо 4х? > 2900 - это разгон до усрачки Хуясе ебать, сраный палит ползунком больше берет, пикрел в стоке. > Он просто будет обороты кулеров задирать Смотря какой алгоритм/курва, но прогреется все равно выше. > Ты так рассказываешь про то как у меня, как будто рядом свечку держишь, лол. Нет, это ты имплаишь что по коротким пускам с загрузкой на 200вт и ужатыми в хлам лимитами можно делать выводы о том, что этого хватит на 600вт и самая холодная карта в истории. Любую современную даже амудэ если увести от стоковой кривой напряжения вниз, подобрав вручную порог и снизив частоту, то можно объявлять сверхэнергоэффективной по сравнению со стоком, толку с этого.
>>638132 Во, кстати. Кто разбирается, подскажите годный источник инфы и инструкций по undervolting карт Nvidia (у меня 3060). Не, гуглить я умею, но вдруг кто-то уже в теме.
И чтоб два раза не вставать, как безопаснее разгонять RAM, если в биосе настроек оверклокинга нет никаких (пека брендовый готовый, увы)? Читал про Thaiphoon Burner, но с ходу лезть перешивать SPD как-то сцыкотно.
>>638102 Если бы ещё по перформансу аж треть от 4090, заебись бы было.
>>638117 >Без рт но с теслой был ну 95. Все равно слишком много, ИМХО. Ну я вряд ли буду гонять и теслу, и рт одновременно, trt всё-таки хуйня какая-то. У меня без тесл ниже 75 всегда на 100% загрузке продолжительное время. Но шуметь начинает. >Но Тесла теперь решает проблему, к счастью. Я так подозреваю, что у теслы памяти больше, но работать она будет крайне медленно. Хотя и быстрее подкачки ram. Я тут уже пытаюсь ебать нейронки в mixed precission с fp8, а с теслой придётся обо всём таком забыть, что будет минус перформанс, сам гпу слабее, ещё удар.
>>638131 >уже можно считать по максимуму Ну я не думаю, что будет максимальная нагрузка вообще хоть когда-то. Если ебётся гпу, то простаивает проц, если ебётся обе карты, то вряд ли обе на 100%. Короче, можно брать, лол. В крайнем случае, отрыгнёт БП и все комплектующие вместе с ним. >Топы 40й энергоэффективными тоже не назовешь. Ну хуй знает, возможно. Я просто смотрю на свою адову печурку и охуеваю.
>>638174 По сути, TDP и должен быть потребляемой мощностью, но его всегда занижают в угоду "посмотрите, какой камень холодный". А так, любой кремний это просто нагреватель, жрёт сто ватт - греется на сто ватт. А энергия, которая тратится на вычисления просто в районе погрешности от этих ста ватт.
>>638177 >А энергия, которая тратится на вычисления просто в районе погрешности от этих ста ватт. То есть вычисления превращают электрический ток в {свет, магнитное поле, радиоактивное излучение}? У вычислений нет энергии, это абстрактная величина. Вся энергия (100%) тратиться на поляризацию диэлектрика, открытие/закрытие каналов затворов мдп транзисторов.
>>638177 > а с теслой придётся обо всём таком забыть Ее берут только под ллм или мелкосетки четко осознавая, что с высокой вероятностью станешь ее последним хозяином. Учитывая цену и возможности в текущих ллм - это приемлемо. > Я просто смотрю на свою адову печурку и охуеваю. Ты еще подумай куда все это пихать. Чтобы охлада даже крутая-эффективная, но сделанная по традиционной схеме работала - перед кулерами карты должно быть порядочно пространства, 2-3 слота. Нечувствительны к такому только турбо версии. Когда же по дефолту охлада занимает 3.5 лота, то места для чего-то еще толком не остается. Добавить сюда что во многих матплатах первый слот смещен на 1 вниз, в большинстве корпусов только 7 окон по pci-e - дисвидули. Возможным вариантом остается только длинный райзер и размещение в странной позиции где-то еще внутри корпуса. >>638179 > радиоактивное излучение Такого там нет, в остальном конечная фаза и побочный эффект всех процессов вычислений в полупроводниках - тепло и немного эми, все так.
>>638159 > палит хату спалит Они и гонят в усрачку, работая как самолёт на 2000 оборотах и жаря. Я тебе показал сколько у ануса в стоке, у стриксы сток 2610 - а это фактически топ среди 4090. У меня в стоке тоже 2610, в ОС-режиме - 2760. Вот держи в ОС, прирост производительности в LLM нулевой, +150 ватт к жору. На втором пике каломатик в 1024х1024, тут уже как раз почти 5%. > сраный палит ползунком больше берет, пикрел в стоке Не вижу 2900 на 1050. > амудэ Про 7900 XTX на релизе помню кучу воплей красных, что этот кал в стоке сдыхал от перегрева, жаря под соточку на частотах ниже 2000. Вот уж где энергоэффективность.
подскажите, аноны. смотрю я материнки под нейросетки, хочу допустим поставить три p40, у материнки есть три слота pcie, далее смотрю спецификацию (asrock Z790 Taichi): * If M2_1 is occupied, PCIE1 will downgrade to в режиме x8. If PCIE2 is occupied, M2_1 will be disabled. If PCIE3 is occupied, SATA3_0~3 will be disabled.
это что же получается, если я втыкаю три p40, у меня просто нахуй режется функционал матери. перестают работать M2_1 и САТА разъемы? и еще какие-то фокусы небось? какую тогда мамку смотреть для этого дела?
>>638179 >Вся энергия (100%) тратиться на поляризацию диэлектрика Нет, конечно, закон сохранения энергии никто не отменял. Другое дело, что величина энергии не переходящая в тепло - ничтожно мала, в районе десятых, а то и сотых долей процента. >>638186 >Учитывая цену и возможности в текущих ллм - это приемлемо. В целом-то оно да, но всегда есть какое-то "но". >во многих матплатах первый слот смещен на 1 вниз У меня под первым слотом nvme, а потом ещё два. Ещё одна карта влезет с запасом, похуй, тесла или что-то толще. На две уже райзер, станет вертикально, место в аквариуме есть. И БП менять тогда. А на вдув нужно будет ставить не три обычных кулера, а серверные, лол, с таким-то выделением. >>638198 >три p40 Серверные смотри, десктопному процессору линий не хватит, там всего 20 и 4 из них, скорее всего, будут зарезервированы под nvme, если на мамке она есть. Даже если нет, 8х3 это уже 24, больше, чем у проца есть. И он вряд ли будет уметь во что-то, кроме 2х8\1х16. Одна карта будет от материнки запитана, как ни крути. Что скажется на скорости.
>>638192 > работая как самолёт на 2000 оборотах и жаря Да не особо, у них норм охлада. Офк тут можно устроить брендосрач и насмехаться над гнилобитом вместо видеокарты, но даже в последних на 4090 значительно не экономили. По частотам положняк у тебя странный, глянь ресурсы и отметь что почти все карты и даже реф берут в стоке выше чем заявлено в бусте. > в LLM Очевидно что для ллм 4090 не является оптимальной, возможно потанцевал еще не раскрыли. > Не вижу 2900 на 1050. Перечитай участок, который выделил для ответа, дойдет. Пик1 крутанул ползунок, и это под полноценной полной нагрузкой. Если недонагружать то можно и делать рофловые скрины типа пик2, но о стабильности в полноценной работе там речи не будет. >>638201 > А на вдув нужно будет ставить не три обычных кулера, а серверные Хватает нормальных корпусных. Просто для управления ими использовать или внешнюю термопару если матплата умеет, или ближайший к одной из гпу датчик, чтобы они активничали когда нужно, а не ориентировались на процессор.
Анончики, стучусь в тред. Подскажите как сделать так что бы XTTS для Таверны, правильно обнаруживал текст для озвучания? У меня идёт перевод на русский, а так меняется с "прямая речь" на «прямая речь». Regex заменяет обратно с « на ". А вот XTTS обнаруживает текст ДО его обработки Regex. В итоге не выполняет озвучаение. Может кто сталкивался с таким косяком? Гугл не дает никакой помощи.
>>638131 > Если катать 2 ллм одновременно на разных картах или другие сети - уже можно считать по максимуму Кстати, да, когда я планирую свои проекты, я это учитываю, а вот тут написать забыл. Если нагрузка только от одного источника и она не распараллеливается, то считать стоит по очереди. А если нагрузка от разных источников одновременно, то дело другое, офк. Это правильное замечаение.
Но и в общем про хороший БП соглашусь.
> максимальный зазор с интенсивной продувкой между, или выносить подальше на райзере. Дак ото ж, что не куда и некак. Решил, что чем брать хороший райзер, проще вынести в отдельный ПК. Там еще мать заменю, и вторая P40 станет с зазором как раз.
А 4070ti у меня здоровая — три слова, и по ширине вылазит на вертикальные слоты PCIe. Даже райзер в корпус было бы неудобно втыкать.
Но все верно говоришь, да.
>>638149 Справедливости ради, я понизил 4070ti с 300 до 200 ватт и частота у меня достигает 2710 (что на 100 МГц больше турбо). Но это андервольтинг, канеш. В стоке она горячевата. При этом, она холоднее 3090 (та 400 ватт жрет), так что в каком-то смысле 40хх энергоэффективные. =) По сравнению со старым поколением.
>>638155 У меня 4070ti брала 3000 в разгоне и выше. Но нахрен нужен разгон за такие бабки. =) Я вам тут не 5600 до 5600X…
>>638174 TDP — это выделяемая мощность. Но она составляет 99,(9)% (ибо КПД процессора крайне низкое) от потребляемой. Вообще, это маркетинговая хрень. Все верно. 65 по паспорту, 90 по факту, отличиями можно пренебречь, почти все уходит в нагрев. =) Ну, в общем, уже несколько человек до меня пояснили, да.
>>638186 > под ллм или мелкосетки Ну, TTS, STT на ней отлично бегают, SD терпимо, так что можно брать для многих сеток, на самом деле. Опять же, или в трансформерах, или Жора нарожал много квантов, не только ЛЛМ.
>>638195 На куда 11.8 есть жизнь, а порою даже быстрее по перформансу (незначительно). =) Но я бы не брал, конечно, там вообще старье же.
>>638198 Серверную за полляма? :) Ну, шучу, но куда-то туда, да. С другой стороны, если собирать под ллм — нах тебе сотня ссд дисков. Пихнешь один с моделями и с софтом и забудешь.
>>638201 > что-то, кроме 2х8\1х16 Опять же, x8/x4/x4 вполне норм, а так и на x8/x2x/x1 можно посидеть, ллм размером с небоскреб ты на памяти будешь гонять вечность, перформанс будет один хуй в десятки раз больше, даже на x1.
Так что можно-можно. Даже моя игровая за 15к в биосе обещает x8/x4/x4. Не проблема. (минус nvme, ага)
>>638237 Не знаю. Тут речь именно про установку двух разных драйверов от NVidia. Думаю, с радеоном вообще проблем быть не должно. Ставишь разные дрова — и в путь. Но лично я, когда ставил теслу с радеоном — дрова просто не накатывал на радеон, мне она нужна была на пару включений в биос.
>>638286 Вручную в коде обрежь как тебе надо перед отправкой в xtts. файл \SillyTavern\public\scripts\extensions\tts\xtts.js функция async generateTts(text, voiceId) Если не умеешь в js или regexp, попроси какого-нибудь чат-бота, он напишет тебе. Я так себе обрезал перевод от неперевода.
инференция на CPU vs GPU
Аноним08/02/24 Чтв 19:40:07№638342202
>>635452 (OP) Согласны со следующем мнением, что даже топовые CPU в сочетании с быстрой RAM всё не сравнимы с достаточно старыми/дешёвыми GPU с точки зрения производительности?
https://www.reddit.com/r/LocalLLaMA/comments/162o3q0/comment/jxzu88p/ > Sure, you're going to get better performance with faster RAM running in more channels than slower RAM running in fewer. But even running the fastest RAM you can find in 12 channels with a badass CPU is going to be substantially slower than older, cheap GPUs. I don't think it's currently possible to beat a P40 speed-wise with any pure-CPU setup, no matter how much money you throw at it. > I know it's not exactly cutting edge hardware, but I have a 2695v3 with 64GB DDR4 running in quad channel. I get about 0.4t/s running 70b models on pure CPU. When I instead run it on my pair of P40s, I get 5-7t/s depending on context depth.
Подкиньте свежих рейтингов GPU с соотношениями цена/производительность.
>>638342 >2695v3 with 64GB DDR4 running in quad channel. I get about 0.4t/s running 70b Кек. У меня столько на кукурузене 1 поколения с 64 ГБ двухканальной DDR4-2400.
>>638342 > 2695v3 with 64GB DDR4 running in quad channel. I get about 0.4t/s Звучит как буллшит, если честно, должно быть хотя бы 0,5-0,6, а по-хорошему там перформанса на все 0,8. Лучше бы тесты на чтение скинул.
> 12 channels with a badass CPU is going to be substantially slower than older, cheap GPUs А какой смысл быть или не быть согласным с мнением, если есть математика и циферки? Кажись считали же, там до 4090 недотягивает то ли вдвое, то ли впятеро. Ну, короче, P40 он может и догонит, но не за эти деньги, сам понимаешь.
Поясните за P40, в чём суть и почему все на неё облизываются? Дело в количестве видеопамяти? Можно ли поставить её в пару к 3070 или каждый раз дёргать придётся?
Что ещё по моделям, какие топовые для кумеров сейчас? Вся так же frostwind база треда?
