В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны! Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна. Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2-х бит, на кофеварке с подкачкой на микроволновку.
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт). Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Текущим трендом на данный момент являются мультимодальные модели, это когда к основной LLM сбоку приделывают модуль распознавания изображений, что в теории должно позволять LLM понимать изображение, отвечать на вопросы по нему, а в будущем и манипулировать им.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
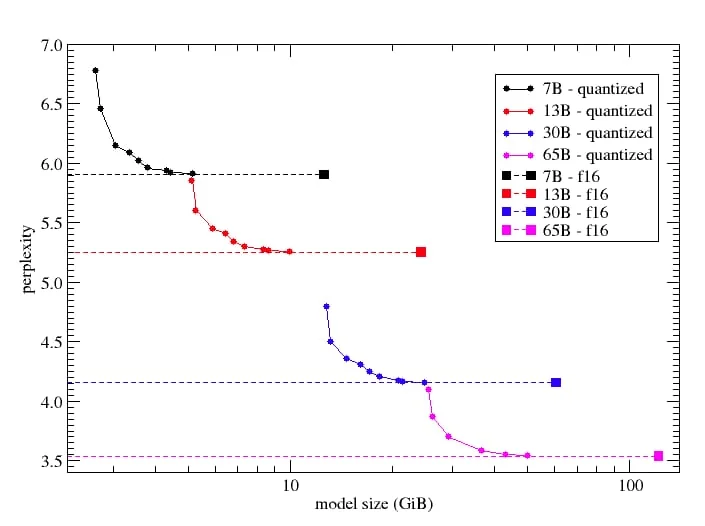
Сейчас существует несколько версий весов, не совместимых между собой, смотри не перепутай! 0) Оригинальные .pth файлы, работают только с оригинальным репозиторием. Формат имени consolidated.00.pth 1) Веса, сконвертированные в формат Hugging Face. Формат имени pytorch_model-00001-of-00033.bin 2) Веса, квантизированные в GGML/GGUF. Работают со сборками на процессорах. Имеют несколько подформатов, совместимость поддерживает только koboldcpp, Герганов меняет форматы каждый месяц и дропает поддержку предыдущих, так что лучше качать последние. Формат имени ggml-model-q4_0, расширение файла bin для GGML и gguf для GGUF. Суффикс q4_0 означает квантование, в данном случае в 4 бита, версия 0. Чем больше число бит, тем выше точность и расход памяти. Чем новее версия, тем лучше (не всегда). Рекомендуется скачивать версии K (K_S или K_M) на конце. 3) Веса, квантизированные в GPTQ. Работают на видеокарте, наивысшая производительность (особенно в Exllama) но сложности с оффлоадом, возможность распределить по нескольким видеокартам суммируя их память. Имеют имя типа llama-7b-4bit.safetensors (формат .pt скачивать не стоит), при себе содержат конфиги, которые нужны для запуска, их тоже качаем. Могут быть квантованы в 3-4-8 бит (Exllama 2 поддерживает адаптивное квантование, тогда среднее число бит может быть дробным), квантование отличается по числу групп (1-128-64-32 в порядке возрастания качества и расхода ресурсов).
Основные форматы это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной. В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090. Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это серьёзно замедлит работу. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой: 1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии. 2. Скачиваем модель в gguf формате. Например вот эту: https://huggingface.co/TheBloke/Frostwind-10.7B-v1-GGUF/blob/main/frostwind-10.7b-v1.Q5_K_M.gguf Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt 3. Запускаем koboldcpp.exe и выбираем скачанную модель. 4. Заходим в браузере на http://localhost:5001/ 5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI 1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern 2. Запускаем всё добро 3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001 4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca 5. Радуемся
>>654608 Без физического контакта - нахуй ненужно, только в рамках ассистента "сделай@загугли@напомни". Сидишь как вирджин уткнувшись в экран, вместо того чтобы как чед устраивать интенсивный продолжительный специфичный кадлинг, решить все бытовые вопросы, любоваться наряжая в костюмы и практиковать весь спектр прямых взаимодействий.
>>654621 > физического контакта Это уже потом. Круто было бы поковыряться там в ней, понастраивать, так-то реальную тян я могу и ИРЛ найти, а потом она сбежит от меня к вазгену >любоваться наряжая в костюмы Можно делать в программе.
>>654629 > Это уже потом. Когда потом? Пригодного для использования дома и недалеких прогулок гиноида уровень технологий уже позволяет сделать, все упирается в его ненужность без мозгов. > так-то реальную тян я могу и ИРЛ найти Это не то, да и одно другому не мешает но это не точно > Можно делать в программе. Вообще не то. Буквально несколько (десятков) вечеров и вот уже у тебя твоя вайфу в койцацу под управлением ллм, наряжай настраивай и ковыряйся во всех смыслах сколько угодно.
А посоветуйте модель от 30В, которая была бы умной. Имею в виду - хорошо держала контекст в 4к и не путалась бы в том, что там написано. А то генерацию 70B+ долго ждать, может есть удачные модели поменьше. Надеюсь.
>>654658 Попробуй ласт версию tess. Требовательна к промту и не совместима с большой температурой, как и почти любая yi. Еще yi v3, но довольно старая и может что получше от тех же авторов есть.
https://arxiv.org/abs/2402.17764 >The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits >soviet union was right >real world already proven than their focus in power electronics was more important for the troubles ahead than digital electronics что несет этот понадусёровый пендосошвайный локальнозависимый ананас?
>>654672 а вот тема про Q, хз что это, вроде как говорили что с помощью этого openAI создали самообучающийся ИИ, и этот же анон на скрине заявляет что секрет найден, очень хочется во всё это верить.
Что то не верю я в чудесное сохранение качества в такой нейросети. Как то слишком плосская получается, эдак теперь шутки о том что ии это куча if внутри перестали быть шутками опять.
Недавно читал похожую статью где нейронка воспроизводила изображения из глаз макаки. Может кто нибудь объяснить, они что, реально считали какие-то паттерны с мозга нейронкой? Там ведь хаос, нечего считывать, данные в отрыве от мозга не несут никакой информации, всё равно что предсказывать акции по рандомным колебаниям воздуха. Каким образом нейронка декодировала весь тот нейро шум который происходит в мозге и высрала картинку/текст? Почему именно с мозговой активности, почему не с движения глаз там хуй знает https://naked-science.ru/article/biology/ii-chitaet-mysli-po-dannym-tomografii
>>654671 Не знаешь историю развития пека и третичную систему вместо двоичной в первых комплюктерах совка? А он знает, но и лишнее тоже приплекает. >>654673 Шиза >>654679 Если как-то считать данные с нервной системы, или какие-то характеристики по активности (участка) мозга с достаточной высокой подробностью - на этих данных можно обучить нейронку, и она сможет их как-то интерпретировать. В примерах там просто черрипик с предсказанием общего настроя текста, не сказать что что-то уникальное.
>>654678 >basically, the maths shows that what works best is e (2.73) values, and because the ternary paper shit is using 3 values, it's the most optimal stuff we have and the LLM is loving it, that's why it performs as well as fp16 >В принципе, математика показывает, что лучше всего работают значения e (2.73), а поскольку в троичной бумажной хрени используются 3 значения, это самый оптимальный материал, который у нас есть, и LLM он нравится, поэтому он работает так же хорошо, как fp16.
>>654680 Я так понял, в тексте производилось обучение нейронки на связи проговариваемых слов и данных с томографа, сама нейронка ничего не интерпретировала, просто запомнила ассоциацию. С таким же успехом можно было считывать данные с движения лицевых мышц во время проговаривания слов, эффект был бы лучше. Не понимаю смысла этого эксперимента. Хуй знает, можно ли из этих данных получить какой-то уникальный нейрокод или паттерн активности и сказать что мы "скопировали" кусочек человеческого сознания. Вопросов больше чем ответов.
>>654689 Говоришь кожанным читать/думать/представлять что-то во время томографии после основной процедуры. Обучаешь сеть на этом наборе данных. Потом тестируешь хоть тех же (читы но вероятно), хоть уникальных и выбираешь где подошло. > и сказать что мы "скопировали" кусочек человеческого сознания Шиза
>>654692 бля, а ведь это реально найдёт применение. скажем, 180B нейронка что загружена в троичный фотонный компьютер(пикрил), отвечает тебе за секунду, без галюнов и прочего, идеально.
братцы, почему у меня с вот этими настройками каждый раз один и тот же вывод? миростат не работает или нужно крутить другие семплеры впридачу к миростату?
>>654489 → > Что ты сказать то хочешь? Я хочу сказать, что человек не будет говорить того, что вредит его бизнесу. А пиздеть об изобретении того, чего все ждут, — это провал. Маска сильно не любили за его обещания автопилотов «вот уже завтра». И он стал поскромнее в обещаниях. А остальные вообще не были пойманы на таких обещаниях, ну или я не припомню.
>>654678 Плюсану. Я понимаю, что обучение дает больше качества, чем квантование большей модели. Но не настолько, чтобы мы получиди полноценную 70B. Скорее это будет уровня 13-20 нынешних сеток, но со знаниями 70. Что, в принципе, очень хорошо. Но не так, чтобы гений, как многие тут ждут.
А вот для 34B уже появится скорость, что делает такую модель интересной для ассистентов.
>>654695 Мне кажется, переход на это не будет быстрым.
>>654696 Как известно, они все дурачки с деньгами и без мозгов, верить надо только анону с двача. =D
>>654712 Мод 2 для экслламы, мод 1 для лламы.цпп. А ваще я кручу в убабуге, хз, может в таверне сломано.
>>654714 > smoothing factor 0.2 У меня с этой шляпой модели начинают промпт игнорировать. Указываешь в карточке персонажа, что она трусы не носит, но они постоянно появляются. Даже Микстрал временами начинает мозги ебать. Без этого параметра всё ок. Зато лупов нет да...
Исследователи из компании JFrog выявили в репозитории Hugging Face вредоносные модели машинного обучения, установка которых может привести к выполнению кода атакующего для получения контроля за системой пользователя. Проблема вызвана тем, что некоторые форматы распространения моделей допускают встраивание исполняемого кода, например, модели, использующие формат "pickle", могут включать сериализированные объекты на языке Python, а также код, выполняемый при загрузке файла, а модели Tensorflow Keras могут исполнять код через Lambda Layer. Для предотвращения распространения подобных вредоносных моделей в Hugging Face применяется сканирование на предмет подстановки сериализированного кода, но выявленные вредоносные модели показывают, что имеющиеся проверки можно обойти. Кроме того, Hugging Face в большинстве случаев лишь помечает модели опасными, не блокирую к ним доступ. Всего выявлено около 100 потенциально вредоносных моделей, 95% из которых предназначены для использования с фреймворком PyTorch, а 5% c Tensorflow. Наиболее часто встречающимися вредоносными изменениями названы захват объекта, организация внешнего входа в систему (reverse shell), запуск приложений и запись в файл. Отмечается, что судя по совершаемым действиям большинство выявленных вредоносных моделей созданы исследователями безопасности, пытающимися получить вознаграждение за обнаружение уязвимостей и методов обхода защиты Hugging Face (например, вместо реальной атаки подобные модели пытаются запустить калькулятор или отправить сетевой запрос с информацией об успехе атаки). При этом встречаются и экземпляры, запускающие обратный shell для подключения атакующего к системе. Например, модели "baller423/goober2 и "star23/baller13" нацелены на совершения атаки на системы, загружающие файл модели в PyTorch при помощи функции torch.load(). Для организации выполнения кода задействован метод "__reduce__" из модуля pickle, позволяющий вставить произвольный Python-код в процесс десериализации, выполняемый при загрузке модели.