>>638420 Да. Память гораздо быстрее оперативной, большой объем, малая цена. Много не умеет, занимает место, требует колхозного охлада, громкая будет, но либо ты берешь 3090, либо 4090, либо пишешь письма своей вайфу. Ну, по идее там всякие 7900XT тоже норм, но суть ты понял.
———
Потыкал тестами Ллаву-1.6 — чуда не произошло, но получше Ллаву-1/1.5, да.
Все же, тут как и с текстовыми — нужен большой датасет.
>>638458 Ты либо переплачиваешь деньгами, либо компенсируешь дополнительным пердолингом. Поскольку в России много нищуков, то пердолинг часто предпочтительнее.
>>638237 Скорее наоборот, и объединить их точно не получится. Просто поставить в одном компе и давать разные нагрузки - без проблем, только придется иметь по паре экземпляров вэнва с разными торчами и остальным под каждую видюху. >>638287 > чем брать хороший райзер, проще вынести в отдельный ПК Объединить не получится так. Но если в отдельном пк дополнительно появится еще одна то это уже не проблема > для многих сеток, на самом деле Для тех где не нужно много врам 3060@12 с рук будет быстрее, меньше кушать, без ебли в охладой. >>638342 > 2695v3 with 64GB DDR4 running in quad channel Медленная рам. Пусть сравнивает тогда с apple m2 max/ultra, или современной платформе интела/амд с 4-8 каналами рам. p40 - некоторая аномалия из-за невероятно высокого (для ее архитектуры) перфоманса в ллм на жоре что в сочетании с ценой делает привлекательной, но не стоит экстраполировать это на все остальное. > свежих рейтингов GPU с соотношениями цена/производительность Их не то чтобы есть смысл составлять, если речь о ллм. Любая современная карточка обеспечит высокий перфоманс при запуске того, что влезет в ее врам. По объему рам интересны 3090/4090, некротеслы анломалия и потому сюда тоже отлично подходят. Если в отрыве от всего, то по прайс-перфомансу топ 3090 бу, в зависимости от цен или примерно соответствует или чуть лучше p40 по токен/рубль если брать по тестам местных анонов, или несколько проигрывает если брать невероятно высокие величины, о которых рапортуют некоторые ребята на реддите, но обойдет во всем остальном. Однако, для их пары потребуется уже бп серьезнее и с размещением гораздо сложнее. >>638420 > Дело в количестве видеопамяти? This + относительно высокий перфомас в llamacpp. Все, но этого достаточно.
>>638478 > протечёт Лол. Чтоб современные водянки протекли надо бокорезами шланг перекусить. Помпы у них дохнут через пару лет, да. Но протечки - это фантастика.
>>638471 КАК ЖЕ ТАМ ТУГО ммм Верхней очень жарко, пидорни 4090 вдоль задней стенки вертикально на райзере, нехрен кислород перерывать. А что за карточка сверху? И 3090 3 8пин же были.
>>638476 > 3090 бу Ебучая печ. С бу сразу лотерея, но в 99% нужен разбор и минимум замена термопасты. Если же влетаешь на прокладки, то там вообще жесть - устанешь подбирать толщину и чтобы было хотя бы не хуже, как было. И это если ещё нет проблем с гддр6х
>>638481 > КАК ЖЕ ТАМ ТУГО ммм Дааа, очень узкая щёлочка там осталсь.
> Верхней очень жарко, пидорни 4090 вдоль задней стенки вертикально на райзере, нехрен кислород перерывать. В этом корпусе нет такой опции, увы, там просто сетка на месте, где в других вертикальные слоты. Он ценен 8 горизонтальными слотами вместо 7 и продуваемостью. Очень жарко, но терпимо - гпу75, хот90, мем85 под Автоматиком бесконечным. Но так она только в ЛЛМ врубается же + ПЛ ей 70 сразу вставил.
> А что за карточка сверху? > 3090 3 8пин же были. Она самая >>638482 > Ебучая печ От палита. 330Вт может съесть и с 2 хвостов + слот.
>>638482 > Ебучая печ. Ну а ты чего хотел за такие деньги? Алсо сильно утрируешь с прокладками и прочим, эти карточки не настолько старые преимущественно. Не хуже ржавой бабушки-теслы >>638489 > гпу75, хот90, мем85 под Автоматиком бесконечным Хм, даже слишком холодно для такого расклада. Забавно что только с 3 слотами видел, а тут вон как, но даже в плюс.
Сколько вы бывшей выдает? Как тебе русская речь мику? AH AH FASTER HARDER @ THANK YOU, I'VE NEVER EXPERIENCED ANYTHING LIKE THIS BEFORE
>>638501 > эти карточки не настолько старые преимущественно Вышли 3 года назад, застали самый бум майнинга, где их насиловали без смазки годами в очень термо-нагруженном режиме. Я видел 2шт с рук. И в 50% лол там всё было плохо.
>слишком холодно для такого расклада Там 6х140, не забывай, ещё.
> 3 хвоста Да, ни 4090 не надо 600Вт, ни 3090 400Вт ни в Автоматике, ни в ЛЛМ. Это уже для игромеров. С ПЛ 70-80 они теряют копейки в скорости, но работают гораздо холоднее.
>Сколько вы бывшей выдает? Как тебе русская речь мику? Да я только в Кобольде пробовал, там около 13 т/с всего. Но явно быстрее, чем раньше. Генерит быстрее, чем читаешь + в мониторинге видна постоянная загрузка, а не рывками как раньше, когда 70б половину в 1 карту грузишь.
Речь у Мику хорошая. + понимание русского тоже норм: я ее не прошу на русском отвечать, но формулирую сам чаще всего на русском.
>>638505 > 50% лол Содомит. Но вообще отдавая 50-60-..к можно найти еще пару-тройку и время дойти до мастерской и сделать там обслуживание, если сам хлебушек. > С ПЛ 70-80 они теряют копейки в скорости В зависимости от стратегии применения пл в ллм могут и не просесть. Алсо +1200+1500 по памяти ползунком афтербернера, несколько бустит скорость в ллм и не только без сильного роста температур. Накати бывшую если есть место на диске, забудешь что такое ожидание контекста на больших и скорости бустанутся.
>>638515 > до мастерской Я прямо представляю какие там васяны из ремонтов телефонов и ноутбучных сервисов, которые впаривают несуществующие ремонты и подменяют детали. Лучше уж самому.
>Алсо +1200+1500 по памяти ползунком афтербернера, несколько бустит скорость в ллм и не только без сильного роста температур. Накати бывшую если есть место на диске, забудешь что такое ожидание контекста на больших и скорости бустанутся.
Пока первый день, проверю, что всё стабильно и попробую. Модели вот только в основном все в ггуфе. Вы их сами конвертируете чтоли?
>>638518 > Вы их сами конвертируете чтоли? Можно сразу качать gptq, можно качать оригинальные веса а потом квантовать самостоятельно в желаемую битность exl2. Просто в гуфе надобности нет и на диске осталась буквально одна для тестов, теперь вот еще мику есть. Сконвертить без потерь качества особо не выйдет на данный момент, хотя в теории это должно быть возможно.
>>638478 У меня в стоке бирюза, в нагрузке фиолетовый, и при 65° по процу — красный.
Воздушное лучше водяного, если его хватает, факт.
>>638489 Ну, продуваемость у него дефолтная. Три впереди, два снизу, три сверху, один сзади. Дуофейс про такой же, каг бе. Да и аквариумы — только по два «спереди» и сверху, да и вся разница.
Такой вопрос, что важнее в нейронках "ширина" или "глубина"? Планирую взять своего файнтюненого идиота, докинуть ему слоёв, но при этом ни количество входных, ни выходных нейронов не изменится. Как и количество нейронов на слой. Это имеет смысл или всё равно хуйня будет?
>>638661 Мэх, маловероятно что там есть мультимодалки, ллм и что-то подобное, просто более мелкие сетки для компьютерного зрения. Неким достижением будет если сетка используется в контроле их движений. А так - ерунда большей частью, гляньте что делают активная безопасность и автопилоты в современных авто, самые приличные, кстати, на хуанге посмотрены. >>638756 Мельком, тебе для чего?
>>638799 Ну 34б там умная, можно сложные задачи ставить. Может и хайденгем, просто в интересующих задачах не показала себя круто. Предлагай как затестить.
>>638192 >+150 ватт к жору >5% Вся суть разгона в 2023. >>638363 >Кажись считали же, там до 4090 недотягивает то ли вдвое, то ли впятеро. По цене небось ещё и опережает, лол. Теоретически 12 каналов DDR5 могли бы выжать 500+ ГБ/с на чтение, на практике я уверен в прососе. >>638505 >Там 6х140, не забывай, ещё. Которые работают сами на себя, ага. Направление воздушных потоков если что будет примерно такое. >>638552 Все франкенштейны только так и делаются. В в ширину ты никак без переобучения не увеличишь. >>638763 >детройта Если ты про игру, то там говно вместо всего.
>>638756 Хуита, та ж самая Ллава 1.5 или типа того.
>>638903 > По цене небось ещё и опережает, лол. Я даже считать не хочу, если честно. Идея провальная на старте, как по мне. =) Вот через 10 лет, когда на алике… =D
> Если ты про игру, то там говно вместо всего. Графончик ниче так.
>>638903 >Если ты про игру, то там говно вместо всего Пиздострадания роботов выглядят нелогично, согласен С другой стороны нейросетки обученные на человеческих ражговорах на удивление человечны, тоесть имеют впитавшиеся с датасетом эмоции, характер и отношениия к чему то Детройт как пример будущего без развитой аугментики и без явного апокалипсиса, просто высокие технологии, ии и андройды с безработицей
>>638922 >Пиздострадания роботов выглядят нелогично, согласен Ага. Особенно тех, кого призывают прямо из магазина. Настрадались блядь при перевозке с завода до витрины, ну всё, надо громить человеков. >С другой стороны нейросетки обученные на человеческих ражговорах на удивление человечны Только когда их просят. Если попросить быть пылесосом, то даже самая умная нейросет очка будет гудеть и двигать щётками вместо рассказов про тяжёлую жизнь.
>>638903 > Теоретически 12 каналов DDR5 могли бы выжать 500+ ГБ/с на чтение, на практике я уверен в прососе Если совладать с нумой то норм будет, она подгаживает.
С пика орнул. Верхний правый действительно выкинуть, если синхронизировать расходы, чуть занизив у верхних относительно боковых - будет норм. >>638924 > Если попросить быть пылесосом, то даже самая умная нейросет очка будет гудеть и двигать щётками Новая идея для бота? >>638928 > Потому что делают сейчас упор на выполнение инструкций и максимальную безликость Не безликость а универсальность. > клепая буквально чат ботов > большая текстовая модель Хмммм
>>638903 > Направление воздушных потоков если что будет примерно такое. И не поспоришь. Щито поделать. Пока меньше 100 градусов норм. Верхняя только под ллм, переживёт как-нибудь.
>>638330 Антош, закинь если не сложно свой xtts файл. Мне ГПТ выдал processText(text) { // Replace fancy ellipsis with "..." text = text.replace(/…/g, '...'); // Replace "..." with "«...»" text = text.replace(/\.\.\./g, '«...»'); // Replace "..." with "—...—" text = text.replace(/\.\.\./g, '—...—'); // Remove quotes text = text.replace(/["“”‘’]/g, ''); // Replace multiple "." with single "." text = text.replace(/\.+/g, '.'); // Replace "..." with «...» text = text.replace(/\.\.\./g, '«...»'); return text;
А вот с async generateTts(text, voiceId) чет не оч. Озвучка так и не поменялась. Перечитывает весь текст, вместо того что бы озвучивать переведеный текст в «...» или —...—
>>638931 Да, точно, проц ещё сверху набрасывает. >>638932 >Если совладать с нумой А никак с ней не совладать. >>638932 >Верхний правый действительно выкинуть, Два выкинуть переставить вниз, один на раковую хуйню, которая прикрывает БП (в идеале её вообще снять, но скорее всего новомодный корпус не позволит), второй в сам низ корпуса, чтобы накидывал воздуха на первый. Толку будет в 50 раз больше. >>638933 >Щито поделать. Рецепт исправления выше.
>>638936 > проц ещё сверху набрасывает Это в плюс, обдув бэкплейта на который идет жар с задних чипов памяти. > А никак с ней не совладать. Это нужно шарить, в обусждениях на жору даже распараллеливание на ядра/узлы с сильно неравномерной мощностью предлагали с примерами реализации, так что скорее всего пути есть. Интел тоже показывали шуструю работу ллм на своих серверных профессорах - онли, что там с бэке было хз. > переставить вниз, один на раковую хуйню, которая прикрывает БП Полезет лишняя интерференция с крутиляторами видюхи, может повысить шум а эффективность даже снизится. Вот в самый низ корпуса на подсос из под днища и прогон вверх - правильная тема.
К слову о пердолинге, я тут подумал, я же могу, теоретически, через CLBlast заюзать P40 и RX 6800 одновременно? Понятно, что скорость будет ниже, зато 40 гектар видеопамяти.
>>638937 > Воткнул, поставил дрова и оно работает. 30 секунд пока не перегреется >>638940 > я же могу, теоретически, через CLBlast заюзать P40 и RX 6800 одновременно? Да. Правда хз как там настраивается сплит между ними.
>>638937 >поставил дрова Уже ебля, если в системе есть другая видеокарта (нвидия само собой). >>638939 >Это в плюс, обдув бэкплейта на который идет жар с задних чипов памяти. Так воздух с проца уже тёплый. Хотя да, наверняка прохладнее памяти. >так что скорее всего пути есть Есть конечно же, но NUMA систем унизительно мало, так что 99,(9)% софта под винду для него не оптимизировано. >а эффективность даже снизится Ну ХЗ, маловероятно.
>>638941 >30 секунд пока не перегреется А, ты про охлад. Я-то думал ты про софтовую часть. Я в конце концов таки поставил водянку на нее, теперь температур выше 65 градусов по хотспоту не видел.
>>638942 > Так воздух с проца уже тёплый Это, конечно, не > кулер холодит потому у меня температура процессора ниже комнатной а не припезднутые датчики но ушло недалеко. Температура воздуха там даже под нагрузкой едва 45-50 градусов достигнет, температура чипов там 80-90+, обдув воздухом чуть теплее лучше чем нихуя. > NUMA > под винду Не пугай так! > Ну ХЗ, маловероятно. Процентов 30, а если выйдет что там места мало то все 80. >>638943 Я мимокрок, но действительно про охлад, ставить водянку это тоже пердолинг знатный. Алсо врм покрывает или как его охлаждение организовано?
>>638947 >ставить водянку это тоже пердолинг знатный Никакого пердолинга, снимаешь обычный охлад, на четыре болта ставишь водянку, всё. Водянка организована она так, что обдувает врмки и видеопамять. В комплекте есть радиаторы на видеопамять, но они нахуй не нужны, просто обычного обдува хватает.
>>638931 >1605658420937.png КАКОЙ НАХУЙ ВЫДУВ НАРУЖУ? Так умеют только p40 и амдшные турбины (центробежные вентеляторы) с продольными рёбрами радиатора. А у тебя радики поперечные. Как они будут выдувать наружу? Эта шняга будет циркулировать воздух по всему корпусу и всё.
>>638960 Не из видях, а через слоты рядом (которые иногда делают вертикальными PCIe). А толкает оттуда наддув спереди.
Правда, с тремя сверху, наддув спереди ничего особо не толкает… И вообще, верхний передний кулер по сути своей воздух сразу высасывает, поэтому толку от него немного, канеш…
>>638955 > Никакого пердолинга > снимаешь обычный охлад Ну ты понял. Вообще когда охлада ставится на не крышку а на кристалл - уже требования к скиллу редко повышаются. > что обдувает врмки На них типа штатные радиаторы остались? Водоблок совмещен с крутиллятором получается, не целиком пластина на всю? >>638960 > А у тебя радики поперечные. Как они будут выдувать наружу? Весь пик про это а красная стрелочка - тот нищий поток воздуха вдоль стенки что унесет жар. Наверно.
Ваще, в плане охлада, меня дико дрочат долбоебы, которые в аквариуме ставят кулеры, которые в передней части компа на выдув. Это пиздец, у тебя воздух идет снизу (не всегда через кулеры), выходит вперед, вверх и назад. 1 точка нагнетания, 3 точки выгнетания, блядь. Арифметику такие горе-сборщики не учили в школе, выпустились из детского сада. Вот картинка в треде — отличный пример, как надо строить охлад. Рисуешь стрелочку и думаешь «а нахуя мне верхние передние кулеры, которые вообще не участвуют в вентиляции, перекидывая друг другу наружний воздух?»
Все это надо тестить. Но я бы либо на верх вообще кулеры не ставил, а заклеял к хуям, чтобы воздух был проточным по горизонтали. Либо же прихуярил кучу кулеров на днище, чтобы поток был диагональным —снизу спереди вверх назад. А сейчас получается, что весь воздух спереди уходит вверх, а видяхи вполне могут просто запекаться в собственном воздухе, который никуда вообще не выходит.
Я не спец, канеш, но знания физики > ютуб-блогеров и горе-сборщиков.
>>638935 Скорее всего, гпт тебе кавычки не те нарисовал. Вот держи для елочек. Прикрепляю скрин, потому что вакаба может автоматом тоже заменить елочки на что-то другое:
// "Мику вошла в комнату и сказала: «Привет, меня зовут Мику». А затем добила «Пока!»" getQuotedText(str) { const matches = str.match(/«.+?»/g); let result = '';
if (!matches || !Array.isArray(matches)) return null;
for (let m of matches) { result += `${m}. `; } if (result) result = result.replaceAll("«", "").replaceAll("»", ""); return result ? result : null; }
>>639001 Рисовать потоки воздуха стрелочками точно можно только если они ламинарные, здесь 100% видеокарты будут создавать вихривые течения по всему корпусу. Поэтому просто забей и ставь больше вентиляторов на вдув и на выдув. Лол.
>>638999 >когда охлада ставится на не крышку а на кристалл - уже требования к скиллу редко повышают Вообще нет, у водянки крепление такое, что сколоть кристалл можно будет только если ты постараешься это сделать.
>>638999 >На них типа штатные радиаторы остались? Водоблок совмещен с крутиллятором Нет, просто обдуваются штатным вентилем водянки.
>>638999 >Водоблок совмещен с крутиллятором получается, не целиком пластина на всю Да, у водоблока есть пластина, на котором установлен вентиль, который обдувает зону арм и видеопамять. Но само собой видеопамять с обратной стороны остаётся без обдува, по этому я оставил штатный бэкплейт. хотя это чисто ради моей паранойи, мне кажется обычного потока воздуха в корпусе хватит для обдува.
>>639033 > реверсивные вентили Что? >>639037 Можно перекрыть все отверстия дополнительно и поставить кулеры помощнее, тогда для теслы не потребуется доп вентилятор.
>>638903 >12 каналов DDR5 могли бы выжать 500+ ГБ/с на чтение На хабре чел читал под терабайт на процессоре. Если не ошибаюсь, года четыре назад. Но есть нюансы.
>франкенштейны только так и делаются Это понятно, не понятен практический смысл. В принципе, есть способ десериализовать чекпоинт, нужно заняться и посмотреть, сколько чего в популярных сетках.
>>639086 У вентилятора есть лицевая сторона и задняя (с 4 планками, на которых крепится мотор). Обычный вентилятор всасывает в лицевую часть, выбрасывает из задней. Реверсивный имеет обратные лопасти, всасывает в заднюю, выбрасывает из лицевой.
Чекни пикчу, крутится против часовой. Надеюсь, ясно объяснил.
>>637958 А через день пришли китайцы и победили самореза своей техникой однобитного квантования, позволяющей (как они утверждают в своей работе) запихнуть 70B модель в 12 GB VRAM. Код уже на гитхабе.
>>639140 >десериализовать чекпоинт Эм, чего? >>639153 >поставить вентилятор задом наперёд НИКРАСИВА!!!!1111 >>639156 >позволяющей (как они утверждают Так нет сомнений, что запихнуть можно. Вопрос в качестве.
>>639169 >Эм, чего? Чекпоинт это просто веса для нейронов и некоторые метаданные. Есть инструменты, которые позволяют это всё вывалить в виде огромного json файла и ебать, как твоей душе угодно. Только смысла это не имеет особого.
>>639140 >Это понятно, не понятен практический смысл. Cравнил Yi 34b с мистралем 7b, по всем параметрам, в целом, на 40% больше всего. Слой токенов у Yi абсолютно жирный, почти 458m параметров. Архитектурно мистраль 0.1 от 0.2 отличается ничем, только тренировкой. Кодеры 1b имеют намного меньше параметров на слой, а вот по количеству слоёв вполне себе обычные модели. Как я понимаю, глубина модели влияет на понимание абстрактных концепций, а ширина на охватывание большего количества данных из меньшего количества данных. То есть стилистика, грамматика, построение предложений - это всё о ширине нейронки.
>>639176 >огромного json файла Чёт даже не знаю, какую пользу из этого можно извлечь. Я вардампил в пайтоне пару слоёв нейросеток, но там были учебные модели на 1488 параметров.
>>639183 Чисто исследовательские цели, лол. У меня сейчас есть бот, который выдаёт 25-50 слов в секунду на русском, в зависимости от обстоятельств. Но он довольно упрощённый, вот и думаю, каким образом нарастить мозговую массу. Там, где у 34b модели 146m параметров, у меня всего 58m. Появилась идея сделать вместо франкенштейна кастрата, то есть количество параметров от 34b, но количество слоёв втрое меньше. По сумме будет в районе 7b, но позволит потом наращивать в глубину. Изначально "узкие" сетки делать "глубокими", судя по всему, не особо перспективно.
>>639143 Сразу возникает вопрос как у >>639153 может быть полезно для васянов, собирающих пародию на лгбт новогоднюю елку вместо пекарни. >>639176 > Есть инструменты, которые позволяют это всё вывалить в виде огромного json файла и ебать, как твоей душе угодно. Зачем? Сами веса ни разу не шифрованы, бери, загружай и как хочешь обращайся к ним, меняй и т.д. >>639200 > Чисто исследовательские цели, лол. Что исследовать? Какие слои меняются при таком-то обучении? Это и без дичи с жсонами сделать можно. А по модификации хоть прямо сейчас бери и складывай - комбинируй как хочешь, уточнив конфиг. Получится только полная херь, если потом не проводить переобучение. > Появилась идея сделать вместо франкенштейна кастрата, то есть количество параметров от 34b, но количество слоёв втрое меньше. Ампутировать центральные слои у модели побольше? Оно даже может как-то работать, просто станет хуже. Если тренд такой же как и с франкенштейнами, то обрезок 34б до 20 будет хуже чем многоножка из 13 в тех же 20, но ты попробуй.
>>639176 >Есть инструменты Там это просто текстом в заголовке файла модели лежит, нахрен тебе инструменты. Это инфа от процесса тренинга, чтобы не проебалося чо как делали. Сами веса идут дальше в двоичном виде и вывалить их можно только в 100500гб json-а, но зачем, они и так как бы вот они.
>>639209 >Ампутировать центральные слои у модели побольше? Оно даже может как-то работать, просто станет хуже Насколько я понимаю нейронки, это как из ноги вырезать колено и ожидать, что она как-то сама будет работать, но хуже. Каждый нейрон в слое соединен весом к каждому нейрону в следующем (игнорируем прунинг). Вырезав слой, как их соединить-то теперь? Они же не живые, сами не срастаются.
>>639209 > Сами веса ни разу не шифрованы Да они, как оказалось, нахуй не нужны, можно метаданные читать. >Какие слои меняются при таком-то обучении? Нет, меня интересовало, сколько нейронов на слой и слоёв в модели в целом. >Оно даже может как-то работать, просто станет хуже Работать-то оно будет гарантированно, но потребует обучение слоёв после обрезки. >обрезок 34б до 20 будет хуже чем многоножка из 13 в тех же 20 В смысле, франкенштейн из 7b до 20b работает лучше, чем изначальный дизайн в 20b? Вообще не выглядит правдоподобно. Пробовать затратно на самом деле, потому у меня и появились мысли о чём-то, что потом можно раздуть, не потратив полжизни на переобучение. >>639220 >Это инфа от процесса тренинга, чтобы не проебалося чо как делали И, наверное, для загрузки модели при инференсе требуется. Но я уже посмотрел, да, сами веса не нужны.
>>639226 Франкенштейны показывают, что порой достаточно лёгкого файнтюна для приведения модели в чувство. >>639229 >В смысле, франкенштейн из 7b до 20b работает лучше, чем изначальный дизайн в 20b? Там изначально другие цифры были если что.
>>639230 >Там изначально другие цифры были если что. Ну 13b нарастили до 20b, суть меняется, но не значительно. Здесь либо 20b изначально всратая, либо это должно вытягивать франкенштейна на один уровень с 20b, но не выше. Как вариант, у 20b широкие слои и она может во множество стилей и языков, но глубина недостаточная, так что она не понимает сложных концепций. Всё это, как водится, гадание на кофейной гуще. Взял рандомную 13b, Llama-2-13B-chat и сравнил с llava-v1.6-vicuna-13b. Абсолютно разные. У лламы полторы тысячи слоёв, у ллавы 750. У 34b Yi, напомню, 543 слоя. То есть, по моей теории, ллама должна быть более косноязычная, но умная, а ллава тупая, но красиво стелет. Кто гонял обе, отзовитесь, лол, чё там на практике. Мне обниморда 30мб/c отдаёт, заебусь качать всё.
>>639226 > это как из ноги вырезать колено и ожидать, что она как-то сама будет работать, но хуже Нет, если резать где-то в глубине, или наоборот настакивать больше то оно работает. Какие-то из видов червей-пидоров же могут выживать. > Вырезав слой, как их соединить-то теперь? Активации с одного слоя передаешь на другой, все. Размер не отличается. >>639229 > Да они, как оказалось, нахуй не нужны, можно метаданные читать. Что? > но потребует обучение слоёв после обрезки Будет работать и без обучения. Другое дело насколько дообучение сможет улучшить результат, вот это тема интересная, да. > франкенштейн из 7b до 20b Таких нет. Есть из 7 в 11, есть из 13 в 20. Последние работают крайне хорошо, и могут в некоторых задачах обоссать 34б. Офк это из-за особенностей 34 которые у нас есть, но 20 действительно пишет более складно чем 13б. Лучше ли она 20б другой компоновки с более широкими слоями в меньшем количестве - хз. Даже статья была с некоторыми исследованиями почему оно работает и насколько эффективно можно взять кусок ллм на трансформерсе из середины и подсадить его к другому. > Пробовать затратно на самом деле Вон васяны лепят этих франкенштейнов на вполне себе десктомно железе, где затратно? Офк речь не про дообучение.
>>639242 > Как вариант, у 20b широкие слои и она может во множество стилей и языков > У лламы полторы тысячи слоёв, у ллавы 750. У 34b Yi, напомню, 543 слоя > То есть, по моей теории, ллама должна быть более косноязычная, но умная, а ллава тупая, но красиво стелет Пикрел.