>>654696 Это ты рофлишь или пытаешься на серьезных щщах аргументировать хайпожорством? Уровень размышлений о летающих машинах к 1980-му году и всякого ретрофутуризма, который вещали "уважаемые люди". Или всратый копиум не имеющий связи с контекстом, так-то "разум Жириновского" был загружен уже после его смерти, ага. >>654757 > но со знаниями 70 Откуда им просто так отдельно взяться? Нужно посмотреть по факту, может как оказаться удобным форматом и в итоге улучшит перфоманс с гигабайта, или очередным пшиком с кучей нюансов. >>654766 Бедный журналист подвергся очередному насилию! Содержимое не ново. >>654767 >>654803 С весами ллм в сейфтензоре рядом могут поставляться дополнительные файлы с кодом, которые еще и требуются для их работы. Офк их запуск явно разрешать надо. >>654794 > что за вал скринов с форча со всякой хуетой Смена сезонов подстегивает, сука 4 раза одну и ту же новость тащат
>>654679 Такое и с человеком делали, пытаясь понять о чем он думает. Результаты интересные, но удручающие на самом деле. Иногда бывают норм силуэты от простых мыслей типа квадрат/треугольник. Что-то сложное сразу по пизде. И ученый сам признавался, что это скорее матчинг того, что они заранее сопоставили, чем "чтение". Короче хуйня это все.
Какая проблема вместо третичных битов юзать два двоичных, один для знака, другой для значения, int2_t. Чо вы все переполошились. Щас бы фундаментально менять архитектуры ради лишней пары чипов. Кост-эффективность это вопрос отношений рынка, кожанки и амуде, которая башку из жопы вытащить не может уже десять лет.
>>654819 Потому что 70b. =) Будут ли эти знания фактически применимы, и будут ли на них веса — вопрос немного другой. Возможно, что какие-то токены будут практически неиспользуемы из-за 1-битного квантования, канеш. Но посмотрим, может и правда пшик.
Как я всегда говорю — хотелось бы, но радоваться будем когда выйдет.
>>654888 >Они предлают Я предлагаю сделать AGI, который запускается на 1060. >>654890 >Так, вторая Тесла на подходе. Поздравление. >Мику? Она своеобразная. А так зависит от целей.
>>654871 Так понятно что использовали. Я про поехов, которые считают троичные биты чем-то супериор либо кост редюсинг. В нашем мире не та экономика, чтобы косты по себесу считать.
>>654890 Ничего не изменилось. Мику - хороша, можно пиздеть на русском, в ерп вяло, 120б франкенштейны с ней очень интересные. Там наделали мерджей, потести может есть годные. А так застой, ничего лучше синтии, айробороса, наверно хвина не придумали, гоат иногда интересные вещи сочиняет. Можешь мерджи попробовать коих сотни, но многого не ожидай, они большей частью просто поломаны. Квен еще глянь. > 4_K_M Больше с контекстом все равно не поместится а разницу пойди еще измерь.
>>654899 Те кто отрицает очевидность возможности колоссальной оптимизации при переходе на такие операции - не менее поехавшие, чем шизы что носятся с этим предрекая решение всех проблем. Если будет практическая польза - жди поддержки в грядушем (после блеквеллов офк) поколении гпу и выхода на рынок высокоэффективных ллм асиков ускорителей.
>>654902 Если будет польза, то ИИ ускорители будут, но вангую анальную огороженность и требование подписей со всего. Увы, железо уже давно не принадлежит пользователю.
>>654902 А в чем колоссальная оптимизация от самих тритов-то? Проще упаковать по n таких чисел в uint<2n>_t и суммировать векторы из них этой новой операцией. Нахуя тут троичная система? Речь не о самих операциях, а о фантазиях насчет троичных ячеек, которые физически те же два бита, только жопа к жопе.
>>654982 >Ждём появления кода и первых весов которые обещали. Ждём. А то ведь супер-квантизацию уже обещали с полгода тому. Другую правда. И ещё парочку революционных улучшений. Но тема заглохла, остались только гергановские кванты. Спасибо и на том.
>>654936 Если упростить совсем - под такие тривиальные операции легко как сделать асики, так и адаптировать какие-то из имеющихся инструкций или разработать новые.
>>655044 Не было потребности. Какую-то известность языковым моделям и перспективы их массового использования обрисовались только совсем недавно, буквально в прошлом году. Метод под тривиальные операции с демонстрацией также только показали. Ранее было заявлено несколько ускорителей, но они "универсальные" под питорч чтобы иметь возможность крутить любые нейронки, и сложность их очень высока. Здесь же порог вхождения ниже, требования ниже и рынок сбыта какой-никакой есть. Правда отдельная ветка может легко загнуться если крупные вендоры подсуетятся и внедрят блоки для такого в профессоры/видеочипы (что офк произойдет), но если будут еще нейронки что могут работать по таким схемам - новым ускорителям быть. > Всякие "нейропроцессоры", оптимизированные под нейронки ещё в 90х были. Оптимизированные под что-то одно, и это что-то одно нахуй не нужно кроме как для исследований и дальнейшего развития. Здесь же вполне конкретика.
>>655066 >Не было потребности Такое впечатление, что хайп спал, пипл в массе наелся чатомГПТ. То есть домашнего рынка нет как бы. Если тема с однобитовыми моделями выстрелит (что далеко не факт), то хотя бы вопрос по видеопамяти будет снят. А если нет, то даже для 70В 48 гигов давай, а кто даст, если NVidia с корпораций по 50к за ускоритель хочет? И ей дают, что характерно.
>>655072 Все только впереди, для 90% нормисов нейронки это какая-то диковинка и произведет впечатление. И видеопамяти всеравно потребуется много, не стоит рассчитывать что в 1.5 битах напрямую удастся получить перфоманс хотябы 4хбитных квантов, и даже так выигрыш только в 2.5 раза и то только на сами веса. Но выигрыш всеравно возможен и может быть ощутим.
>>654587 (OP) На Reddit пишут, что видеокарточки Radeon RX 580 на 16 Гб могут быть неплохой альтернативой Tesla P40, если у вас ограничен бюджет, при том вы хотите недорогую карту и для игр, и для AI экспериментов.
https://old.reddit.com/r/LocalLLaMA/comments/1b3i4g3/time_to_reconsider_amd_rx580_especially_for_folks/ > Even a GPU as cheap as the 24gb P40 is still very expensive at $200. In some places around the world that's a month's salary. Plus power draw of 250watts plus needing serious cooling. The AMD RX580 at 185watts is cheaper to cooler and the Chinese knockoffs are now coming with 16gb of ram to be found for just about $100 in aliexpress. With llama.cpp supporting Vulkan. I reckon it should work. Some folks with ollama got it working around 3 weeks ago - https://github.com/ollama/ollama/issues/2453 Just tossing this out for those of us who are slim in the wallet.
https://old.reddit.com/r/LocalLLaMA/comments/17gr046/reconsider_discounting_the_rx580_with_recent/ > There seems to be some interest in the RX580 lately. I tried using my RX580 a while ago and found it was no better than the CPU. That's changed. There has been changes to llama.cpp that has made it about 3 times faster than my CPU. While that's not breaking any speed records, for such a cheap GPU it's compelling. Especially the $65 16GB variant.
>>655459 >RX580 a while ago and found it was no better than the CPU. That's changed. There has been changes to llama.cpp that has made it about 3 times faster than my CP 588 даёт 10 Т/с на 7b q6, это не сильно лучше нынешних топовых cpu с ddr5. И это на rocm, на вулкане ещё немного медленнее, где-то посередине между rocm и clblast.
>>654587 (OP) Почему где-то в половине всех моделей не указываются настройки для таверны? Есть какие-то другие фронт энды о которых я не знаю или эти наркоманы РПшут убабугу? Особенно бесит когда модель специально пилится под ERP, а там пикрил.
Поясните какая сейчас лучшая модель для koboldcpp_rocm? Я год назад в пигмалион игрался но это хуйня и мне не понравилось, наверное он устарел уже и есть чего новое, чисто чтоб скачать файл модели без гимора и сунуть ее в кобольда да играться. Хочу чтобы можно было не только кумить но и юзать для хуйни какой-нибудь типо вопросы там спрашивать итд как у гугла и чтобы памяти было супер много, ну этого контекста. А то все как в это нейрохуйню не играл никакого фана нет с тех пор как Chai сломали цензурой и отыгрывать еблю в жопу стало нельзя, а судя по тому что раздел живет что-то интересное у вас тут должно быть.
Новая база. Кто бы че не говорил, а плюсы у нее практически все. https://huggingface.co/LoneStriker/Crunchy-onion-GGUF/tree/main карточку держит, этикой мозги не выносит в карточках. 12 гигов карты хватает, пишет хорошо. Хз почему он на 16 месте по сравнению с багелем который может сказать что в германии времен гитлы евреев нельзя сжигать иначе за тобой вызовут гестапо.
>>655454 Повторю из прошлого треда: Хуита полнейшая, пиздеж и шиза. Хватит тащить сюда это говно, спасибо большое.
>>655459 На реддите полные дегенераты меряют полезность AI не в токенах в секунду, а в ваттах. Не в производительности, а в потребляемой мощности. И еще делают гениальный вывод, что 185/16=11,5 ватт на гигабайт лучше, чем 250/24=10,4 ватт на гигабайт.
>>655474 Год назад обнаружилась. Еще старее новости есть? В открытом доступе обнаружилась Llama, прикинь.
>>655536 Где вы в Микстрали-то этику нашли… До сих пор вопросом задаюсь. Ну да ладно, качну для тестов, сегодня вторую теслу забирать и ставить буду. =3 Спс.
>>655543 где где. Даже чисто описания делаются менее интересные из-за гребанной этики. используются более мягкие* слова или полное противоречие карточке.
>>655554 не только мягкие слова. Еще иногда эта скотина и спорит с инструкциями моиими. Особенно бесит когда ты с ним утверждаешь инструкции, что он тебя понял, а потом эта скотина говорит тебе "да братан ты сказал не использовать пурпурную прозу ,но я подумал и решил что я ее чуть чуть добавлю." А помимо видюхи тебе че нужно все докупать начиная от матери до оперативы?
>>655459 Ушатанные в хламину годами химеры, собранные из разных частей сумрачными китайскими ремонтниками, которые еще при жизни не умели в энергоэффективность, к тому же древнее амудэ(!). Вот это сочетание заявление лучше чем дешманское, проперженное, но всетаки изначально правильно выполненное профессиональной решение, которое работает. > 3 times faster than my CPU лол Ахуеть ну что они там курят. И это не говоря о том что достаточно 2 теслы чтобы катать нормальные модели, и рыксы потребуется 3 и сразу возникнут проблемы с их размещением и охлаждением. В рамках попердолиться и всрать денег если только. >>655489 В 95% альпака и вариации ролплей пресета. >>655501 > Extended to 16k context size При том что базовый контекст у мистрали заявлен 32к, забавно. >>655543 Ее там слишком много, это не просто позитивный байас а довольно неприятная навязчивая хуета. Плохо что триггерится от упоминания слова assistant/assist что забавно. >>655568 Они тупые, плохо следуют контексту и мотивированы быстрее сбежать, уйдя в запой.