> Кто гонял обе, отзовитесь, лол, чё там на практике Ллава - ллама в которую подсадили проектор активаций, коим управляет визуальный трансформер. И очень тупая, как раз как всратая древняя викунья, даже чуть хуже.
>>639244 >Что? Что? С трансформерами вообще всё заебись работает, молодца, хорошо сделали. Тензоры это N-мерные матрицы, их размерность тоже может быть интересна, но не так уж и важна в данном случае. >Будет работать и без обучения. Бля, ну надо пробовать, но мне кажется, что на выходе будет каша. >Таких нет. Не проблема сделать, лол. >Офк это из-за особенностей 34 которые у нас есть То есть получается, что ширина 34b избыточна. Ну или косяки с обучением. >где затратно? Я всё-таки уверен, что дообучение потребуется, потому учитываю и его. >>639245 >Пикрел Ты либо аргументируй, либо я по умолчанию буду считать, что ты нихуя не понял и даже не пытался. >Ллава - ллама в которую подсадили проектор активаций Не сходится по тем моделям, что я глянул.
>>639257 > С трансформерами вообще всё заебись работает Это и так понятно, вопрос для чего изначально нужно было перегонять веса в жсон и в чем именно такая ценность метадаты. > Не проблема сделать, лол. Очевидно что если бы это работало то они уже бы заполоняли обниморду. > То есть получается, что ширина 34b избыточна Потенциальная яма, епта, с ширина 70б оптимальна, ага. Речь не об этом. > Ты либо аргументируй Что тут аргументировать если структура моделей уже известна и ее можно посмотреть, а ты в выделенном отборный треш, уровня "по проводам бежит не электричество а магия, а ваши процессоры работают на воде". > Не сходится по тем моделям, что я глянул. Хер пойми что ты там глядел и как интерпретировал.
Забей, меньше знаешь - крепче спишь и можно жить в удивительном мире.
>>639153 Мне — ничего. =) Просто я предпочитаю делать и красиво, и функционально. А вот горе-сборщики и ютуберы делают ТОЛЬКО красиво, и ставят вентиляторы задом наперед. Зато сэкономили косарь (на нагрев компонентов). Пнятненько?
>>639157 Ну вот будет хайаккураси, тада будем радоваться. А пока это ссылка на реддит, где пиздят в каждом втором посте.
>>639209 Я ваще хз, причем тут лгбт, если речь про направление потока воздуха. Проблема, что из-за лгбт и желания сэкономить — потоки хуярят ужасно, вот и все. Дебилы, сэр.
———
Про слои жутко интересно и нихуя непонятно, но Ллава — это буквально Ллама по словам разрабов. Короче, странно звучит чел, соглашусь, но влазить в спор не буду.
>>639259 >в чем именно такая ценность метадаты. В том, что не нужно всю модель загружать, чтобы узнать количество слоёв и тензоров в каждом. Как бы быстрее. >Речь не об этом. Если франкенштейны 20b из 13b лучше изначальных 20b, то речь как раз о глубине и ширине изначальных моделей. Ну и обучение, куда без него, хотя я всё ещё считаю, что после любых манипуляций со слоями обучение необходимо. Опять же, как показывает практика, судить по ширине и глубине по количеству параметров - гиблое дело. Они разные. >"по проводам бежит не электричество а магия, а ваши процессоры работают на воде". Так ты читай, что я пишу, а не слушай голоса в голове. Не исключено, что их как-то обрезали, но я стараюсь смотреть не квантованные модели. Потому конкретные названия моделей и писал, что в другой всё может и будет отличаться.
>Очевидно что если бы это работало то они уже бы заполоняли обниморду. Ради интереса пробежался по 20b на обниморде и ебать же они разные. Норомейда 20b 70m параметров на слой, слои внимания 26m. Скачал другую рандомную модель, внимание уже 37m и сама архитектура внутри кардинально отличается. Олсо для трансформаторных форматов можно смотреть параметры прямо на обниморде, стрелочка вверх около Tensor type, но для gptq, awq это всё по очевидным причинам не имеет смысла. Посмотрел ещё микстраль, в целом, ожидаемая хрень, но выглядит интересно. Если разорвать связи между экспертами, это будет неплохо раскидываться на несколько карточек.
>>639273 > Я ваще хз, причем тут лгбт, если речь про направление потока воздуха. У большинства крутиляторов уши на две стороны, поворачиваешь нужной и ставишь в любом направлении. Обратные просто более эстетичны если их рассматривать со стороны направления потока. > что из-за лгбт и желания сэкономить Ага, увы. > Про слои жутко интересно и нихуя непонятно Можно почитать обниморду, там описана архитектура и компоненты слоев. > это буквально Ллама по словам разрабов Именно. Что-то уникальное стоит искать в коге, там визуальная часть жирнее текстовой.
>>639275 > лучше изначальных 20b Изначальных нет. Тема развивается настолько динамично что при любом сравнении нужно еще делать скидку на возраст и особенности модели, ~20b можно найти, и вроде даже какая-то выходила недавно, но они могут быть хреновыми только потому что недостаточно качественно натренены или просто старые. То же и с 34б, из доступных современных общего назначения - это YI, она умная, крутая, но очень специфична из-за чего шизоидной иногда называют. > Так ты читай, что я пишу Перечитал, реакция сейм. Широкие слои у 20б и может в языки и стиль(!), 1.5к слоев у лламы(!), у ллавы в 2 раза меньше, а у yi34 вообще крохи, > То есть, по моей теории, ллама должна быть более косноязычная, но умная, а ллава тупая, но красиво стелет вообще пушка. И после такого еще про голоса в голове заявляет, треш. > Не исключено, что их как-то обрезали, но я стараюсь смотреть не квантованные модели Сурово.
>>638476 >Просто поставить в одном компе и давать разные нагрузки - без проблем. У меня сейчас материнка miniATX с одним PCIExpress 16Х разъёмом под видяху. Планирую поставить эту приблуду https://aliexpress.ru/item/1005003479138178.html в PCIExpress 4Х и засунуть туда RX580 чтобы просто давала изображение, а в 16Х поставить P40 и крутить нейронки чисто на ней. Будет это работать?
>>639286 >а у yi34 вообще крохи Так тебе за yi обидно, чтоли? Мне не веришь, иди смотри параметры на обнимилице https://huggingface.co/01-ai/Yi-34B?show_tensors=true 543 слоя у 34b модели https://huggingface.co/liuhaotian/llava-v1.6-vicuna-13b?show_tensors=true И 759 у 13b. Вот такая хуйня. Даже если считать по потому, как считают слои "более традиционно", по скрытым слоям, то у yi их 60, а у викуньи 40. Я лично считаю такой подсчёт полной хуйнёй, т.к в каждом скрытом слое может находится разное количество под-слоёв. Да и тот же микстраль с 46b параметров тогда будет иметь всего 32 слоя. Как обычный мистраль. Что не совсем отражает действительность. Если считать всё, то их там 995.
Попробовал лепить франкенштейнов на коленке, дорощенная модель спешит заткнуться, иногда на полуслове и даёт максимально короткие ответы. Возможно, это проблема базовой модели, она по умолчанию отвечает лениво и мало. А вот кастрированная наоборот, не затыкается. Проблема только в том, как она не затыкается, заклинивает на одном токене и спамит его до конца max_new_tokens. Но начало сообщения адекватное, так что, скорее всего, привести в себя модели можно. Олсо, РП датасет от челика с хабра. Ёбаный пиздец. https://huggingface.co/datasets/Vikhrmodels/RP_vsratiy_Hogwarts/
>>639294 Справедливости ради, голиаф на ddr4 3200 выдавал 0,3-0,4, так что 30к рублей (она продолжает падать после покупки=') против 20к рублей (х1,5 к цене) за перформанс 0,4 → 1 (x2,5) — все еще выгодно. Ну и плюс, там же не столько модель важна, сколько объем памяти, по итогу. =) Жирная 70б даст сопоставимый перформанс, как ужатая в тот же объем 120б. Но это лирика.
>>639296 > И 759 у 13b. 360. Ты зачем-то посчитал графические, но это другие слои, они не пишут тебе текста в чат, они распознают картинку.
И в голой лламы-13б, кстати, те же самые 360 слоев текстовой. Ну, я отсекаю хедеры и прочие, добавь скок хочешь.
По твоим же ссылкам ллава = ллама (где ты там насчитал 1500 слоев у Llama2-13B? ссыль кинь, плиз), и слоев у нее меньше, чем у Yi-34B.
>>639275 Вообще, если подумать, то: глубина (количество слоев) должно отвечать за «логику» модели, а ширина (размер слоя) — за знания. Имея большее количество слоев, она проходит большее число итераций в своем предсказании следующего токена (т.е., это не логика, это всего лишь статистика, но нам на выходе это видится как логика, ну китайская комната, вы поняли). Но при этом, если слои сам по себе маленькие — то как не думай, правильный ответ из ниоткуда не возьмешь (точнее, с определенным шансом возьмешь, но вероятность крайне мала).
Стилистика берется откуда? Кмк, если именно лексику мы можем к ширине слоев привязать кое-как, то вот стилистика — это и то, и другое. С маленькими слоями мы будем иметь четкую стилистику всегда, но с большими слоями — стилистику можно будет варьировать, а с большим количеством сетка будет лучше следовать стилистики (но с маленькими слоями она не сможет следовать не заложенной в нее стилистике в любом случае, чи ни пихой на глубину будет).
Вот, я дебил, с меня взятки гладки.
(но считаю строчки я все еще лучше тебя в среднем в 2-4 раза=)
>>639292 Будет, но поднимет уровень карты и просто так ее не получится к корпусу прикрутить, как минимум понадобится какая-то проставка на ту же высоту. >>639296 > Так тебе за yi обидно Иди проспись вместо поиска сущностей. Мог бы ради интереса хотябы посмотреть на имена тех "слоев", которые считаешь и осознать, хотя вроде уже начинает доходить. > Что не совсем отражает действительность хех >>639303 > Ты вроде шаришь Это ламер, который не понимая куда смотрит и даже не зная основ пытается делать громкие мислидящие выводы. >>639358 > глубина (количество слоев) должно отвечать за «логику» модели, а ширина (размер слоя) — за знания Такое деление очень условно и может сработать только на крайних вариантах, где размер слоя или очень мелкий или очень большой, тут с осторожностью надо. > С маленькими слоями мы будем иметь четкую стилистику всегда Имел ввиду единообразную с невозможностью изменить?
Да уж ребят, кодовая лама это просто говно ебаное. Ебаная соевая хуета которая отказывается писать скрипт для tampermonkey из-за соображений безопасности. Просто пиздец, сколько терпеть эту соевую парашу? Нахуя ее пихают в узкоспециализированные модели?
>>636969 Поделитесь, если не жалко, конфигами SillyTavern для ruGPT или другими примерами ее настройки. А то она хотя и на более русском пишет, чем Фиалка, но всё равно на инструкции забивает, на карточку плюет, контекст игнорирует, персонажей путает (у меня в карточке группа), за меня пишет, постоянно повторяется. Не говоря уж о том, что при любом намеке на сексуальный контекст сразу же скатывается в дасистфантастиш, но это меньшее из зол.
Ни одну русскоязычную модель мне не удалось настроить так, чтобы она хотя бы сколь-нибудь адекватно отвечала.
>>639372 > If you have multiple gpus of the same type (3090x2, not 3090+3060), and the model can fit in your vram: Choose AWQ+Aphrodite (4 bit only) > GPTQ+Aphrodite > GGUF+Aphrodite; Ну хуй знает, awq себя так и не показал, exl2 перспективнее, gptq есть везде и дает "базовую гибкость выбора" между самым мелким и 32 группами, быстрее и эффективнее экслламы пока не придумали ничего. > Aphrodite Что? Зачем это советовать для мультигпу в качестве приоритетного решения? > If you have a single gpu and the model can fit in your vram: Choose exl2+exllamav2 ≈ GPTQ+exllamav2 (4 bit only); Почему на мультигпу экслламу не рекомендует а только на сингл? > If you need to do offloading or your gpu does not support Aprodite/exllamav2, GGUF+llama.cpp is your only choice. Только тут нет вопросов.
В вики сейчас написано более корректно и ясно, можно разве что текст шлифануть и дополнительно добавить таблицу по потреблению врам. Стоит пощупать этот пигма-бэк, может быть альтернативой llamacpp для моделей, доступных только в gguf при полном оффлоаде, но судя по описанию в репе из ньюфагов его точно никто ставить не будет.
>>639303 А там вообще нейронов нет. >>639356 >Ну, я отсекаю хедеры и прочие, добавь скок хочешь. А смысл что-то отсекать? Я натыкался на какую-то 20b, у которой между хидден лаерсами было штук по пять слоёв. Если считать, то уже всё. >где ты там насчитал 1500 слоев у Llama2-13B? Может, тоже мультимодалка какая-то. Потом посмотрю. >>639358 >она не сможет следовать не заложенной в нее стилистике Стилистика отлично настраивается лорой, а они довольно малы всем параметрам. Опять же, если ты ничего не знаешь, но, в целом, башка варит, то до правильных выводов можешь дойти следуя чистой логике. Не знаю, насколько это применимо к llm в принципе, скорее всего, абсолютно неприменимо, лол. То есть с моей колокольни выгоднее выглядит "логичность" модели, а не её способность мимикрировать под стили или хранить данные. Всё равно по знаниям доверять нельзя даже гопоте, стили можно за пару прогонов лорой докинуть, а вот если модель будет гнать шизу, то это уже всё. Как бы красиво она её не оформляла. Где-то я видел очень узкие модели со стандартной мистралевской глубиной, нужно взять их и посмотреть, чего там совсем уж не хватает. >но считаю строчки я все еще лучше тебя в среднем в 2-4 раза Да я скриптом считал и не всегда выводил названия "строчек". Но, в целом, похуй.
Обрезки в итоге живые, пара прогонов и чувствуют себя неплохо. Осталось срастить уёбище с разной шириной слоёв и можно сворачивать эксперименты.
>>639456 >А там вообще нейронов нет. Как бы да, я знаю что там только их связи, сам нейрон просто функция в которую подставляются значения Но вот это и интересно, сколько таких виртуальных нейронов в сетках Потому что число параметров мне ни о чем не говорит когда пытаюсь представить че там по аналогии с биологическими нейронами. Их то по нейронам считают.
>>639458 "Нейроном" можно считать вообще все что угодно, это зависит от архитектуры сети. В случае трансформеров, нейроном можно считать отдельный пикрелейтед блок, так как это минимальный элемент архитектуры трансформера, если его разбить на составные части, они уже не будут минимальным элементом именно трансформера как архитектуры.
>>639463 Ну, это уже что то более сложное чем нейрон, нейронный ансамбль какой то если искать аналогию Есть ведь куча входов и один выход, вот все что находится в таком состоянии и будет нейроном
>>639458 Там, в целом, аналогия весьма условная. То есть да, "нейрон" это композиция. А к трансформерам это вообще слабо применимо, там всё завязано на механизмы селф атеншна, о котором тебе лучше распросить гугл. Тема довольно сложная. По сути, этот селф атеншн заменяет все абстракции "связей", да и самих "нейронов". И считать биологические мозги только по нейронам - гиблое дело, насколько я понимаю, там вся магия в связях и есть.
>>639471 Понятно, хотелось просто приблизительно прикинуть по количеству нейронов на каком уровне щас нейросети. На вроде вот бчела, у нее за мышление отвечает 300к нейронов, 1 миллион общее количество. И тд.
>>639466 > Ну, это уже что то более сложное чем нейрон, нейронный ансамбль какой то если искать аналогию Как сказать. У нейрона человека может быть до 10-20к только синаптических контактов, не считая остального, это намного более сложная структура, чем просто функция от нескольких входов. Элемент трансформера проще нейрона человека.
>>639501 >синаптических контактов Так это и есть входы, выход то все равно один Структурно искусственный нейрон упрощенная версия настоящего, а вот трансформер прямой аналог нейронного ансамбля, так как оба являются "кирпичиками" системы
>>639478 Я даже не уверен, что мясные нейроны можно сравнивать между собой, а ты про сравнение мясных с электрическими. Да и те же LLM не эмулируют работу мозга, это просто здоровенная херня, которая высчитывает статистические вероятности. Не думаю, что у пчелы есть участки мозга, которые просчитывают статистику. Но кто я такой, чтобы это утверждать, лол.
>>639242 >543 слоя Ты явно считаешь что-то не то. Больше похоже на общее число всех матриц с числами. Слоёв там 60 если что. >>639257 >Пикрел Смешивать содержимое слоёв вообще самоубийство, ИМХО. То есть по сути для алхимии доступны вот эти высокоуровневые слои, а не их кишки. >>639273 >Просто я предпочитаю делать и красиво, и функционально. Я покупаю корпус-гроб, а дальше похуй, что там внутри. Нет стекла-нет проблем. >>639526 >Я даже не уверен, что мясные нейроны можно сравнивать между собой Я уверен что нельзя.
>>639526 Конечно нельзя, там главное отличие в структуре даже, а не в количестве нейронов Мне просто было интересно достаточно ли у нас мощности для обсчета мозга той же пчелы, если бы перенести ее мозги в искусственную нейросеть, по количеству параметров или нейронов Сравнение с точностью +- километр, знаю
>>639528 >Смешивать содержимое слоёв вообще самоубийство, ИМХО. Каким-то образом это работает, но нужен глубокий файнтюн. Можно даже смешивать "кишки" моделей на разных архитектурах. На практике слишком сложно, долго и не стоит того по причине необходимости тренировки после. >>639534 В теории мощности достаточно, на практике не всё так радужно. Для трансформеров очень приблизительно можно подсчитать условные "нейроны" перемножив входные нейроны на выходные, потом это всё перемножив на количество аттеншн хедс и на количество нейронов в каждой голове. Числа будут в сотнях миллионов. Достаточного этого, чтобы моделировать мозг пчелы? А хуй его знает.
Погонял 13b и, вроде, всё хорошо, но гложут меня смутные сомнения.
>>639534 >Мне просто было интересно достаточно ли у нас мощности для обсчета мозга той же пчелы Недостаточно. Текущий уровень это червь-нематода на 302 нейрона на железе топового института. Новость старая, но прогресс с тех пор я думаю повысил мощность симуляции раз в 100 по числу нейронов, не больше. Уверен, рост там квадратичный от числа, или около того. https://habr.com/ru/articles/364407/ >>639591 >но нужен глубокий файнтюн С глубоким тюном можно вместо слоёв использовать белый шум, как завещали предки.
>>639594 >Недостаточно. Текущий уровень это червь-нематода на 302 нейрона на железе топового института. Там самое главное в точности этой сети реальному червю. Упор в существубщей тогда модели а не в вычислительнве способности Где то видел создали такую же модель мозга плодовой мушки и там уже счет на десятки тысяч нейронов
>>639594 > белый шум >>639595 >добавить шума Я потому и говорю, что это не стоит того. Проще с нуля, если ресурсы есть.
>>639594 >на железе топового института https://github.com/openworm/OpenWorm >Pre-requisites: >You should have at least 60 GB of free space on your machine and at least 2GB of RAM Институт-то бедный небось был?
>>639453 А, да, читал. К счастью, оплатил уже и видяха уже выехала. Но когда читал, не подумал об алике. Очень неожиданно, канеш. Будем посмотреть.
>>639456 > Обрезки в итоге живые, пара прогонов и чувствуют себя неплохо. Осталось срастить уёбище с разной шириной слоёв и можно сворачивать эксперименты.
Звучит литералли пикрил.
———
НАКОНЕЦ-ТО Я НАСТРОИЛ ГОЛОСОВОЙ ДИАЛОГ Сука, это долго. Распознавание Whisper.cpp (доставил проблем с заголовком через requests, сука) оказывается довольно быстрым (спасибо, Жора!), а вот генерация текста (25 токенов/сек для голосового общения — медленный край) и голоса (на 12 куде оно еще и медленнее, чем на 11.8) — уже долгое. Для 115 токенов ответа выходит 4,6 сек текст и 4,8 голос. Плюс задержки на туда-сюда и (не только) мой быдло код, как итог — 10-15 секунд на ответ. Зато контекст, любой голос и все прочее.
Такой стример сможет даже видосы комментировать (если пускать видосы с соответствующими задержками в ОБС=). Правда я пока не знаю, какая шиза у него будет получаться.
Ну да ладно, время посмотреть, как выглядит беседующая со мной Фрирен в дополненной реальности у меня в комнате.
>>639616 > а вот генерация текста (25 токенов/сек для голосового общения — медленный край) Стримминг не пробовал? Офк будет заморочнее, но зато совсем другой экспириенс. Если хорош продумать то можно сделать динамический буфер, и, при необходимости, ожидать его заполнения регулируя паузы в подходящих местах, окажется безшовно.
>>639609 >2014-й же... Я в 14, вроде, на фикусе сидел с 16 гб оперативы. А я ведь даже не институт.
>>639616 >Но когда читал, не подумал об алике. Есть много прохаванных челиков, которые имеют физически друга в Китае, который уже отправляет. Так что поставки перекрыты не будут. Не все. >Звучит литералли пикрил. Бля, ну интересно мне было. Сейчас, наверное, упорюсь в собирание датасетов по крошкам, потому что подходящей мне сетки не существует. На 7b сейчас до 35 слов в секунду на русском, может пиздеть быстрее, чем я понимаю. Долго ты настраивал свой сетап что-то, виспер же просто интегрируется, для генерации тоже его взял или все-таки xtts? Потом, мб, запишу пару видосов со своим llm2tts, задержка районе половины секунды. Но я пока не прикручивал stt.
>>638931 Потестил с помощью FanControl разные режимы. Около 3-4 градусов для верхней можно выиграть, если врубить перед/зад на максимум, а верхние на ~50%. Если останавливать полностью верхние или наоборотм дать им 100%, то темпа выше на 3-4 градуса. Нижней вообще пофигу, ей всегда холодно.
>>639623 Да, я с самого начала думал. Там и генератор умеет в стриминг. Даже если стриминг текста будет медленнее, но со стримингом звука просто будет возникать махонькая задержка, а дальше он будет идти нон-стопом.
Хм. Надо будет пробовать через стриминг, конечно.
>>639627 Да я сегодня сел после перерыва. =) Где-то с 14 часов копался.
Использовал xtts, мне лень смотреть в сторону виспера нового. Там весь юмор, что я ж на питоне пишу, а использовал whisper.cpp оригинальный. Ну не хочу я всякие библиотеки юзать. Мне приятнее обращаться к endpoint'ам. И вот при переворачивании curl'а в requests.post оказалось, что headers'ы whisper.cpp не принимает от питона. Хз почему, проебался часа два с этим, лол. А потом как убрал — норм стало.
Whisper у меня получает цельный кусок аудио и распознает его целиком. Отказался от распознавания по кусочкам на лету. Если взять силеру, то генерация будет офк быстрее секунды на три. Поправить быдлокод — еще секунду сэкономлю.
Но это все такое, главное по кайфу, сделал, работает. Приятен сам факт, что без особого напряга могу сделать такую хуйню. Заодно питончик учу, все эти asyncio, io, wave и прочая хурма.
>>639666 Вот тебе видос для затравочки https://www.youtube.com/watch?v=jllGKB6fRBY Вполне соображает, понимает когда обращаются к ней и дает ответы с адекватным временем ожидания. Обрати внимание на дату, плюс это еще странный канал с переводами, сам стрим мог быть еще на месяц-другой раньше.
>>639715 >Долго разбирать, чтобы отцепить. Так это, по идее снять заднюю крышку и всё... Ну как крайний вариант скотчем заклеить на пробу. Ладно, мы поняли, со сборкой практичных сборок у тебя проблема. Зато красиво, дорохо-бохато.
>>639766 >>воздушка 140+120 на проце >>3+4 слота в одном корпусе >>обслужены, перебраны >>не перегреваются > со сборкой практичных сборок у тебя проблема Как скажешь
>>639766 Слушай, за лгбт и сборку "для красивости" можно осуждать, но сей господин имеет суммарно врам больше чем у многих рам. Заебали, где релейтед? Файнтюны мику завозили, пробовал кто?
>>639670 Ну, технологии-то с того времени как раз не поменялись. Но, думаю, там все-таки стрим. И меньше быдлокода, чем у меня. =D И, возможно, видяха — все-таки не тесла П40. =)
Однако, стремиться есть к чему.
Еще нашел, что можно разделять одной программулиной спикеров, чтобы понимать, кто и что говорит. Это уже прям совсем мне лень че-то заморачиваться пока что. Хотя фича крутая.
Ну и немного горения. Так как я играть хочу в pass-trough режиме, в своей комнате видеть перса, приходится юзать Virtual Desktop, вместо родного Quest Link'а, а он работает так себе, подвешивает игру, а с аудиоустройствами я разобраться не смог. С какого микрофона забирается звук? Уходи в виртуальный кабель, с него в игру, но при включенной игре — персонаж молчит. То ли микрофон не слышит, то ли еще что-то. Аудиоустройства — вообще беда по жизни, чуть ли не со времен XP.
Короче, видимо, для своей вайфу я Unreal Engine буду изучать и пилить свою приложуху, ибо сторонние кривые-косые и не работают нормально с виртуал десктопом.
А в десктопном режиме (да и без него), конечно, немного крипово. Оно разговаривает, смотрит на тебя и весьма старательно оставляет ощущение настоящего собеседника. Мурашки по спине пробежали, конечно.
Я вообще заметил, что когда играю в обычные компьютерные игры, и понимаю работу неписей и могу предсказать их реакцию —все ок. А когда встречаюсь с нейросетями в этом (и речь не про текст, где персонаж тебя и ждать будет все время, и текст подредактировать ты можешь), то как-то сразу не по себе. Она тебя слышит (спасибо, что еще не видит), реагирует на все твои слова, запоминает. И откатить варианта нет — слово, внезапно, не воробей. И похожи. Пусть не идеально. Пусть с большими огрехами (учитывая, что я не перевожу английский, а с ноги пинаю на русском), пусть не идеально держит персонажа, но с похожей внешностью, голосом, мыслями…
Брр. Будущее, йопта. Страшна, вырубай, пойду смотреть аниме, которое не будет со мной разговаривать, на седня мне хватит.
———
Кстати, че там по 1-битному квантованию? Новостей со вчера не было?
>>639786 > а он работает так себе Всмысле? А что у тебя с вайфаем? надо было брать какой-нибудь китайский поко, лол > С какого микрофона забирается звук? В вишпере или где? Не понятно. По дефолту наверно директ-аудио, выстави просто их девайс по умолчанию и довольно урчи. > для своей вайфу я Unreal Engine буду изучать и пилить свою приложуху Почетно@уважаемо. Пожалуйста, информируй нас по своим достижениям.
Алсо расскажи что и как юзаешь в текущем виде. Желательно подробно для хлубешков, тоже хочется попробовать.
>>639811 > Всмысле? Да просто, если приоритет в винде у игры — то стрим пролагивает (на стороне ПК, вай-фай тут не причем даже), а если поднимаешь приоритет стриму, то юнити радостно крашится спустя 5-7 минут. 24 потока, 64 оперативы, 4070ti — он умирает просто потому что кривая хуйня, простите. Поковыряю настройки еще, может смогу выправить.