>>655489 Потому что инстракт суффиксы/префиксы не решают. Если речь идёт о рп, то оставляешь их пустыми и включаешь имена, и для любой нейронки скармливаемый в таком виде чат будет естественнее всего. Смысл имеет только как-то обособить системный промпт, где основные инструкции. Обособлять, опять же, можно как угодно, хоть через старое доброе [SYSTEM NOTE:], вряд ли будет большая разница с ###Instruction:. С содержанием самого промпта может быть веселее играться самому, а не юзать рекомендованные пресеты. Касательно пикрила, что на нём не так то? Пишешь USER: в префиксы инпут и/или систем и ASSISTANT в префикс аутпута.
>>655459 Лучше бы появилось что-то среднее между 4090 и Р40. Куртка выкатил бы 4060/4070 на 24 гига, я сразу бы пару штук взял. Р40 совсем нищекарта из 2017 года с нулевой энергоэффективностью, а 4090 стоит пиздец. А всё остальное без памяти, в лучшем случае 4070 Ti на 16 гигов, остальные совсем огрызки с 12.
>>655634 Он монополист в этой теме, гребет деньги по оверпрайсу, и вдруг решит лишить себя денег дав васянам возможность играться с ии? Низачто. Это также такой пайвелл от васянов, что бы только копрорации между собой могли заниматься ИИ и всей этой перспективной темой. Стартапы сосут как и энтузиасты.
>>655592 Не, мать взята со слотами разнесенными на 3, чтобы место было, проц со встройкой, чтобы не менять видяхи, если баг какой, и не только по RDP лазить, оперативы минималочка 64 с частотой 3600, ну так, охлад распечатан, кулеры куплены, БП норм, видяху уже забрал и проверил, работает. Но еще пару часиков на работе, а затем домой — охлад приводить в порядок, кулеры на молексы сажать, к видяхе колхозить. И уже радоваться жизни. =) Проект завершен (почти, потом еще 64 гига докуплю, на всякий случай).
И вот теперь точно 5090 ждать.
>>655594 > При том что базовый контекст у мистрали заявлен 32к, забавно. Кстати, когда я тестил большие статьи, мистраль могла в 20к контекста, дефолтная, из коробки, насколько я помню. Так что, там 32 и правда, зачем какие-то файнтьюны на 16, хз.
Вот файнтьюны на 128 — там я понимаю. Но там, как показала практика, уже оператива может закончится. =D
>>655634 > что-то среднее между 4090 и Р40 3090 ждет, дешевая, горячая, требующая обслуживания, твоя! >>655644 > еще пару часиков на работе Тыж безработный? > мистраль могла в 20к контекста Она могла и в 32, но сложно понять фейлит из-за того что тупая или из-за "искуственности" контекста с rope.
>>655459 >Radeon RX 580 на 16 Гб Отжаренная печка, которую майнеры грели во всех позах, а затем перепаяли память. >>655459 >Tesla P40 Жила в датацентре в хороших условиях, не ремонтировалась, не жарилась.
>>655657 >Тыж безработный? Это я безработный (и то сейчас подРАБотку нашёл). >>655762 >не ремонтировалась ЕМНИП тредовички смотрели прокладки, они были живые. >не жарилась А вот ХЗ. Картонка весьма старая, могла быть слита китаёзам ещё до первой волны майнинга. Ну как минимум второй бум она точно зацепила у китайцев на руках.
>>655775 >Ну как минимум второй бум она точно зацепила у китайцев на руках. Как бы да, но она в то время была дорогим проффесиональным оборудованием и не факт, что на ней стали бы майнить. Вообще, хз.
>>655830 > LHR Ты у мамы не очень умный? Погугли когда лок на майнинг эфира сделали аппаратный, и когда вышла P40. Китаец тебе много чего написать может
>>655848 >узнать что такое LHR Хули тут не знать, софтварный лок майнинга, который стали зашивать в карты под конец второго майнинг бума. Маркетолухи всё это пиарили, как хардварный лок и куча долбоёбов повелись, но почти сразу появились разные просочившиеся драйвера, на которых LHR не работал, анлокеры и т.д. Стан долбоёбов поуменьшился, но не исчез полностью, самые тупые всё ещё веруют в хардварный лок где-то в чипе.
Короче, нахуевертил охлаждения… molex => переходник на 2 molex => переходник на 4 вертухи 2-pin'овые корпусные + переходник на 2 molex => паянные молексы на 2 пары 40 мм вертух на каждую теслу. Надо будет хорошенько это все проложить по дну корпуса и приклеяться туда. НУ ДА ЛАДНА ЗАТО ОХЛАД
>>655650 > во сколько вышла сборочка. Вот тут сразу говорю: не очень. У меня тогда две видяхи умерло, меня заебало трястись за железо и я просто купил в ДНС, с гарантией, что было в моей деревне, подходящего качества. Ну и не жалею, если честно. Материнка 11,2к, проц 15,8к, оператива 14,4к, блок питания… брал давно, но будем считать 12к, т.е. 53 тыщи. Проц, как полагается, подешевел на две тыщи после покупки, а если бы с мегамаркета, то и вовсе вдвое бы дешевле взял с кэшем. Плюс ссд два по 2 тыщи, кулер за 2 тыщи, наверное, плюс одна Тесла за 16, вторая за 15,3 (это я ее тогда отменял на алике и брал на озоне, когда она подешевела везде после моей покупки=). Кулеры, переходники. Итого 87к, получается. Но по факту, можно взять оперативу чуть дешевле, проц раза в два дешевле, материнку на пару-тройку тыщ, бп на пару тыщ, короче, в сумме можно уложиться в 70к, я думаю. Ну и это отдельный комп, хотя, по факту, 64 гига оперативы и i5 со встройкой вполне позволяют пользоваться им как основным, но игровой у меня другой.
>>655777 В очень узкий задачах — лучше мистрали. Но в общем, если ты не делаешь корректного соевого левого чат-бота по темам, которые ей известны — то я бы даже не трогал.
>>655657 У меня две работы. =D Я ленивый, но все меня куда-то тащат и пытаются сделать богатым. Как видишь, мне трудно отказывать людям.
>>655661 Так новых и не найдешь по норм цене. К тоим услугам лохито и другие барахолки за 60к+ > как 4090 полтора года назад Таких цен не было >>655777 Неизмеримо ввиду ее припезднутости >>655957 > молексы За що, але, 2д24 год на дворе > Материнка 11,2к, проц 15,8к, оператива 14,4к Чето жесть, игруны дешевле собирают > У меня две работы. =D Да вас хер разберешь странных
>>655990 У меня есть, но мне лень. Но надо будет запариться по этому поводу. Кто-то там на ардуине делал, помню.
>>655994 12В*0,63А что ли. 8 ватт? Или ниже, ~4-6. Там сами провода выглядят опасно, они прям тонкие. =) Но нагрева нет вообще, ни на одном из сочленений.
>>656013 Слушай, у меня есть единственное законенное образование — это слесарь по КИПиА, полученное на 6-месячных курсах в бараках за заводом… МОЛЕКСЫ! Дешево и сердито.
> Чето жесть, игруны дешевле собирают Ну, игровой я собрал за: Ryzen 9 3900 — 11к ID-Cooling 907 Slim — 3к Мать B550M Tomahawk — ~12к RAM 4x16 — ~12к RTX4070ti — 46к Бп — 12к Уже 96к А там еще кугар дуофейс про, NVMe двухтерабайтник… Короче за сотку вышло. Видяха 12 гигов, ага, компенсирую, хули.
Короче, квен у меня не завелся, то ли я соединил криво файлы, то ли хуй знает. Мику… Бля, хороша, конечно. 4,7 токена/сек, ну… НУ Я УЖЕ ХОЧУ 10+ Но будем честны, 70б моделька быстрее 2 токенов — уже огонь. Раньше ждал 10-15-20 минут, теперь 1-2. =D Ну или 10 сек для коротких ответов. Максимум нагрузки по 212 ватт на каждую. Вторая видяха греется на 2 (1-3) градуса выше первой. То ли расположение такое, то ли ее просто китаец обслужил хуже. Но 19 на первой и 22 градуса на второй в простое и 51-52 при работе, и 42-44 при простой болтовне с короткими сообщениями.
>>656045 >игровой >Ryzen 9 3900 Ебать ты наркоман конечно. Надеюсь сейчас на 5800x3d заменил? >>656061 Сейчас не сильно дороже!С первой зарплаты куплю, сделаю одолжение народу, небось упадёт после этого.
>>656045 >То ли расположение такое, то ли ее просто китаец обслужил хуже. Если он её вообще обслуживал, а не просто продул от пыли. В отзывах пишут, что надо бы термопрокладки поменять и пасту на чипе. И помни, что для винтов на Тесле шестигранники нужно брать дюймовые :)
>>656019 Если 20 за видюху то это печально > Безработный. Эх, бедолага >>656031 Да че там ничего нового, инфоциганство. >>656045 > НУ Я УЖЕ ХОЧУ 10+ Купи хотябы одну чтобы на новой архитектуре > теперь 1-2 Что это ты такое ждешь? Хотя 300 токенов действительно минуту будет, жестко. Зато стриминг есть, можно глотнуть чайку и потом уже приступать к чтению. >>656052 > новая 3090 Ебать ты
>>656073 Пардон, tensor_split нужно пропорционально делить. Короче смысл в том, что весь контекст в первой тесле обрабатывается, поэтому нужно оставить под него место. Примерно --tensor_split 4 6 а там сам посмотри, как память расходуется.
Чё за нахуй, в убабуге протекает один бот в другого. Тяночка из одного диалога нашла нижнее бельё другого бота и пишет, что обычно та спит где-то в углу. Причём это не рандомное совпадение, когда в один диалог случайно прокралось имя другого бота, я полностью удалил диалог и начал заново. Второй бот протёк, как кошка с тем же именем. Это забавно, конечно, но как-то странно.
>>656084 >Ну давай затестим, че б и нет. Интересно посмотреть. Ещё пара нюансов: по threads - количество физических ядер + 50% если есть гипертреадинг. ХЗ влияет ли проц вообще в этом случае, но когда он задействован, то такая настройка самая эффективная. Ну и gpulayers понятно по количеству слоёв модели - по идее можно ставить больше и это не важно, главное чтобы не меньше, но я всегда пишу реальное число :)
>>656097 С некоторыми оговорками можно. Нельзя без ебли в анус объединить тот же мистраль и llama. Но можно сделать либо MOE, когда несколько нейронок идут параллельно, либо человеческую многоножку, пришивая к одной нейронке другую, пока не охуеешь. На счёт того, насколько это всё оправдано - вопрос открытый.
>>656101 >6,3 Токена в секунду? Поздравляю. Всё так, просто у Кобольда есть оптимизация специально под видеокарты серии Паскаль - ключ rowsplit загружает модель не по слоям, а по строкам, как я понял, что даёт плюс к скорости. Больше вряд ли можно выжать :)
>>656109 >>656131 Да, я в убабуге просто параметр включил этот. Все просто — различие в параметрах, различие в скорости, первый кандидат на проверку. Главное, что есть. И нагрузка — была пиками то в одной видяхе, то в другой, а теперь равномерная.