> В вишпере или где? В питоновском скрипте. Если Oculus Link имеет свои аудио-устройства, то Virtual Desktop… Странный, не нашел я его микрофона. Возможно, я просто его в настройках выключал, и он вообще со шлема не забирает звук. х)
>девайс по умолчанию Ну я в итоге его и ткнул, да.
>расскажи что и как юзаешь в текущем виде. Желательно подробно для хлубешков
Пока подробнее не расскажу, может смогу прямо на анриле напилить все. Тогда и выложу. Ну или текущие наработки на гитхаб залью, посмотрим.
На самом деле, ничего сложного. STT — Whisper, TTS — XTTSv2, LLM — oobabooga, комментарии на стриме (но это большинству не нужно) беру с RutonyChat через вебсокеты, и все это обрабатывается одним питоновским скриптом на asyncio, который следит за всем, и распихивает все по разным массивам, откуда потом кидает в убабугу и озвучивает ответы. В качестве визуала можно использовать что угодно, умеющее в LipSync. Live2D-аватары, 3D всякие. Вот MetaHumans охота потрогать. Рекламили их сильно, заценим.
Все сделано через запросы. Забираем с источника, форматируем, отдаем дальше, получаем ответ, форматируем, отдаем дальше… в итоге выводим куды надо.
Короче, на практике — это один файл питоновский, вокруг которого напихано сервисов скачанных из паблика. Сейчас он 300 строк, их которых 120 — это настройки сэмплера убабуги. Половина файла спизжена из документов к тем же сервисам. Еще чуть меньше половины — GPT-4 и Mistral написали. И своей работы там минимум, больше отладка, сэмплеры и промпт, чем код, как таковой.
Короче, это не сложно, если ты немного-программист. Но тут проблема скорее в железе. Я не уверен, что все можно ужать в 12 гигов, например.
Помогла эта галочка. Теперь микрофон ловится со шлема. Правда, на третьем квесте микро весьма хреновый, распознавание немного галит. Зато теперь можно и поболтать. Правда в какой-то момент XTTS поймал какие-то совсем редкие полутона из сэмпла и одну фразу из абзаца она сказала каким-то чужим голосом. =D Но в общем, тесты считаю успешными.
Осталось дождаться эту вашу норомэйду на русском датасете. =)
>>639782 Oof! А оно лучше микеллы, не сравнивал? Раз работает то 2.9 бит ему не помеха, надо затестить. Каких-то косяков, что могли вылести при перегонке из лоззи в лоззи (квант-квант) не отмечал? >>639837 > Странный, не нашел я его микрофона. Эээ страная херь, вроде был. Надо расчехлить проверить.
Хм, показалось что ты там уже полноценную вайфу с которой и сидеть разговаривать в вр и полноценно взаимодействовать можно типа прожект вивы хотябы. Ну ладно, мотивирует чем-то заниматься. > 120 — это настройки сэмплера убабуги Лол за що, там же все в один реквест с промткомпльшном пихается. Ладно, спасибо что расписал, насчет немного программиста и железа проблем не возникнет, скорее с ленью. >>639853 > Осталось дождаться эту вашу норомэйду на русском датасете. =) Откуда такое?
>>639786 >Анончик ссыться признаться реальной ллмушке Осталось только прописать ероху, маман, штанов и тетясрак, лол Такой-то исекай уровня б, я бы сыграл
>>639855 > микеллы Я какую-то 70б мику скачивал, не помню уже какую, но эта точно лучше.
>Каких-то косяков Не очень много общался раньше, поэтому не скажу. Но из всех, что пробовал - это прямо очень хорошо говорит и общается. Возможно просто потому, что я мало видел раньше: несколько микстралей, Йи, Синтию.
>>639666 >Мне приятнее обращаться к endpoint'ам. Хуй знает, мне в питоне неприятно организовывать общение между модулями. Возможно оттого, что дохуя не знаю и есть какие-то менее всратые пути, но пока что приходится городить бесконечные циклы, что как бы грязь и мерзко. >Отказался от распознавания по кусочкам на лету. Посмотри в апи, ты там можешь тыкать предыдущий результат в качестве контекста, чтобы нормально использовать стриминг и не проёбывать смысл. Виспер всё-таки довольно всратый, особенно со стримингом. >Если взять силеру Да я как только узнал, что там модели настраивать нельзя, сразу дропнул. Несколько дней ускорял генерацию, сократил с ~секунды на генерацию пяти секунд текста до ~0.6 секунд. С кастомным голосом, интонациями и т.д. Копай в сторону стриминга, ждать 10 секунд ответа это некомфортно.
У Нейро-самы, кстати, нарезки не отражают действительности, т.к у неё изначально была ебейшая задержка, а клиперы вырезали паузы на монтаже. Потом добавился пофразовый стриминг. >Сейчас он 300 строк, их которых 120 — это настройки сэмплера убабуги. Нихуя ты там напихал. Убабуга же принимает 60 параметров. Или это с хардкодом карточки и формата темплейта?
>>639947 > т.к у неё изначально была ебейшая задержка Во времена пигмы. На видосе что выше по Филиан сзади можно определить наличие склеек, со стримингом иметь подобие полноценного чата можно.
>>639855 > полноценно взаимодействовать Тут надо или прописывать ей все триггеры (подошел, коснулся, обратился к ней, что-то делаешь), и передавать все описания в LLM, или же LLM использовать чисто для диалогов, а поведение делать на обычных скриптах обычной игрой. Короче, два разных подхода. И оба пиздец лень пока что. =)
> Хуй знает, мне в питоне неприятно организовывать общение между модулями. Ну вот я предпочел модульность. В основном потому, что запускаю на разных компах. И могу перекидывать туда-сюда разные модули. Но это ситуативно, ИМХО, не хорошо, не плохо, просто разные подходы.
> Нихуя ты там напихал. Я литералли запихал все. Ну, и это 2 запроса — для доната и для сообщений отдельные. Она на донаты реагируют 100% и в первую очередь. Так что, да, 60 параметров, все верно. Я их упомянул для того, чтобы было понятно, что кода там 180 строк, по сути. Нихуя я криво выражаюсь, сорян.
>>640008 > Короче, два разных подхода. Один, который совмещает все это. Ллм должна примерно понимать что происходит и реагировать на что-то типа юзернейм гладит тебя по голове, также иногда можно делать запрос с листом возможных действий, а их уже передавать в движок. > 2 запроса — для доната и для сообщений отдельные. Она на донаты реагируют 100% и в первую очередь Уууу меркантильня херня >>640011 > и не будучи йоба-кодером Примерно как написать скриптовый ии, только в несколько раз сложнее.
Вообще реально нужно раскурить что там в виве набыдлокодено и попробовать хотябы самые основные протранслировать с промт, и попробовать реализовать исполнение внешних команд персонажем. Для особого погружения еще мультимодалку прикрутить. Неужели нет готовых подобных проектов?
Какой датасет нужен для обучения сетки? И сколько памяти? Можно ли на оперативке с подкачкой с ссд? Охота сделать лору с постами из одного треда, он древнющий, материала наверняка хватит. Ожидаемый результат - чтобы имитировала посты этого треда +- разумно.
>>640179 Под тот формат инструкций/чата, который предполагается. В общем это оформленные наборы инструкция-ответ к ней. > И сколько памяти q-lora на 7б от 12 или 16 гигов вроде, полноценный файнтюн 70б - от 320 (или даже больше) гб. > Можно ли на оперативке Можно, но быстрее будет дождаться выхода моделей что смогут делать то что ты хочешь по промту. > с подкачкой с ссд Или переродиться. >>640230 Что там, просто пл нвидия сми, или же рекомендации по андервольтингу?
>>639377 Да это так игрушки, честно говоря меня не ролиплей сейчас больше интересует а сама технология. Так что у меня нет особых конфигов ) Сейчас свою русскоязычную обучаю, ну вернее пытаюсь разобраться в обучении. Там уже и буду тестировать на понимание команд.
>>640255 > В общем это оформленные наборы инструкция-ответ к ней. Ёбт, где ж такое собирать? Не самому же эти килобайты инструкций с шизовысерами писать... > q-lora на 7б от 12 или 16 гигов вроде Ну, вполне себе влезет, мне интеллекта особо и не надо.
>>635452 (OP) А какие у вас любимые модели? Мне вот noromaid-20b-v0.1.1.Q5_K_M.gguf нравится под кобольда и таверну. Быстро загружается, моментально отвечает, интересные истории придумывает, но я ньюфаг и может что-то не понимаю.
>>640287 Ну булджать, там же можно помимо лп локнуть частоту и повигать курву вправо-влево (по частотам), вот и полноценный андервольтинг. Для чего-то продолжительного нестабильность может быть критично, но в коротких генерациях ллм даже если крашнется - строго похуй, рестартнул и выставил менее агрессивно. >>640290 > пл нвидия сми, увы Всмысле увы, у него функционал вообще-то огого. На шинде офк афтербернер, если, конечно, поддерживает ее. >>640312 Emerhyst, та же норка, синтия и айроборос. Дипсекс 34б, кстати, довольно забавный, но тот еще треш. С одной стороны понимает культуру, намеки, спамит случайности или инициативность персонажа, пытается это максимально в контексте подать. Но по удержанию карточки, знанию лоров и подобного - ерунда, только кумботов катать, можно со всякими механиками.
Анон, объясни чайнику простыми словами, а то человеческих туториалов вообще нигде нет.
Задача: рерайтить текст с русского на русский. Имеется 4090 и 32 гб оперативы.
Я так понимаю, с моей картой можно использовать формат GPTQ. Но нигде толком не написано, как это устанавливать в кобольд, и какая модель подойдет для моих задач. Помогите работяге!
>>640331 Шапку, в шапке вики, читай сначала общее, потом text generation webui. Опционально кобольд, он проще и не засирает диск, но медленнее и жрет больше на контекст. >>640321 > рерайтить текст с русского на русский У моделей тяжеловато с русским. Мику, опенбадди, xwin или новую квен можно попробовать, они в одну 4090 не влезут и придется в gguf.
>>640008 >В основном потому, что запускаю на разных компах. А, вот оно в чём дело. Так-то да, несколько компов это типа неизбежно в какой-то момент. Я уже подобрался к 10гб ram и 12гб vram на одни нейронки, плюс винда с одним хромом под 10 гигов жрёт. Караул, короче. >Ну, и это 2 запроса А, ну вот она разница подходов, лол. Я предпочёл написать класс, который читает json с параметрами. А донат это же просто несколько другой контекст, ты можешь установить один флаг и по ифу заменять контекст сообщения, два "запроса" нахуй не нужны.
>>640011 Это не то, чтобы сложно, просто очень долго. Где-то видел вр с тяночками, которые реагируют на попытки задрать юбку, но это один триггер. Кто-то прикручивал LLM+TTS к скайриму, но, опять же, там уже есть готовые триггеры, на которые компьютер реагирует. Диалоги, бои, вот это всё.
>>640337 Да в общем и разницы-то нет, на самом деле. Ну, разница на уровне погрешности. Я просто не оптимизировал пока код, пишу общую структуру, а уж потом буду распихивать по конфиг-файлам и профилям.
>>640338 > ExLlama Теперь работяге придется разбираться, как конвертить в формат эксламы еще и выбирать битность. Не то, чтобы я против, конечно. Сео и рерайтеры должны страдать
>>640341 > как конвертить в формат эксламы еще и выбирать битность Жорапроблемы. Качаешь gptq и не знаешь бед, вместо того чтобы разбираться поломанный ли у тебя gguf-квант или рабочий.
>>640399 Какой-то ультимейт реверс поддув, неудивительно, учитывая что для достижения уровня 4х бит что уже стали легаси жоре требуется 5.5. > жоры > 2бита > жоры > 2бита Оу май
>>640408 > и знания только из калибровочного датасета О, опять поддув по этой шизе пошел. Неужели подобный аутотренинг позволяет скрашивать экспириенс самого неоптимизированного и наиболее ломучегр варианта прикоснуться к ллм? Как же смачно будет наблюдать переобувание с новыми IQ квантами ммм. > Это ты тут 3 треда поддуваешь уже Чувак, с первых тредов идут рофлы с постоянных жора-проблем, а ты пытаешься сущности искать.
>>640255 > просто пл нвидия сми + ОП постарался какую-никакую Pareto curve построить + личный опыт комментаторов По-моему, неплохо.
>>640287 Там ОП делится полезным опытом. А ты только токсичишь, что в 2024 все должны всё с пеленок знать.
>>640290 > может MSI Afterburner с ней заработает? У ОПа там линупс, но RivaTuner/Afterburner такой монстр, что не удивлюсь, если заработает.
>>640319 > локнуть частоту и повигать курву вправо-влево (по частотам), вот и полноценный андервольтинг А можно вот это вот если не подробнее объяснить, то хотя бы на ключевые термины разложить для дальнейшего гугления, пожалуйста?
>>640415 >В шинде же просто афтербернер должен работать. Неплохо было бы. С LLM P40 больше 150 ватт не жрёт, а если ещё скинуть... И память можно чуток погнать. Странно что еще не пробовали.
>>640340 Да разница разве что в количестве кода. Сам тоже нихуя не оптимизировал, сру в gen 0 только так. Потом займусь. Может быть.
Осло, скачал ХОРНИ модель. Скачал карточку, закинул, дописал, что смотрим вместе фильм. Знаете, чем кончилось? ХОРНИ модель попросила уважать её личные границы и смотреть в экран, а не на неё. Не, в пизду, пусть компьютер лучше рассказывает, чем мешок картошки лучше человека, чем вот так.