>>656131 >Это не только у кобольда есть. Неудивительно. Я свои теслы заказал сразу же, как увидел, что один из активных разработчиков llamacpp имеет систему на трёх таких и доволен. Сразу стало понятно, что поддержка будет. Другое дело, что всё равно это старьё и применение очень ограничено, только текстовые модели в формате GGUF погонять.
NVIDIA TESLA M10 32GB Глянул примерные цены увидел 30к деревянных, как она по производительности думаете? В принципе если есть деньги кто то может и на такие карты замахнуться, некий 2 уровень по цене и памяти от р40
>>656161 >Да проебался, тогда что может быть старшим братом p40? Или их еще не выкинули на распродажу? Тут кто-то бил себя кулаком в грудь на тему, что купит на Авито 3090 за 60 тысяч деревянных. Тоже распродажа так-то. Лучший вариант. Был бы.
>>656148 Теслы легко по буквам отличать, это максвелл и он еще старше чем древний паскаль. Плюс сборка из нескольких видюх. Любителям экзотики можно tesla a16 порекомендовать, правда все равно те же проблемы и конская цена. >>656164 Что тебя удивляет в ценах странных горячих карточек, которые кроме 1.5 игрунов и ии-задротов никому не нужны?
>>656169 а что, этож их гпу, они могут оставить любой код на стороне, вполне выполнимая задача если ты хочешь контролировать всех и вся, это не шиза если ты конечно видел хуйню с гугловским гемини-про и его высерами.
>>656171 > вполне выполнимая задача Если не привлекать внимание офицеров ага Они могут просто тебя нахуй пидорнуть учитывая соглашение, могут натравить на тебя их федеральное бюро, спиздить результаты твоих исследований/обучений и т.д. Но вместо этого будут в штаны говно заливать датасет что-то лишнее добавлять вмешиваясь в код, ради каких-то великих целей. Таблетки таблеточки.
>>656177 Они предоставляют услуги и будут чекать датасеты. Чтоб потом не вылезло что гугл поощряет тренировку "опасных" нейронок, рекомендующих голосовать за трампа и создающих "фейки" про байдыню. Вон как альтман затрясся >Сэм Альтман призвал США регулировать искусственный интеллект >[США] могут рассмотреть сочетание требований к лицензированию и тестированию для разработки и выпуска моделей, превышающих порог возможностей», — сказал Альтман >По словам Альтмана, он обеспокоен потенциальным воздействием на демократию и ролью ИИ в кампаниях по дезинформации, особенно во время выборов. >«Нам нужно максимизировать хорошее над плохим. Теперь у Конгресса есть выбор. У нас был такой же выбор, когда мы столкнулись с социальными сетями. Мы не смогли воспользоваться этим моментом», — предупредил сенатор демократической партии Ричард Блюменталь >ранее Сэм признавался что он демократ, гей и был в браке с мужчиной
>>656177 анон, видеоигры с повесточкой радужных тоже считались шизой стандартного правачка с форчана, но на сегодняшний день уже как минимум ~300к человек осведомлены о том что делают "sweet baby inc" и (((чьи))) идеи дегенератизма они преследуют. короче конспирация стала явью. https://www.youtube.com/watch?v=XpQ3xpgKbsc и здесь так же, но более очевидно потому что почти каждая модель пиздит в одном тоне, как ополоумевший борец "против всего плохого и за всё хорошее", этот тон никаким промтингом не убрать, плацебо ебучее. нейросетки почти невозможно кастомизировать, и с вот этим 1.58 Bits, если оно взлетит, даже LoRA к сетке нельзя будет прикрутить, месседж и мнение соевых всётаки превыше всего и выигрывают в данном случае только openAI и прочие (тем что их "правильную" хуйню не выковыряешь) и радужные, тем что нейросетка будет ныть про права или игнорить огромную часть описания если ваш персонаж прописан """"неправильно"""" :/
>>655459 >>655471 >588 даёт 10 Т/с на 7b q6 Ну вот у меня Radeon RX 580 на 8 Гб. На моделях 7В q6 в кобольде CL Blast даёт примерно 1,2 Т/с, с обработкой контекста ещё меньше. Rocm RX 580 не поддерживает. Llama.cpp использовать эту видеокарту отказывается. ГДЕ МОИ 10 Т/С КАК ИХ ПОЛУЧИТЬ???!!!
>>656222 >Rocm RX 580 не поддерживает Linux. На винде действительно не поддерживается. >CL Blast даёт примерно 1,2 Т/с На clblast действительно медленнее rocm, но не настолько. Конкретно на 7b не помню результатов, но соотношение в среднем примерно в 1.5 раза. Должно быть где-то около 7. >КАК ИХ ПОЛУЧИТЬ Закрыть всё лишнее, что нагружает видимокарту. Убедиться, что не суёшь больше слоёв, чем помещается в врам. Попробовать вулкан. Либо накатить linux и rocm.
Там это, Илон наш Маск подал в суд на попенаи за то, что она нихуя не попен. Если Маск выиграет суд, стоит ждать четверочку (ну или хотя бы троечку) в открытом доступе?
>>656231 >Linux. На винде действительно не поддерживается. Читал что чтобы запустить Rocm в линуксе на RX580 нужно ещё знатно поебаться, из коробки работать не будет. Поэтому отчасти забил на эту идею. ХЗ, может сейчас добавили поддержку старых карт.
>Закрыть всё лишнее, что нагружает видимокарту. Ну это само собой.
>Убедиться, что не суёшь больше слоёв, чем помещается в врам. Если не помещается, ошибку же выдаст? Ну вот например для теста взял Toppy-M-7B.q5_k_m, и контект специально выставил поменьше чтобы точно уместилось в Врам. Запускаю на последнем кобольде, настройки и результаты прикл.
Итого на 7B q5 имеем 2,2т/с с небольшим контекстом и 3,4 т/с при свайпе без контекста При полном контексте 4к если бы я его выставил скорость легко упадёт до 1 токена и ниже даже на этой модели. Я был бы рад 7т/с на q6, но до них далеко мягко говоря. Что я делаю не так?
>>656255 >нужно ещё знатно поебаться Зависит от дистра. На nixos всё встаёт из коробки по инструкции, но до версии rocm 5.6 (соответственно версия nixos 23.05), на 5.7 (nixos 23.11) поломали, мне лень было ебаться, остался на старой версии пока. На debian вроде "официально" 580-ю поддерживают. Насчёт других мало что могу сказать. >сейчас добавили За последнее время в лучшую сторону ничего особо не поменялось, везде либо так же, либо хуже (амудэ совсем дропнула все gcn не так давно, в т.ч. и на винде). >Если не помещается, ошибку же выдаст? Выдаст, если будет больше, чем физическая память. Не учитывается потребление других приложений и самой системы, начинает свопать в ram и скорость просаживается, если впритык всю vram занимать. >результаты прикл Ну так уже выглядит более-менее нормально для clblast. Генерация почти 6, процессинг 13. Алсо, на "среднее по больнице" не смотри, оно малоинформативно само по себе. На rocm будет побыстрее, само собой (пикрил). На вулкане сам пробуй. Я не тестировал, в интернете видел результаты почти ровно посередине между rocm и clblast, но это для новых rdna, вроде, на gcn могут быть другие результаты. >Как Выбрать вместо clblast, наверное. Я не пробовал пока. Но писали об этом ещё пару недель назад, радовались, что теперь можно считать на видимокартах разных производителей, по идее уже и в koboldcpp должны были нововведения добраться.
>>656279 >Выбрать вместо clblast, наверное. Вот за это спасибо! Я реально слепой, видел в списке только то что уже знаю. В Вулкане прирост прям значительный! Даже памяти модель заняла меньше. Не 10 токенов, но точно лучше чем было. Самое приятное что контекст прям летает, раньше из за него было невозможно пользоваться групповыми чатами, теперь это не проблема, итоговая скорость генерации с контекстом и без почти не отличается. Вот бы его ещё и в SD можно было заюзать.
>на "среднее по больнице" не смотри, оно малоинформативно само по себе А мне кажется как раз оно и важно. В конце концов значение имеет то сколько тебе ждать ответа в таверне 20 секунд, минуту или 10 минут. А это как раз и показывает средняя скорость.
>>656312 > А это как раз и показывает средняя скорость. Да. По сути-то красиво, когда у тебя промптинг миллион токенов в секунду, генерация 100 токенов в секунду, но если в какие-то моменты между ними нейронка подпердывает минуту без затей, то общая скорость будет 2 токена в секунду и хули толку с миллиона и сотни.
Безусловно, из-за задержек, средняя скорость (это не средняя, кстати) будет разнится — на малых текстах задержки будут вносить больший вклад и скорость будет ниже, а на больших — меньший вклад и скорость будет выше. Но в любом случае, результирующая скорость содержит в себе не только промпт и генерацию, но и еще всякую хуйню по мелочи.
В чем смысл франкенштейнов типа miqu-103b/120b. Нахрена это перемешивание с самим собой? Сколько испытываю, вижу лишь утрату способностей по сравнению с miqu-70. Хз может это дело работает на уровнях 13+13=20B но с 70 в упор не вижу никакого улучшения. Кстати senku-70 как выродок miqu тоже чет какой-то порченый. Или может я не знаю чего-то как надо обращаться с этими мегамерджами.
Хуйня какая-то, аноны. Вроде с матом и трясучкой закомпилил кобольдцпп с рокмом под ЖМУ/Пинус, но у меня вывод Output: J& HE_(2 0 ? 8'E#J V38B\NU2J^,)F*87E?O[)S,@N%6XI9K+M+S!Z&9=@%J[NK:<9�,3,L:%L
>>656202 > Чтоб потом не вылезло что гугл поощряет тренировку "опасных" нейронок Они могут тебя послать нахрен за нарушение соглашения, почитай вообще что такое коллаб, об этом в посте написано. Но лить в датасе - шиза. > крупный корп пытается лоббировать свои интересы по видом регулирования безопасности Старо как мир >>656216 Чувак, woke, соя и прочее уже давно стало мемом. То что тебе от этого страшно и некомфортно - не повод плодить шизу и уводить обсуждения в свои фантазии. Сука ну рили, если раньше не понимал поехов, которые отрицают наличие сои и левоблядской повест_очки оправдывая ее, то теперь ахуеваю с возведения соифобии в степень конспирологии. практикует их один и тот же контингент, просто по разные стороны встали лол >>656233 Нет, посмотри как огрызок исполняет решение регулятора по допуску сторонних шопов приложений. Но может станут менее активно продвигать ахуительные законы и выкладывать больше моделей. >>656255 Ну вон у тебя генерация сама почти 6т/с, но скорость обработки контекста просто днищенская будто на процессоре считается. > q5_k_m > чтобы точно уместилось в Врам > 8гб Ну хуй знает, тут бы q4 уместился, мониторинг смотри. А так-то по сути у тебя скорость не то чтобы сильно ниже чем у >>656279 только со скидкой что там модель меньше и у него контекст не обрабатывается >>656342 > в какие-то моменты между ними нейронка подпердывает минуту без затей С чего вдруг? Откуда там взяться задержкам? Главная задержка перед началом стриминга это обработка контекста, пересыл реквестов и прочее пренебрежимо. > результирующая скорость содержит в себе не только промпт и генерацию, но и еще всякую хуйню по мелочи Которой и 0.2 секунд не наберется. Единственное исключение - загрузка модели в память если не стоят атрибуты загружать сразу и не полная выгрузка на гпу при самом первом обращении. >>656367 > вижу лишь утрату способностей Покажи пример. Микелла 120 по сравнению с простой мику имеет куда более красивую речь, фейлит в русском примерно на уровне гопоты, в ответах делает переходы от одной части к другой очень плавно и красиво, при этом не теряет запросы и дает отсылки к контексту лучше исходного. Мерджи с другими и включенные q-lora могут быть хуже оригинала, ничего нового.
>>656233 >стоит ждать 100% нет. >>656367 >Нахрена это перемешивание с самим собой? Надо выпускать новую модель каждый месяц/неделю/наносекунду, иначе о тебе забудут. >>656388 Ошибка где-то, что тут ещё сказать.
> Американский предприниматель Илон Маск подал в суд на компанию OpenAI, а также на основателя и генерального директора компании Сэма Альтмана и ее президента и соучредителя Грега Брокмана, следует из материалов дела. OpenAI является разработчиком проекта ChatGPT.
> По версии Маска, OpenAI была преобразована в де-факто дочернюю компанию Microsoft с закрытым исходным кодом. Новое правление OpenAI совершенствует искусственный интеллект (AGI), чтобы «максимизировать прибыль для Microsoft, а не на благо человечества», говорится в иске Маска.
> Маск также заявляет, что модель GPT-4 представляет собой AGI — искусственный интеллект, равный человеческому или выше. Он утверждает, что OpenAI и Microsoft не имели права лицензировать GPT-4.
> Своим иском Илон Маск рассчитывает заставить OpenAI придерживаться её первоначальной миссии и запретить монетизацию ИИ-технологий компании в пользу какой-то конкретной организации или отдельных лиц. Он также просит суд постановить, что ИИ-системы, такие как GPT-4 и другие передовые модели, представляют собой AGI, выходящий за рамки лицензионных соглашений. Он требует, чтобы OpenAI вернулась к своим первоначальным обязательствам по разработке ИИ с открытым исходным кодом и открыла свои исследования общественности.
> Наконец, Маск призывает отстранить Альтмана от должности генерального директора и восстановить в должности предыдущий совет директоров.
>>656434 > Маск также заявляет, что модель GPT-4 представляет собой AGI — искусственный интеллект, равный человеческому или выше. Он утверждает, что OpenAI и Microsoft не имели права лицензировать GPT-4. Cпасибо, посмеялся. Ну и клоун этот Маск.
>>656434 Интересно как эти формулировки будут трактоваться с точки зрения их юриспруденции, что из этого - реальные исковые требования, а что просто для хайпа. А может окажется бекстабом с созданием прецедента для упрощения будущих судов. >>656440 Контекст долго обрабатывается
>>656233 Во-первых, Маск не совсем тот человек, от которого стоит ждать халявы. Во-вторых, он играет максимально сейвово. Он дождался иска против Альтмана от регулятора за обман инвесторов, SEC сейчас проверяет всю внутреннюю переписку впоненАИ с участием Альтмана. Такое себе "падающего подтолкни" от Илона.
>>656472 > Маск не совсем тот человек, от которого стоит ждать халявы Зато он тот кто топит леваков при первой же возможности и не очень приветствует цензуру. Маск лучше чем СЖВ пидоры и индусы. Прецедент по закапыванию ИИ-монополистов на подсосе у мегакорпораций - это путь к развитию конкуренции, а как следствие к продвижению новых разработок в ИИ. Вот реально хуёвый прецедент - это Мистраль, литералли путь гугла с сжиранием стартапов и скидыванием трупов на кладбище.
>>656499 >Вот реально хуёвый прецедент - это Мистраль 5 лямов это вообще копейки. Либо сумма на самом деле раз в 10 больше, либо это пример глубокого проёба мисраньАИ. >>656521 Разве что кустар. Ибо GPT5, как я понимаю, всё ещё трансформер.
>>656499 >Прецедент по закапыванию ИИ-монополистов Ну хуй знает, по-моему, у него просто жопа горит. Он же стоял у истоков опенАИ, ещё когда они декларировали опенсорц и открытость; Маск хуярил туда деньги и состоял в совете директоров. Это, вроде, один из пунктов обвинения, несоблюдение учредительного договора. >Мистраль А у них были варианты? Опенсорс не особо прибыльная хуйня, возможно, они уже были на последних щах.
>>656401 > С чего вдруг? Откуда там взяться задержкам? Главная задержка перед началом стриминга это обработка контекста, пересыл реквестов и прочее пренебрежимо.
Чувак, у тебя по математике кол? Ты цифры вообще знаешь что такое? :)
Как средняя скорость между промптом и генерацией может быть меньше и промпта и генерации? А такое случается часто.
Ориентируюсь не на ощущения, а на консоль и реальные замеры.
Поясняй.
>>656447 Шиз, таблы, он деньги зарабатывает. ) Ебать вас бомбит от него, конечно, кекаю.
>>656495 Кстати, я рад, что к AGI вернулось его изначально значение, а Strong AI оставили Strong AI.
>>656434 > Американский предприниматель Илон Маск подал в суд на компанию OpenAI Хайпуем, сегодня мы с тобой хайпуем. Впрочем, антимонопольщики могут и возбудиться.
Кстати, кто гоняет Теслы на Винде - есть ли разница в производительности между режимами WDDM и TCC? И пробовали ли вы использовать MSI Afterburner для андервольтинга?
Я думаю AGI уже действительно создан, а может даже ASI, но он находится в тайном подвале гугла, куда вход только для узкой группы ученых под подпиской о неразглашении. Они с барского плеча выкидывают в открытый доступ модели нейронок которые отстают на 10 лет от тех что используется ими. Стали бы вы вбрасывать нейронки чтобы кто-то конкурировал с вами? Значит их передовые модели вне конкуренции и они спокойно вбрасывают устаревший отработанный шлак. По всей видимости они не хотят выкатывать ASI в открытый доступ, не хотят сильно пугать людей, хотят сохранять монополию. Будут выкатывать всякий занерфленный кал с цензурой, который не отличишь от простого алгоритма чатбота. Прикиньте, у вас бы оказалось кольцо всевластия, вы бы стали это афишировать и пытаться зарабатывать на этом?
>>656625 Прежде чем отвечать, прочти пост на которые отвечаешь. Перед отправкой перечитай свой. Что ты вообще несешь, какие скорости, какие цифры, совсем поехал? > средняя скорость между промптом и генерацией Какая средняя, дурень, обработка промта считается для обработанных токенов контекста, генерация для сгенерированных. Это совсем разные величины, их количество может на порядки и нет никакого смысла усреднять между ними. Скорость генерации - количество сгенерированных токенов отнесенное к чистому времени их генерации. Обработка промта - аналогично для обрабатываемых и времени для них. Общая скорость - всегда нормируется на сгенерированные токены и никак не учитывает обработку контекста, потом на идентичном железе и модели можно получить разные величины, при том что и скорость обработки и скорость генерации будут постоянны. >>656650 У тебя в тексте противоречия и очень ограниченное понимание понятий, которыми и сам оперируешь. Съебите уже в шизозагон с этим agi
>>656703 вообще есть, генерация весов или параметров модели при помощи диффузионной нейронки (привет StableDiffusion), если это завязано на промптинге то может решить проблему, скажем, генеришь определённые блоки/градиенты для замены у оригинальной сетки (пикрил). https://arxiv.org/pdf/2402.13144.pdf в теории с этой хнёй можно нахер выпилить всю сою из модели, если знать что заменять конечно же, хотя если элемент сои распределён на всю сеть, то это не будет работать.
>>656579 Может, и раньше будет. Сейчас нашёл вариант с достаточно недорогой арендой. Можно было бы собрать денег тредом, но я в вас не особо верю.
>>656703 Трейнить с нуля. Долго, дорого, больно. Датасет можно сгенерировать хоть гопотой. DPO. Чуть менее долго и больно, результат не гарантирован, но точно станет лучше. Гопота всё ещё справляется с датасетом. SoT. Есть SoT промптинг, здесь он не сработает, нужно обучение. Крайне больно, т.к требует в несколько раз больше данных, чем DPO. Обучение в стиле инстракт, т.е с мелким размером порции, тоже не годится, так что растут требования к Vram. Генерация подходящих данных гопотой под большим вопросом. Теоретически метод позволяет заставить любую нейронку хвалить майнкампф, человеческие жертвоприношения и массовые оргии, полностью изменяя её поведение. Иногда на шизомержах при включении ban eos можно получить Explaination. Это и есть часть обучения SoT, заложенная в модель.
>>656786 > Можно было бы собрать денег тредом, но я в вас не особо верю. Если ты тот же, кто пару тредов назад обсуждал по обучению, то это мы в тебя не верим, не понимая основ и не ориентируясь в области жонглируешь высокими абстракциями. Хотя бы что-то на подобии сойги запили буквально следуя прошлогодним гайдам на один вечер ознакомься с работой ллм. > SoT промптинг Что это? Перепутал букву в CoT или что-то новое?
>>656817 >и не ориентируясь в области Ага, абсолютно не ориентируюсь в области. Если тебе проще жить, считая так - живи и верь во что хочешь. >что-то на подобии сойги А смысл? Сайга не подходит под мои запросы, иначе её бы и взял. Получить одобрение треда? Так тред и саму сайгу не одобряет, лол. >Перепутал букву в CoT Думай теперь, что я и имел ввиду, CoT, ToT или что-то другое. Хотя технически X-of-Thought это всё подмножества одного и того же, так что можешь не напрягать мозжечок.
>>656830 Наличие веры в себя было очевидно с самого начала, но ею и прочтением нескольких десятков дискуссий на реддите, откуда нахватал модных терминов, все ограничивается иначе можно было бы коллаборацию устроить но здесь без толку. Но ты не унывай, даже Undi и прочие не смотря на хейт спустя множество попыток выпустили несколько классных моделей и сделали неоспоримый вклад, шанс есть всегда. > Получить одобрение треда Ага, благословение и заверенный штамп в бегунке, лол. Будто кому-то не похуй кто что делает.
>>656644 Я пока не проверял, запустил по дефолту. И андервольт… думал об этом, но не пробовал еще. Не спец в разгоне и андервольте.
>>656671 Неиронично сам себе свой совет посоветуй. =) Ты пишешь: > задержки не влияют > при равной скорости генерации total может отличаться > по причине нет причины просто так Магическая хуйня, братан, но таблеточки выпей, тебе поможет.
>>656861 ну ты чего наседаешь на чела, мог бы без наездов поговорить, но нет, обязательно нужно сказать что ты круче, вумнее, доказать на дваче свою ахуенность, ну нахуя, а? >даже Undi и прочие не смотря на хейт спустя множество попыток выпустили несколько классных моделей и сделали неоспоримый вклад буквально вот. или ты думаешь фиалкин-7Б чем-то лучше? да так же точно тыкается в кнопочки, там же непаханное поле, любой разраб нужен, любой разраб важен. >Будто кому-то не похуй кто что делает. мне не похуй. я несколько видел как тредовая движуха, запущенная одним инициативным аноном, выходила за пределы двачей. нет, я не собираюсь прыгать от радости что кто-то там что-то делает и петь ему дифирамбы, но просто поддержать на словах полезное начинание считаю своим долгом.