>>640312 Пик. Митомакс+кимико дают классную историю, но не оригинальна если хочешь кум.
Unholy намного новее, отличные истории, отличное повествование, намного более разнообразна, но через время начинают тупки с повторением сообщений, потом приходится либо вести за ручку какое время либо перегенерировать время от времени последние сообщения.
Наверно платиновый вопрос, но что делать, если у меня бедный словарный запас? Выдает мне нейронка полотна текста, а я в ответ аук среньк какой то. Как подтянуть уровень? Просто читать?
>>640553 Странный вопрос. Если ты имеешь ввиду недостаток словарного запаса в английском, то подтягивать английский. Если с фантазией бедно, качать фантазию поглощая контент.
>>640559 Ну вот генерирую около порнуху и фентези дндшное. Что нужно потреблять? И вот насколько теряется текст, если я на русском делаю витиеватые текста и перевожу?
>>640553 IMPERSONATE. Или сломай нейронку, чтобы она выдавала твои ответы за тебя, лол, останется только кнопочку нажимать. Ещё ты всегда можешь заюзать гугл транслейт, но - сюрприз-сюрприз - он проёбывает очень многое. С другой стороны, нейронка это ж не человек, ей похуй, что ты там пук-сереньк, она на каждую генерацию съедает и собственный текст со словесными кружевами в том числе. Если генерирует таковые. Так что при хуёвом языке, ломаном языке, ей похуй. Главное, чтобы она хотя бы примерно тебя понимала на уровне "моя говорить привет". Первые генерации с таким языком будут говном, но если подзабить контекст, уже пойдёт её максимальный скилл.
Напомнило мне, как я на тестах закидывал в инпут FUCK YOU SUCKER и SUCK YOU FUCKER поочерёдно, чтобы отрегулировать работу с api. Вот это было охуенно, всем советую, нейронка под конец билась в истерике и кричала что-то типа "я думал, что мы друзья, но теперь нет! нет! нет!" и так до конца макс токенов.
>>640585 > IMPERSONATE. Или сломай нейронку, чтобы она выдавала твои ответы за тебя, Я бы хотел такую штуку, что я даю нейронке свой краткий текст, и он бы его обогащал описаниями и всем прочим, и уже считая это как мой ответ генерировал бы новый текст.
>>640586 Допиши модуль к вебюи, тебе, по сути, и надо, что отправить сообщение без контекста с карточкой типа "ты берёшь и разворачиваешь описания того, что я тебе отправил". Вторую нейронку в память грузить не придётся.
>>640553 > если у меня бедный словарный запас Радоваться, ведь так тебя не будет напрягать косноязычность сеток. >>640585 > сломай нейронку, чтобы она выдавала твои ответы за тебя, лол > IMPERSONATE Так это оно и есть >>640586 Просто отдельный запрос как >>640590 написал, можно в таверне дописать экстеншн, вроде даже что-то подобное уже было.
>>640660 Разница на уровне недетерминированности ценой 5% 15% (с контекстом) большего жора врам, при том что на других моделях обратный результат. > Еще и тест на калибровочном датасете Таблетки
>>640674 >>640670 Верно слегка проиграла exllama2. Но gguf обеспечат качество на любых данных, а exllama2 только на википедии. При том что тут еще нет q5 который будут лучше и exllama 4.9, заняв на 300мб в видеопамяти больше, при этом опять будет тебе гарантировать качество на любых данных.
АНТУАНЫ КАКОЙ СЕЙЧАС САМЫЙ ПИЗДАТЫЙ ЛОКАЛЬНЫЙ АНАЛОГ ЧАТАГПТ? Не знаю нихуя, полгода назад пробовал ламы-хуями и различные их вариации - на выходе кал. Только что микстраль скачал - вроде бы более-менее. Есть ли что-то пизже? Дельфин-микстраль что за зверь?
>>640692 > Но gguf обеспечат качество на любых данных, а exllama2 только на википедии Главное эту мантру себе по утрам повторяй. Ознакомился бы с темой, посмотрел бы какая битность какому кванту соответствует и не позорился бы. >>640717 > АНАЛОГ ЧАТАГПТ? 120б на основе мику, лол. Если сузить запрос, сформулировав что нужно, можно много вариантов предложить под разное железо.
Пиздец идея появилась, а что если распределить MoE модель на компы юзеров аля торрент? Берем создаем gating функцию для каждого клиента, граничим ее на 100-200 экспертов. gating функция может быть насколько мне известно обычной Dense сеткой этак на три слоя по 100млн параметров каждый, так что ее можно будет обучать правильно роутить даже на полудохлом CPU от фидбека юзера. Брать от нее будем topK экспертов что находятся в онлайне, а сколько K экспертов брать пускай указывает сам юзер. Таким образом, предположительно можно будет еще и давать юзерам подгружать своих экспертов, высосанных из обычных LLM моделек (тут же представил фулл засранную ERP-модельками сеть), а gating функция в таком случае будет понемногу обучаться использовать их в время инференса.
Остается только проблема с тем, что юзеры находятся не постоянно в онлайне, если вообще не заходят раз в месяц чисто кум контента себе наделать.
>>640821 > Остается только проблема с тем Что эксперты на поверку дебилы. Микстраль нельзя повторить просто закинув восемь шизомиксов. Двести шизомиксов наврядли будут сильно лучше.
>>640823 Разумеется нельзя, так как там кроме gating функции одновременно тренились и все эксперты. Тем не менее попробовать стоит, так как предположительно, если в сети будет эксперт, что понимает хорошо математику и будет другой эксперт, что хорошо понимает как говнокодить, то на промпт "напиши-ка мне код который вычислит производную N функции" правильно обученная gating функция возьмет вывод с этих двух экспертов.
>>640823 И кстати говоря, зачем нам потом закидывать туда простых Франкенштейн-экспертов, если мы можем добавить обучаемость самих экспертов в этой самой сети? Ведь в таком случае, эксперт будет учиться в итоге брать на себя определенные подзадачи в этой самой сети, как в обычном MoE. А давать обучаться эксперту или не давать может сам юзер-хост, смотря позволяют ли его мощности обучать эксперта или нет (с adafactor 7b модель можно более или менее обучать на 24gb видеопамяти)
>>640760 Щас бы ему с Микстрали на Мистраль даунгрейдится. =) Соево-дистилированного гермеса или же незатыкающегося опенчата. Хотя опенчат неплох, да.
>>640821 Распределенных моделей несколько проектов есть с весны, и там и МоЕ не нужно — с 70б вполне работают. Но, как видишь, всем похуй, не взлетело.
Хотя Хорду кто-то да юзает, там сидят свои сотни людей.
Но в общем, сомневаюсь, что этим будут пользоваться, даже если ты поднимешь качество от уровня плинтуса. ИМХО.
>>640867 >Распределенных моделей несколько проектов есть с весны, и там и МоЕ не нужно — с 70б вполне работают. petals? он позволяет только инференсить их и совсем слегка обучать. Кроме того, чем больше модель - тем дольше ее инференс, так как тебе приходится пройдись по всем 70B параметрам. и сделать сеть умнее не получится - только если заменять модель целиком. С MoE проще, так как ты из общих 700B~ параметров берешь например только 21 (если использовать 3 эксперта и учесть что скорее всего все эксперты будут 7B). Хочешь сделать сеть еще умнее? добавил еще парочку экспертов, задал им обучаемость, подождал, профит.
>Хотя Хорду кто-то да юзает, там сидят свои сотни людей. фактически тоже самое, только теперь 1 модель на 1 хостера.
>>640821 Не знаю что только что прочитал, но звучит ахуенно, лол. А вообще можно попробовать экспертов пихнуть в лепестки, или даже орду, но задержки все на ноль помножат. Плюс повышенная нагрузка и огромное число холостых запросов что не будут использованы в итоге, если правильно понял задумку.
принцип работы gating функции в том, чтобы выбирать K самых подходящих под промпт по мнению этой самой функции экспертов, и отправить обрабатывать промпт (представим что промпт, на самом деле там чуточку сложнее) им. Если у нас есть 8 экспертов, но мы берем лишь 2 самых лучших, то остальные не будут задействованы вообще, что означает что холостых запросов не будет.
>>640882 Все же, это скорее добавляет знания, а не то чтобы логику. =) Количество-то слоев мелкое остается. Но если мы предположим экспертов побольше… на больших видяхах…
Опять же, 99% людей использует одни и те же эксперты. А моделька (условная) со знанием 100500 рецептов цукини пригодится примерно никому. Хотя я могу представить, как твоя вайфу использует ее в рп готовки, окей.
>>640891 Но ведь оно будет работать если тренилось совместно с самими экспертами, чтобы их части были согласованы. И должна очень явно проявиться убывающая прибыль от роста количества экспертов, если на 8 давая двум смысл есть, то на 100+ уже мало. Особенно если не юзать каких-то специальных методов. Если только не пускать на множестве, чтобы потом как-то оценивать, заодно собирая данные для обучения но тогда будут те проблемы, и мелочью из трех слоев уже не обойтись.
>>640891 >Если у нас есть 8 экспертов, но мы берем лишь 2 самых лучших А чтобы оценить их качество, нужно получить вывод от каждого и сравнить с эталонным.
>>641047 >А чтобы оценить их качество, нужно получить вывод от каждого и сравнить с эталонным. gating функция в время инференсов постепенно может обучаться в зависимости от фидбека юзеров. И пару раз в день ее можно синхронизировать между юзерами в сети.
>>640920 >если на 8 давая двум "Брать от нее будем topK экспертов что находятся в онлайне, а сколько K экспертов брать пускай указывает сам юзер".
>>640911 >Все же, это скорее добавляет знания, а не то чтобы логику. =) Количество-то слоев мелкое остается.
на каждый вывод токена каждый раз берут очередных экспертов, так что не думаю что это будет добавлять только знания, так как предположительно даже такую абстрактную задачу как логическое мышление модель в итоге может разбить и на 100 и более экспертов.
>>641197 >ЕМНИП эксперты выбираются на токен. На каждое слово по отзыву просить? зачем на каждое? нам достаточно знать какие эксперты были задействованы, и в том случае если итог юзеру не понравился, уменьшить вероятность того что в следующий раз эти эксперты будут задействованы.
>>641232 Оу... Спасиб за инфо. А то я смотрю что тут аноны по 70b гоняют. Я чет думал что многие ждут, попердывая в стул. А тут оказывается GPTQ в 3 раза быстрее аж. Жаль что в шапке этот вопрос не рассмотрен.
>>641233 А так GTPQ то только в видеопамять можно, а GGUF делить можно в карту и ram. На кой мы по твоему на гуфе сидим и копейки тоекны свои дрочим? Удачи поместить 70б в видеокарту.
>>641236 Бля, я думал что мне хватит скачать exllama2 да подрубить её к таверне. Далее скачать модель гиглв на 30 и тихо запустить её. А тут еще какие-то гуфы. Может есть како-то гайд для раков?
>>641237 Какой у тебя бекэнд и какой фронт? У меня угабуга бек в котором я через llamacpp_HF запускаю 20б модель. Часть слоев кидаю на карту для скорости, остальное в рам. Потом ко всему этому через апи конектится таверна в которй я и играю.
>>641228 Погоняй эту модель в обоих форматах, у меня по итогу получилось, что GPTQ где-то вдвое быстрее, но реально намного тупее. Если значительное ускорение стоит того, тогда дерзай. А так, весит меньше, работает быстрее, одни профиты.
>>641242 >>641243 Ну пока у меня кобольдццп фронт и таверна в виде бэкэнда(надеюсь верно описал). Стоит качать угубугу? Далее подрубить её к exllama2? Просто когда пробовал GGUF на 70b запустить через кобольдццп- у меня было всего 20 слоёв и скорость ну токена 2 в секунду.
Я тупой, поэтому узнаю, если накатить это https://kemono.su/patreon/user/80482103/post/92531137 и каким-то способом подрубить к exllama2, то мне будет счастье? Хотел в таверну погонять в свой выходной, а оказалось что есть GTPQ, который покруче. Пиздец короче. Лучше бы был в полном незнание. Если совсем тупые вопросы- лучше не отвечайте. Пойду реддит мучать.
>>641249 К угабуге не надо подрубать что-то, она по дефолту умеет в экслламу. Можешь таверну подкинуть, но это не обязательно. Два токена на 70b это ещё дохуя, у меня 2-3 токена на 34b на 3080ti.
>>641258 >>641260 Стопе. А сколько вы тогда вы ждете ответа с моделями в 34/70b через GTPQ? На GGUF 13b госпожа ЛЛМ дает ответ на 300 токенов ну секунды 4-8.
>>641266 Тупо скачал и запустил. Только долго это, пиздец. 32гб ram.
>>641269 >ждете ответа с моделями в 34/70b А я их не гоняю, нахуй надо ждать по вечности ответ. Гонял 13b в fp16 последние пару дней, скорость нормальная, сейчас скачал 13b в gptq для теста, ну, быстро. Но или модель слишком зажатая, или надо настройки смотреть, мало пишет.
>>641275 >что то запустить на своей джокерской 1650 можно? Контру попробуй. Дота ещё должна вроде запуститься. То, что у тебя поместится в ОЗУ или видеопамять даже нет смысла запускать, какое оно тупое
>>641286 Ну ты же гоняешь её через GGUF 70b, верно? Минут 5 ждешь или поменьше?