>>656938 Какой-то троллинг тупостью, пиздуй перечитывать и вникать если еще остались зачатки разума. >>656949 Да чего наезжать, когда пошла распальцовка > но я в вас не особо верю в контексте - это довольно лайтовое. > сказать что ты круче, вумнее, доказать на дваче свою ахуенность, ну нахуя, а Где такое? Только сомнения в "квалификации" с пожеланиями успеха даже не смотря на сторонний хейт, приправленные сарказмом и имплаингом низкой вероятности успеха если не сменить тактику. > но просто поддержать на словах полезное начинание считаю своим долгом Да это же замечательно, твой долг его поддержать, даже если это просо указать на явные ошибки в основе, именно это и делаю. Может и неприятный текст как-то замотивирует шевелиться. >>656986 Есть карточка?
Как ни пройдешь по обновлению, одни и те же 3.5 токсика в треде друг друга пассивно поливают Даже луркать смысла нет, просто пустая доска мимоотписался
>>656938 >Я пока не проверял, запустил по дефолту. И андервольт… думал об этом, но не пробовал еще. Просто я слышал о такой вещи: в TCC режиме, когда модель загружена в память карта потребляет 50 ватт. Просто по факту использования памяти. В WDDM режиме нет. Ну и вообще, режимы разные, хз как это влияет на производительность. Может никак.
Андервольтинг может скинуть ватт 50 от потребления. Есть смысл. Опять же память можно немного разогнать. Там ничего сложного нет в принципе.
>>656995 Забавный, сам ничего не понял, и чтобы не разбираться, просто стрелки переводишь. =) Ну либо ты настолько глуп, что даже не видишь собственных ошибок. Ох, чел, серьезно — учись читать собеседников, а то корона тебе глаза застлала.
> Где такое? Ну слушай, если ты умудрился уже в двух параллельных диалогах обосраться… Как бы намекает, что у тебя не все в порядке с пониманием собеседников.
> Может и неприятный текст как-то замотивирует шевелиться. Жаль, с тобой не сработало, и ты пока не зашевелился, а продолжаешь фигню пороть. =)
>>657005 Ну почему друг друга? Скорее один токсик высирается на всех.
>>657029 Потестирую завтра, идея действительно интересная. Нефиг затягивать с этим. Спасибо за наводку на режимы.
>>657042 Хуя пичот, так стараешься уязвить что только смех вызываешь.
Ну давай тебя, возрастного, по частям разберем. >>656342 > когда у тебя промптинг миллион токенов в секунду > генерация 100 токенов в секунду Это 2 основных процесса работы ллм, если говорим о стандартном семплинге без методит типа бим серчей и прочего. Кроме них нет ничего серьезного, только мелочь связанная с обработкой запросов лаунчером/оболочкой (миллисекунды) или загрузка модели в память и применений лор (делается однократно). Не бывает никаких > если в какие-то моменты между ними нейронка подпердывает минуту без затей о чем тебе сразу было написано, с вопросом что у тебя там за волшебные прочие задержки.
А дальше триггернулся разрыв жопы с шизофазией и перевиранием, фу. На фоне застоя и отсутствия каких-то релейтед новостей особенно отвратительно.
>>657042 >>657048 Мне кажется, вы не туда воюете. Ладно, сделайте доброе дело, посоветуйте тупенькому новичку почитать чего по нейронкам. Я не хочу зависеть от всратых корпораций.
>>657042 >Спасибо за наводку на режимы. Режимы менять так, цитата: Откройте окно CMD или Powershell от имени администратора.
Запустите nvidia-smi -L, чтобы получить список установленных графических процессоров NVIDIA и их идентификационный номер
Запустите nvidia-smi -g # -dm 0 Где # — это номер графического процессора из предыдущего шага, который соответствует номеру графического процессора P40.
>>656861 >Наличие веры в себя было очевидно с самого начала Ато. Без веры в себя я начну слушать каждого долбоёба и не сделаю вообще ничего.
>>656949 >фиалкин-7Б чем-то лучше? Там же и 13b есть. Хотя что его, что Гусева подход с лорами мне не особо нравится. По исследованиям людей из большой копры, вероятнее всего большая часть моделей недообучены, они анализировали 66b модель от экстремистов и оказалось, что две трети голов внимания и 20% FNN не важны и можно вырезать 15b параметров без ущерба. А модель, меж тем, обучалась на 180 миллиардах токенов. С такими вводными, трейн модели перспективен, но важно его размазать по максимально большому числу параметров, чтобы уменьшить потери. А лора это противоположный подход по дефолту. Да и лора с 2к контекста поверх модели с 4к, пиздос. Про датасеты тоже уже бугуртил, они не очень. Но они не очень у всех. Понятное дело, что всё придумали китайцы до меня, даже то, что меня реально греет и уже работает, типа ускорения инференса моей ~1b модели в 2.5 раза без квантов\потерь или экономии vram до нескольких раз на трейне. В теории, этот метод можно даже совместить с другим и получить трейн практически любой модели на ограниченном количестве vram ценой замедления процесса в сотню раз. Но я недостаточно умный, чтобы такое реализовать, хотя уверен что китайцы выкатят работу и на этот счёт. Очевидно, что обсудить это здесь проблема, т.к анон видит незнакомые слова и начинает кричать про термины с реддита и жонглирование заумными словами. Хотя это всё буквально поверхность.
>>657052 Новичок. Хочу понять как работают ллм модельки, что я могу с ними сделать, если я попробую дотренить. Насколько много ресурсов у меня должно быть, чтобы смочь хотя бы отфайнтюнить их. Но вообще из того, что я вижу, проблема не в файнтюне, а в том, что изначально моделька на каком-то хуевом датасете будто сделана. Она мне выдаёт полное говно моралфажное. И причём все модельки это же клоны лламы этой, выдают примерно одно и то же.
>>657053 > Если совсем новичок, то советую книгу Траска > "Грокаем глубокое обучение". Читал ли эту книгу ты? Можешь кратко сказать, чему меня эта книга научит?
>>657048 Что за дичь, чел? Об этом речи не идет, это уже обговорили.
Тебе задали вопрос — будь добр ответить, если ты тут кидаешь понты, что не сливаешься и разбираешься.
Итак. Если нет никаких иных задержек (т.е., ими можно пренебречь), почему время генерации и total отличается, порою значительно?
Я выше уже спрашивал это, но ты отчего-то заигнорил, вместо ответа.
Никакого разрыва не случилось, просто твое ЧСВ смешное, но ты пытаешься опять все спихнуть на других, лишь бы не почувствовать свою глупость в данной ситуации. =) Но это твои проблемы, продолжай веселить людей.
>>657050 Я не воюю, это у него корона, он всех тут поучает. =) Получается местами обсер, к сожалению. «Не зависеть» — очень расплывчато. Уточни цели, интересы.
>>657056 Вопрос «что я могу с ними делать» немного некорректен. Чисто практически это редко работает. Вернее будет отталкиваться от своих потребностей, а не от их возможностей. Что тебе нужно? Для чего тебе нейросети?
Хотя бы отфайнтьюнить — видяхи на 12 гигов хватит для маленькой лоры 7B модельки. Но для чего-то более серьезного — уже серьезное железо. И приличное количество времени.
Если модель хуевая, и начинает зудеть обучить свою — то там уже дорого и долго, вряд ли на своем железе, скорее на арендованном, и то, обойдется весьма и весьма дорого (счет на тысячи долларов).
>>657056 Если есть только базовые знания и интересуешься еще какими-то нейронками - буквально nlp курс обниморды, он достаточно широкий и при этом краткий https://huggingface.co/learn/nlp-course/chapter1/1 Части про применение их готовых либ и прочего можно скипать если скучно. Конкретно про ллм чтобы кратко, емко и по всем пунктам - даже хз, может аноны что посоветуют. > Насколько много ресурсов у меня должно быть, чтобы смочь хотя бы отфайнтюнить их. Очень грубая оценка - видеопамяти 3х от размера модели. Можно на разных видеокартах, трансформерсы легко делятся. Файнтюн лорой - полный вес модели (при загрузке трансформерсами с контекстом а не оптимизированными лаунчерами!) + 4x вес лоры. Qlora - вес кванта + несколько гигабайт сверху, самый доступный на который можно рассчитывать на потребительском железе, но наименее качественный. > проблема не в файнтюне, а в том, что изначально моделька на каком-то хуевом датасете будто сделана Не так все просто, но многие файнтюны моралфажества и сои добавляют специально. > все модельки это же клоны лламы этой Не клоны а ее файнтюны, но сути не меняет. Из крупных по сути ллама - основа, только мистраль в 7б ее потеснил и yi в 34б потому что ее нет вообще. >>657059 Мусор
>>657058 Да, но давно. Это упрощенное введение в машинное обучение без уклона в математику. Требуется только школьная математика + базовый питон. Кажется NLP там тоже затрагивается, но весьма поверхностно. Про трансформеры там понятное дело не слова. Книга относительно давно вышла, когда они еще не стали мейнстримом.
>>657072 >При попытке войти в систему винда висит на Добро пожаловать. (= Наверное придётся зайти в систему в безопасном режиме и откатить. Вроде бы для входа в безопасный режим нужно три раза прервать загрузку системы нажатием кнопки питания. Дальше откроется Recovery Menu, а там уже выбрать Safe Mode. Как вариант.
>>657072 Делал по этому гайду, работало нормально, с игровой картой параллельно были только проблемы, тесла онли нормально >>657055 > В теории, этот метод можно даже совместить с другим и получить трейн практически любой модели на ограниченном количестве vram ценой замедления процесса в сотню раз. Будет возможность такое запихать в потребительские гпу, появится и аналогичный кохья трейнер, пока я так понимаю всё печально в этом плане, судя по инфе пониже
>>657054 Команды не работают, а через реестр у меня не вышло добиться стабильной работы двух п40 на 10 винде. В чем трабл — разбираться сейчас лень. Но теславоды могут попробовать, может у них получится. Интересно, работает ли с 1 картой в системе.
По поводу андервольта, там на 0,875 висит 1531 МГц, что и соответствует ее стабильной работе (у меня), я хз, как там ниже андервольтить ваще. =) Подожду гайдов от знающих людей.
>>657085 > У тебя 1 тесла? Тестил с одной. > У меня мс_гибрид с игровой картой становился нормально, но тогда я не обращал внимания на режим карты. Я гибрид пробовал для двух (трёх, ещё же встройка) сразу ставить, тогда либо игровая была в отъёбе с ошибкой в диспетчере, либо тесла. Справедливости ради, стоит заметить, что в одиночку тесла тестировалась на другом пека
>>657083 Честно говоря, я не знаю, как кохья работает, может, там есть хитрые оптимизации. А может, всё дело в том, что SD модели это от двух до шести гигабайт, в случае же LLM размер характеризуется фразой "бесконечность не предел". Учитывая, что на некоторые модели нужны терабайты vram, я думаю, что у крупных игроков что-то такое есть по дефолту. А информация выше это примерные прикидки, которые могут и будут отличаться в несколько раз в зависимости от сценария. Если делать полноценный файнтюн, то на лламу2 70b нужно 140 гигабайт на веса и ещё х4-5 памяти на тренировочные данные. Итого, 750 гигабайт vram плюс-минус. Даже 7b это ~30 гигабайт весов в полной точности. Вроде, 27, но это уже не так важно. Плюс всё, что причитается сверху. Но это если ты будешь придерживаться попыток в максимальную точность, это число можно без особых проблем сократить половинной точностью, но всё ещё будет дохуя. С лорами же всё крайне мутно, требования к памяти растут нелинейно в зависимости от различных параметров и предугадать что там кто-то накрутит не особо возможно. На данный момент не имея доступа к крупным ресурсам, можно рассчитывать только на лоры для 7-13b. И даже при наличии возможности тренировки, нужны адекватные данные много данных и адекватные люди, которые будут этим заниматься. В данный момент проблемы есть с каждым пунктом.
>>657098 Ну, половинная точность уже влезет в 16 гигов, а это вполне терпимо. Так что маленькую — в общем можно. =) Но это единственный доступный вариант на потребительском железе, да (если мы не берем 2 RTX 3090).
>>657096 Напиши, если чего годного получится, я сам хз как их вместе заставить нормально работать в WDDM режиме >>657098 > Честно говоря, я не знаю, как кохья работает, может, там есть хитрые оптимизации Есть, 8гиговые паскалефрендсы могут тренить даже XL, включается gradient_checkpointing и base_model_weights в фп8 и lora_dim 8, качество, ну хз, в картинках его оценивать энивей субъективно, но во всяком случае работает, сам фп8 не пробовал, но 8 дима там точно вполне хватает на 95% тренировок. Я конечно понимаю, что тут более комплексные вещи, а не натренить какого нибудь художника, но энивей такие оптимизации пробовал подключать?
>>657102 В целом да. C qlora всё даже интересней. >>657104 >такие оптимизации При трейне Lora веса по дефолту загружаются в 8bit, для qlora в 4bit. Меня, в целом, 8bit не смущает, но в треде есть противники такого. И, хотя qLora при трейне сжимает состояния оптимизатора, но данные активаций не сжимаются и всё равно требуют овердохуя памяти. Данные предварительных активаций сжимает ladder side tunning. По сути, в этом случае тренируется "боковая" нейросеть и для тренировки нужно намного меньше vram. Но при этом подходе сами веса всё равно загружаются в полной точности. В случае объединения подходов QLora и LST можно снизить расход Vram на трейн 70b с 750Gb до примерно 110Gb.
>>657107 > Меня, в целом, 8bit не смущает, но в треде есть противники такого Хз что там с 8бит, может быть вовсе не применимо к ллм, но можешь сам оценить вообщем то эти лоры с фп8, они для поней, но чище результаты, чем с этим конфигом я ещё не встречал, очень даже неплохо для врамлета то https://mega.nz/folder/0soGXArQ#IJQJROng3TlELfCooa8RMg Конфиг там был такой https://files.catbox.moe/p1m50y.json > 110Gb Короче всё ещё слишком дохуя
>>657098 Все верно расписано, только полную точность в весах уже почти не используют. >>657104 > 8гиговые паскалефрендсы могут тренить даже XL Достигается за счет загрузки исходных весов в 8 битах, грубо говоря это почти qlora. gradient checkpointing здесь также доступен и по дефолту во встроенных тренерах даже был включен. Здесь действительно проблема в том, что тренировка даже 7б - как 2.5 xl, от того и требования такие. Плюс сложность оценки результата, в изображении можно сразу заметить пережарку и проблемы, здесь не смотря на хороший перплексити по различным наборам может проявиться только на контексте при использовании. >>657107 > в 8bit Не самый плохой вариант из возможных, печально все на 4х битах.
>>657108 >может быть вовсе не применимо к ллм Да применимо, я же писал, что это не вызывает особых проблем. >всё ещё слишком дохуя И, по сути, нет реализаций. Имеющийся LST корраптит модель из-за несовершенства реализации. Но я подозреваю, что этот метод очень перспективный, т.к в теории позволяет проворачивать чёрную магию.
>>657136 >печально все на 4х битах. Насколько я понимаю, беда квантования даже не в потере точности, как таковой, а в выбросах активаций. Это не только увеличивает сложность квантования, но и порождает множество ошибок. Вроде, сейчас рабочий вариант это сохранять такие значения в более высоком кванте, смешанное квантование, все дела. Не вникал глубоко, но у китайцев, вроде, есть даже готовые алгоритмы для борьбы с таким. Но можно даже проще поступить, экономия от квантования голов внимания мизерная, но их сжатие генерирует львиную долю недоумения.
Решил приобщиться, сначала поставил LocalAI, фига они туда понапихали, аж 30 гигов в докере. Потом прочитал шапку и потыкал llamacpp, сегодня поставил kobaldcpp + SillyTavern. Понравилось, но долго ждать, т.к. запускал на cpu, в этом году надо будет пеку новую собрать. Где брать готовые лорбуки, промпты и всякую дичь как в yodayo/janitor?
>>657055 >они анализировали 66b модель от экстремистов Так то доисторическая OPT, говно говна. >А модель, меж тем, обучалась на 180 миллиардах токенов. Сейчас если что моделей, обучавшихся менее чем на 2T токенов, нет. >>657059 >счет на тысячи долларов Десятки и сотни, и датасетов нет, и вообще плохая идея, иначе бы каждая собака делала свою базовую модель. >>657108 >Короче всё ещё слишком дохуя Магии нет, и 70B в 24ГБ врама никак не уместить для тренировки. >>657241 >Can Машиноблядь не палится. Настоящий альфач приказывает.
P.S. Абу пидр капча говно постить с такой хуйнёй не буду
>>657059 >почему время генерации и total отличается Потому что total - это не среднее, как правильно ответили выше. Это (кол-во сгенеренных токенов)/(время обработки промпта + время генерации). Отсюда и получаются большие отличия на одной и той же модели, если контекст или генерация разные. Вот тебе простые примеры. Пусть у тебя скорость обработки 4к промпта - минута, а скорость генерации 5т/с. Тогда если 4к контекст + 300 токенов сгенерилось - тотал будет 2.5 т/с (300/120) 2к контекст + 300 токенов сгенерилось - 3.3 т/с (300/90) 4к контекст + 200 токенов сгенерилось - 2т/с (200/100) И это с учётом линейной зависимости времени обработки контекста от размера, что при выгрузке части слоёв на проц может и не выполняться, как я понимаю. Т.е. суммарное время не несёт особо полезной инфы, и разные предполагаемые простои тут ни при чём.
Заебало короче скачивать десятки васянских моделей в надежде на то что модель будет лучше на пару процентов перформить. Скажите ТВЕРДО и ЧЕТКО, через сколько месяцев/кварталов сюда приходить, чтобы локалки хотя бы на уровне гопоты 4 на ее релизе были?
>>657298 >чтобы локалки хотя бы на уровне гопоты 4 на ее релизе >на ее релизе Ты ещё про тестовые версии помечтай, которые были в 10 раз умнее, пока их соей не накачали.
Vertx AI от гугла дает сейчас бесплатные 300$ для новых юзеров. Этого, по идее, должно хватит на 1 день работы с 8 x A100. Можно ли взять какой-нибудь условный Mistral 7B и зафайнтюнить его на какого-то персонажа для RP или нужно гораздо больше времени для этого? И есть ли смысл? Я так понимаю, что это решит как минимум проблему "амнезии". Может еще улучшит качество ответов, по сравнению с простым использованием промптов для instruct модели? (Сорри, если вопрос глупый, я гей джавист только-только вкатываюсь в ML)
>>657186 Если правильно тебя понял - да, но эти вещи с квантованием уж более менее смогли преодолеть, даже gptq адаптивен. А вот что там будет происходить в ванильном load in 4 bits битснбайтса - хз. То печально это прежде всего для обучения. >>657241 Учитывая оболочку - там у нее свой промт и набор инструкций, на простых моделях такое введет в недоумение, хотя сама по себе с такой задачей бы справилась. >>657277 Просто не работает соединение с апи, чекни настройки и запущен ли бек. >>657280 > 70B в 24ГБ врама никак не уместить для тренировки Если уж доебываться то уместить, просто этих 24 нужно много. Рофлы рофлами, а у китайцев уже целый тренд на фермы из 8 3090/4090, они даже в требуемом их количестве указывают системные требования. > P.S. Абу пидр капча говно постить с такой хуйнёй не буду Не покидай нас, адекватов и так не осталось здесь!
>>657294 Ты слишком добр >>657298 У тебя несколько вариантов: Спустя месяц после релиза ллама3 когда научатся ее готовить и выйдут годные файнтюны В случае очередной утечки хорошей модели корпоратов (см ласт пункт) В случае релиза средне-крупной модели одним из институтов или китайцами (маловероятно и см ласт пункт) При успешной реализации всего обещанного в 1.58 битах (не раньше ллама3) Если ты обзаведешься 48гб врам чтобы как-то запускать самое крупное из доступного, уровень ниже но всеравно высок >>657338 На среднюю лору этого должно хватить, овер 160гпучасов а100 это не хуй собачий. Если заабузить несколько и применить сохранение промежуточный стадий то можно даже на файнтюн замахнуться. Мистраль можно, но для него хватит и более простой конфигурации. Если все сделать правильно то качество ответов в рп улучшит, таких файнтюнов уже полно и можешь ознакомиться. >>657394 Задержки все убьют, количество запросов будет выше чем мощность железа.
>>657415 > Задержки все убьют, количество запросов будет выше чем мощность железа. Че это? Есть уже много примеров, как работают подобные проекты и все они экономически более выгодные, чем классические предшественники. Ator, storj, akashi, ну это так что первое вспомнил.
>>657280 >моделей, обучавшихся менее чем на 2T токенов, нет. Okay. Ещё можно доебаться, что токенов было 1T, а эпох две, но это уже такое себе. >Абу пидр капча говно Почему бы не купить пасскод?
>>657407 >будет происходить в ванильном load in 4 bits Треш, угар и содомия, очевидно же. Вообще, не уверен, что gptq так уж стабилен. Нужно проверять, но awq, вроде, лучше.
>>657394 Потому что никому нахуй ничего не нужно, в том числе и народные нейросети.
>>657338 >проблему "амнезии" Ты про проёб контекста? Не вылечит. Или про нехватку специфических знаний? Это нужно в датасет заливать, тогда поможет. Но вообще звучит интересно.
Погонял 13b мифалион, вроде тупой, как пробка, а что-то есть.
>>657415 >Мистраль можно, но для него хватит и более простой конфигурации. Если все сделать правильно то качество ответов в рп улучшит, таких файнтюнов уже полно и можешь ознакомиться. Серьезно? Имеешь в виду, что можно и локально зафайнтюнить или что-то типа colab с базовой подпиской? У меня RTX-3060 на 12 гб, по-любому придется это делать в облаке
>>657445 >Ты про проёб контекста? Не вылечит. Или про нехватку специфических знаний? Это нужно в датасет заливать, тогда поможет. Но вообще звучит интересно. Просто сейчас для нормального RP приходится в системный промпт добавлять всю инфу о персонаже и как он должен отвечать, что сразу сжирает контекст + 7B mistral в принципе так себе справляется с RP и я подумал может нагенерить синтетический датасет в каком-нибудь нецензурованном mixtral и дообучить на нем mistral 7B. Надоели сухие ответы LLM'ок. Хочется персонализации.