>>641289 Я тут начал качать 20b модель в GPTQ, она вроде слезает в 11гб с 4-bit group size 128g. Не сравнивал 13b и 20b? Чет уже не думаю что переход на GPTQ не такой уж радостный. Скорости с 200 слоями на 13b хватало за глаза, хотелось именно больших моделей, но что бы не ждать по 5 мин.
>>641289 >Тупо скачал и запустил. Только долго это, пиздец. 32гб ram. Мне все равно буде тчто долго. Какую конкретно модель? У меня чет не лезет в похожий сетап.
>>641296 > с 200 слоями на 13b Что, простите? На большие я бы даже не расчитывал, жду свою p40 и то вряд ли буду даже на ней гонять что-то жирнее 20b. А, скорее всего, останусь на 13b. Ooba это буквально самое простое, что только может быть.
>>641296 >её через GGUF 70b, верно Других вариантов нет. >>641296 >Минут 5 ждешь или поменьше? По минуте. >>641307 Это дефолт, типа "без лимита выгрузить всё".
Клятый угабуга завелся только после того как выставил слои в 256. Да, быстро отвечает. Надеюсь больше не будет таких пасхалок от людей с iq 130 для людей с 84.
>>641379 >Клятый угабуга конченая хуета которая не раьотает из коробки а выебывается как будто работает еще и после каждой ошибки нехватки памяти надо перезапускать иначе он не будет работать с моделью с которой 5 мин назад работал еще и генерит по 5 минут на ехламе
>>641348 Берёшь ссылку, копируешь в угабуге во вкладке model, там есть поле для скачки. Скачиваешь, нажимаешь загрузить. В 99% случаев все настройки подхватываются автоматически и тебе буквально ничего не нужно больше делать. Ну, настроить семплер и карточку по вкусу разве что. Это не самые быстрые варианты, не самые оптимальные модели, можно скачать квантованые, gptq или другие версии. Но эти работают тоже. GGUF я не гонял, это вроде процессорная пердоль. Не интересно.
>>641388 > сколько ОЗУ, процессор, мне реально интересно какое это имеет значения на (ВИДЕО) моделе гпткью для ексламы? врам иногда хватает на 13Б и стабильно хватает на 7Б в озу упора вроде небыло на сколько помню когда тестил
>>641189 > "Брать от нее будем topK экспертов что находятся в онлайне, а сколько K экспертов брать пускай указывает сам юзер". Речь о том что в этом мало толку, организовать 8 разных - уже задача, а тут столько разных, плюс возможность абуза заданием большого количества. > на каждый вывод токена каждый раз берут очередных экспертов Задержки >>641228 В том что помещается в твою врам - будет быстрее. Но на 12 гигов особо не разгуляешься, поэтому для чего-то побольше 13б ггуф - вынужденый выбор. Сильно не огорчайся, всеравно будет быстро если в пределах 20б. >>641237 > Бля, я думал что мне хватит скачать exllama2 да подрубить её к таверне. Далее скачать модель гиглв на 30 и тихо запустить её. Да, но это только в случае если у тебя хватает врам. > Может есть како-то гайд для раков? https://2ch-ai.gitgud.site/wiki/llama/ https://2ch-ai.gitgud.site/wiki/llama/guides/kobold-cpp/ https://2ch-ai.gitgud.site/wiki/llama/guides/text-generation-webui/
>>641269 > А сколько вы тогда вы ждете ответа с моделями в 34/70b через GTPQ? Поскольку есть стриминг - не ждем вообще. На полную печать ответа может уходить до 20-30 секунд, 40+ в особых случаях на полотна 600+. >>641350 Катай кобольд раз так, если все работает то смысл в убабуге есть прежде всего для CFG (хотя хз может в кобольда его завезли) и при работе с exllama. >>641384 > конченая хуета которая не раьотает из коробки а выебывается как будто работает > еще и после каждой ошибки нехватки памяти надо перезапускать > еще и генерит по 5 минут на ехламе Какой-то максимальный скиллишью, что-то делаешь неправильно.
>>641374 >таблицу моделей со значками и фильтрацией Ты куда глаза проебал? >>635452 (OP) >Рейтинг моделей для >>641379 >Надеюсь больше не будет таких пасхалок от людей с iq 130 для людей с 84. Стань человеком с iq 130.
Никто не пытался подрубать eGPU(внешнюю, через thunderbolt/USB-4) к своему ноуту для работы с llm? Ноут достаточно шустрый(ryzen 9 7940, rtx4070, ram 32 ddr5), но вот vram всего 8 gb, что пздц как мало, квантованные 7b и 13b еле влазят, все что больше неюзабельно. (1-2,5t/s на 33b модели). Вот думаю купить box под карточку и tesla p40. Вопрос в том заведется ли (p40 будет работать под виндой 11?), можно ли будет объединить vram ноутбучную и p40? Или проще по цене этого бокса собрать китай сборку на xeon?(не хочу этот хлам у себя дома складировать)
>>641482 > внешнюю, через thunderbolt/USB-4 Она будет видеться как обычный девайс. Требований к ширине шины у LLM особо нет, в теории даже сможешь разбивать между основной гпу и внешней. > Вот думаю купить box под карточку и tesla p40 Бокс обойдется в разы дороже этой теслы. Лучше просто собери любую пекарню на самой доступной комплектухе (бюджетной или бу), можно даже в ITX корпус оформить если сможешь разобраться как турбину в тесле приколхозить. Подключаться будешь удаленно хоть с мобилки а штуку эту разместишь в любом месте своего дома. >>641488 > Есть ли преимущества в скорости > Или те же яйца, только UI другой? Какбы кобольд - юзер френдли обертка llamacpp, заточенная под простоту. Убабуга - ебический комбайн под разные лаунчеры (в том числе более быстрые чем llamacpp) и функции. Правда многое там коряво и нужно далеко не всем, но сам факт.
>>641502 Если брать китайский бокс, а не фирму (ryzer), то 10-15к. Xeon + 64ram, выйдет примерно столько же, не считая корпуса, охлада, мусорной gpu для вывода изображения и ssd, просто не факт, что в дальнейшем этот хлам будет поддерживаться разработчиками (винда 11 заводится с бубном). Но за ответ спасибо, сам к таким выводам пришел, но мб кто на практике внешний бокс собирал, хотел узнать возможные подводные.
>>641513 Тут судить сложно, если бы делал сам - взял бы с рук готовую itx платформу на ддр4 с igpu. В 10-15к можно взять что-то с 32 гигами рам, если нужно 64 - добавить еще 5к. Иногда такое сразу в комплекте с корпусом можно найти, из расходов - только на нормальный бп 400+вт. Или какой-нибудь некрозеон, или просто ддр4 обычную платформу на чем-то не старше райзен 3000/интел 9000 с перспективой под вторую гпу. Это убивает сразу все потенциальные проблемы с совместимостью и позволяет удобно размещать. > Если брать китайский бокс, а не фирму (ryzer), то 10-15к Полный комплект с бп и прочим? Очень круто на самом деле. По поводу совместимости - это все работало с паскалями, но врядли кто-то вообще пытался проверять с некротеслой на современной системе, так что ты будешь первым.
>>641520 Ну я тоже рассматривал для последующего расширения некросборку, чтоб мать держала (pci-e x 16) штуки 2-3, 4 канала DDR4. Просто если брать что-то более современное(ryzen со встройкой или intel, а старая хрень 2-4 ядра будет очень тормознутой), то такая мать с поддержкой стольких pci разъемов выйдет ОЧЕНЬ невыгодно. Цена бокса без БП, но думаю, что на барахолке найти не будет проблем. Вот и я по совместимости сомневаюсь, перерыл кучу статей и обсуждений, но ничего подобного не нашел.
>>641529 > чтоб мать держала (pci-e x 16) штуки 2-3, 4 канала DDR4 Если делаешь сборку на видеокартах - каналы памяти и перфоманс проца не имеют значения (в разумных пределах). По поводу линий - полной ясности нет, но с очень высокой вероятностью тоже. > такая мать с поддержкой стольких pci разъемов выйдет ОЧЕНЬ невыгодно Буквально любая с формфактором ATX. В не самых новых но более жирных часто можно поделить х16 на 2х8, но врядли проиграешь даже на чипсетных. > по совместимости сомневаюсь Чтож, можешь попытаться найти людей у которых будут бокс под видюху и тесла для проверки. Сразу понадобится переходник на ее питалово, кулер для проверки работоспособности не потребуется, но можешь уже думать как его организуешь и куда там будешь подключать. >>641544 +
>>641544 Знаю, что лучше. Просто меня пугает этот перолинг с консолью и возможные проблемы с драйверами(проблемы совместимости более актуальны для linux нежели винды). Хотя все равно придется учиться, это да.
>>641549 > возможные проблемы с драйверами Как бы рофлово это не звучало, но там потенциальных проблем с драйверами будет гораздо меньше, чем при попытке подружить шинду с радикально разными архитектурами видеокарт, одна из которых еще и мобильная, а основной выход изображения через встройку. Пердолинг - будет.
>>641552 В инете куча роликов про дружбу видюх разных поколений с разными дровами(laptop и eGPU), но вот дружбы с серверным оборудованием как раз и не находил. Но пердолингу быть, это факт.
>>641548 >Чтож, можешь попытаться найти людей у которых будут бокс под видюху и тесла для проверки. Хах, и вот тут я иду нахуй. Глянул сборки на ryzen 2-3 серии, если количество потоков на проце не решает для llm, то вариант хорош. Надо обдумать. Сяп за совет.
>>641217 за два часа наговнокодил серверную часть и на 50 клиентскую, благо в hivemind все уже почти готово. Остается только решить загрузку нужных весов и все, proof of concept готов. А дальше, если так и дальше хорошо пойдет то можно будет доработать уже сам hivemind под нужды проекта и будет кайф. Кстати, немного не понял метод работы mixtral в прошлый раз: оказывается в нем довольно много декодер слоев, и каждый декодер содержит attn и по 8 экспертов, каждый эксперт не так уж и много весит и 7B на эксперта берутся из за количества этих самых слоев. Это нам даже на руку, так как теперь мы можем например взять 20 слой и напичкать его более большим количеством экспертов, и это нормально встроится в уже рабочую сеть.
>>641548 >Если делаешь сборку на видеокартах - каналы памяти и перфоманс проца не имеют значения (в разумных пределах). По поводу линий - полной ясности нет, но с очень высокой вероятностью тоже. Скоро узнаем. Я поверил чувакам с Реддита и купил б/у ASUS x99-E WS. Вообще вся сборка б/у так что шанс, что всё сразу заработает невысок. Да и P40 у меня пока всего две. Но малый квант 70В влезет.
>>640717 >Дельфин-микстраль что за зверь? Присоединяюсь к вопросу. Пока что есть подозрение, что дельфинами называют попытки разбавить соевость, но я не уверен.
какого хрена бугабуга вместо автоскачки с кагфейс модели - качает только методаные и файл ридми и говорит якобы готово? год назад такой хуйни не было!! как качать то?
>>642036 Ну я дрочу чисто но дрочу очень сладко. Аноны помунее там рерайтя кодят и вообще новукой занимаются. >>642040 noromaid-20b-v0.1.1.Q5_K_M.gguf У меня прям 1:1 сетап.
>>642046 Ты дурачок? Я же специально полное называние дал. Q5_K_M качай. Качаешь угабугу, скидываешь скачанную модель в папку для моделей, запускаешь угабугу и включаешь в настройках флажок с апи, загружаешь модель отдавая часть слоев на видимокарту для скорости. Качаешь таверну, подключаешь к угабуге, с chub.ai качаешь персонажа, чатишься, кумишь так сильно что пробиваешь потолок.
Анонсы, встал впрос. Есть задача - создать инструмент, который, используя ai будет выдавать ответы на вопросы по конкретной тематике. Самое лучшее что смог придумать - отвалить денег OpenAI с их assistant и, используя chagpt4 с retrival tool (позволяет загружать файлы, чтобы модель могла использовать их для построения ответа) - через апи просто пересылать вопросы и получать ответы. Файлов достаточно много (почти все пдф - мануалы), кроме нескольких, которые являются примерами типа "вопрос-ответ" (они json)
Плюсы такого подхода: 1)Удобность - просто закинул файлы и готово 2)Ответ быстро генерируется (10сек-1мин) Минусы: 1)Платно (не парит) 2) Даже используя казалось бы не самую плохую модель - не всегда получается получить релевантный ответ
Собственно из-за второго минуса я и написал сюда. Есть ли ещё какие-либо способы решения моей задачи?
Как я понимаю, в идеале - найти бы модель, которую можно запускать локально/сервер и у которой есть возможность "скармливания" материала, чтобы я мог все свои пдф-мануалы и примеры-json скормить ей, чтобы она могла выдавать релевантные ответы именно по этим материалам. И да, время генерации ответа критично - хочется, чтобы на это уходило не больше минуты.
>>635452 (OP) Подскажите ньюфагу моменты: 1. Есть ли цензура и подобные ограничения? 2. Можно общаться только с готовыми модельками которые скачаю или есть возможность обучить свою? 3. Можно спрашивать что-то для поиска или обучения? Может ли искать инфу в инете? 4. Что за таверна? 5. Подскажите какие модели могут подойти под систему: AMD Ryzen 3 Pro 3200G, 16 gb оперативки, RTX 4060 Ti и/или как в дальнейшем понимать/искать пойдут ли они мне?
>>641405 >Какой-то максимальный скиллишью, что-то делаешь неправильно. Угабуга - объективно самый пердольный и не-юзер-френдли бэк, хоть у тебя iq 85, хоть 3000.
юзаю кобальд сс казалось бы универсальная херня юзаю формат ггуф как советовали итт с Masterjp123-NeuralMaid-7b. любым количеством после кью выдает типо пикрил