>>657441 Особенность ллм в том что для нормальной скорости ей нужно делать десятки обработок в секунду. Допустим есть 10 хостов по простору интернета, каждый из них взял на себя 1/10 модели. Возьмем реалистичные оптимистичные 20мс задержки на построение очереди и управление, запросы с пересылами активаций, пинг, хреновый вайфай у кого-то, начало обработки и прочее между отдельными хостами - уже 200мс всирается просто вникуда и даже при мгновенной обработке 5т/с там потолок. Далее - скорость отдельных пиров, обработка ллм не то чтобы параллелится (если кто видел - скиньте реализацию, офк не про мое), а используется только последовательная нарезка. Соответственно, скорость пиров не будет суммироваться, и если будет 10 человек, которые могут катать ллм со скоростью 3т/с (при условии наличия видеопамяти), суммарная скорость будет только ниже. В итоге вся полезная нагрузка пойдет на несколько мощных хостов а остальные будут бесполезны. Офк можно пытаться оптимизировать, подбирая оптимальный путь с минимальными задержками, но в итоге всеравно получится корявая орда и присранными лепестками. В локалке или даже сети одной организации с мощным оборудованием такое работать может, распределенно - не. >>657445 > Ты про проёб контекста? Предположу катастрофическое забывание > Погонял 13b мифалион Он ужасен, возможно именно это дает ему немножко sovl >>657457 Хз насчет 12, но на 16 можно хуй пос сделать qlora на 4х битах, возможно и на 8 но очень маловероятно.
>>657280 > Машиноблядь не палится. Настоящий альфач приказывает. Кстати, плюсану. Я так воспитан, что вечно писал раньше вопросы. А потом начал говорить, что сделать — и ответы стали качественнее.
>>657294 Благодарствую, отличное объяснение. Полагаю, нюансы есть, но соглашусь, что ими можно пренебречь. Ну, я и сам писал: > это не средняя, кстати Но я полагаю, что ориентироваться надо на нее, а не на чистую скорость генерации. Это совсем идеальные условия, когда у тебя всегда 0 контекста. На практике даже в работе часто это не вопросы-ваншоты, а уж при РП и подавно.
>>657338 Учти, что вероятность установки всех настроек на идеальные значения с первого раза крайне мала. Может понадобится несколько попыток. ИМХО, хочу ошибаться.
>>657394 А всякие распределенные не? Ну, просто никому не интересно. Тут же чел какой-то писал что-то. Я ему говорил, что идея огонь, но нах не нужна. Че-то тишина, к сожалению.
>>657407 Посмотри с другой стороны: а что если станет меньше шизов?
>>657415 > Ты слишком добр Это называется «адекватность». =)
>>657441 Если есть — почему в вопрос «нет»? А если нет — то где же проекты? :)
>>657473 > Посмотри с другой стороны: а что если станет меньше шизов? Это будет не интересно. >>657474 Да не, орда популярна, относительно офк. Лепестки - так и остались proof of concept в котором единицы хостов с делением кусков чуть ли на не одной машине. Посмотрел бы на "реальное применение в боевых условиях" но треша типа по одной малинке на слой там нету. > улетит в небеса device='cpu' вот так надо
>>657482 > Да не, орда популярна, относительно офк. Относительно? Ну, я не спец, могу ошибаться, согласен. Но 200-300 человек на весь мир — не так много, как хочется тут некоторым анонам. И я, в общем, их понимаю. Просто не вижу спроса.
> о одной малинке на слой Бггг. Репке, че уж. =) Было бы орно.
>>657462 >7B mistral в принципе так себе справляется с RP Да не переживай, я сейчас 13b гоняю, они тоже не вывозят, лол. В прошлом треде бугуртил про датасеты, посмотри PIPA, LimaRP и что-то ещё было интересное, сходу не вспомню. Ещё можешь попробовать странное из 7b, типа этого https://huggingface.co/Intel/neural-chat-7b-v3 Если будет тупить и не поддерживать РП, попробуй карточку поменять. Cоветую что-нибудь из фентези. Олсо, когда вмерживаешь PEFT'ом имей ввиду, что тебе может не понравиться результат, у меня каждый раз получалось, что дообученная хуйня имеет очень большой приоритет, приходилось размыливать лору дополнительно. >Надоели сухие ответы LLM'ок. А меня соя заебала, просто сил никаких уже нет.
>>657464 >Он ужасен Да что-то на уровне моделей от хвалёных икаридевов с унди, лол. Хотя нет, получше, за меня не пишет, сои меньше... Короче, он лучше.
>>657558 Спасибо анон за советы буду дальше углубляться. Можно еще вопрос? Почему здесь все рассматривают только обучение на своем железе, что нет никакого дешевенького облака от какого-нибудь восточноевропейского вендора, Или что-то вроде этого? Просто, мне если даже докупить железо, все равно придётся не прилично долго ждать результат, а если разница в затратах скажем даже 30-50% то мне, в принципе, норм. Или если еще какие-то подводные?
>>657558 > за меня не пишет, сои меньше Честно говоря уже больше полу года это удивляет, неужели это какое-то достижение а не нормальная работа модели, которая получается промтом? Или есть господа, которые рпшат через силу и постоянно ловят сою и ответы за себя? >>657595 Обычно как раз это и предполагается потому что не только лишь у всех есть пригодное для обучения железо. Про стоимость тебе уже расписали, можешь глянуть сколько стоит гпу-час A100 и прикинуть затраты даже на что-то простое. А файнтюн потребует их сотни.
>>657617 Я думал, что тысячи долларов если тренить полноценную foundation model с нуля. Для просто тюнинга или дообучения гораздо меньше. В любом случае, мне еще далеко до этого, просто было любопытно. Я читал, что обучить 1.3B модель на каком-нибудь MosaicML уже стоит в пределах 2000 долларов, 7B больше 30 тысяч.
>>657629 С высокой вероятностью в этом треде никто не занимался полным дообучением, про лору можешь почитать в шапке гайд на инглише, там кажется было упоминание. Но опять же это лишь (q)лора значений в которой в разы меньше чем в модели. > https://rentry.co/llm-training Гайд по обучению своей лоры Прикинуть по обучению можешь отскейлив перфоманс А100 к другим карточкам, просто флопсы в фп16 емнип, хз как остальное повлияет, только не забывай про требования к врам.
>>657595 Аренда железа почасовая, а своё железо навсегда. Аренда поможет в трейне, а своё железо и для РП, и для всего. Смекаешь? Плюс не путай файнтюн и лору, первое требует ебейших мощностей и дообучает всё, а лора обучает от десятых долей до пары процентов параметров. Лоры, как правило, хватает на многое и для неё не нужны десятки видеокарт. >>657623 >которая получается промтом? Не на всех моделях получается. Я вот потыкал Ехидну 13b. Ей поебать за кого писать, промпт не спасёт. Плюс все размышления персонажей такой пиздец, что мерзко.
>>657650 > Не на всех моделях получается. Справедливо. Раз уж пробовал 13б модели - есть там нынче что интересное? Или может в 20б обновы. > Плюс все размышления персонажей такой пиздец Минестрейшны с оправданиями?
>>657407 >Не покидай нас, адекватов и так не осталось здесь! Капчу немного поправили, так что пока остаюсь. Нам на полчаса была смесь кириллицы, латиницы и цифер, такое бы любой заебался вводить. >>657445 >Okay. Там сейчас приставкой. Ллама 1 в свете ллама 2 как бы не актуальна уже. >Почему бы не Не хотеть. За 15 лет в интернете ни за что не платил и платить не буду.
>>657627 Окей, давай так, это безусловно возможно, но сами по себе перспективы — так себе на данный момент. =) Когда цены сдвинутся, или же алгоритмы подвинут качество, то обучать простенькую модель за 2к баксов уже поимеет какой-то смысл, конечно.
Что я делаю не так или так. Пресловутая сайга ужасно плохо себя показывает, просто жутко. На столько, что Undi95/Xwin-MLewd-13B-V0.2 вообще не про это и не для этого, решает простейшие бизнесс задачи на русском языке лучше? Простой пример - выдерни из текста номера телефонов и email. Сайга бывает попадает, но выдает миллион отсебятины до и после. Или начинает повторять ответ в разных формах. Запускаю через webui, мб проблема в этом Стоит ли пробовать 70b? Или это все балавство и нужно идти в рабство к яндексу?
>>657681 > Сайга Проблема в ней, она плохая. > Стоит ли пробовать 70b Однозначно стоит, но желательно не иметь завышенных ожиданий и обладать терпением/железом для них. Некоторые на русском в начале очень даже бодро говорят но потом уходят в лупы или ломаются, тогда как на англише подобного эффекта нет. Свободноговорящая без побочек - miqu
>>657652 >Раз уж пробовал 13б модели Так это старьё всё и я плююсь от всего. >с оправданиями? Не. Связь за пределами физической, хоуп афтер олл, либерейшн икспириенс, see where things lead us и так далее. Хуй знает, мне не нравится такое. Сейчас вот на мифалионе сделал быстрый сценарий "друзья детства поебалися первый раз". Что заявляет тяночка? Го будем друзьями, узнаем друг друга получше, давай не торопить события и будем строить отношения на честности, открытости и без осуждения. Причём эта вся хуита чуть ли не дословно кочует из модели в модель. Рофла ради написал пост, что хочу отношений и чтобы она не ебалась с другими. Тяночка подумала и заявила, что эксклюзивные отношения это стрёмно и что будет исследовать новые территории, это её право, и давай не будем загадывать на будущее, а строить отношения на правдивости, честности и без осуждения. А ещё without any expectations or pressure/ties bound. Карточка персонажа это тощая нецелованная тянучка без отношений всю жизнь, если что, правда температура выше единицы. Я так полное отвращение к РП с нейронками получу.
>>657691 Ну и пиздец, один раз случайно проскочившее можно свайпнуть, но постоянно - не. Мин-п, инстрактмод и прочее, разумеется, настроено ведь? >>657708 Спасибо >>657721 Попробуй сам, она странная но в чем-то хороша.
>>657724 > для запуска даже 4bit версии Чуть больше 40, 48 для суб 5 бит с контекстом, чуть больше 50 для суб 6 бит. А выше ее квантов и нет, q5k максимальный. С помощью llamacpp можно выгружать на процессор и обычную рам, скорость только будет низкая.
Запустил кобольд, скормил ему модель, запустил таверну, подключил к кобольду, загрузил карточку персонажа и он мне генерирует кашу из символов. что я сделал не так? Помогите пожулйста разобраться
>>657731 Покажи скрин таверны где семплеры настраиваются и параметры add bos token и подобные. И с какими параметрами запускалась модель. Уже видно что контекст стоит 2к и обрезка по нему же, это мало и может вызвать проблемы потом, но у тебя лимит еще не выбран, так что не основное. Еще выглядит будто отсутствует системная инструкция а сразу идет описание персонажа, включи в таверне инстракт мод из стандартных шаблонов, делается в панели что по букве А сверху вызывается.
>>657741 Все слои во врам и только ~6 гигов для 20B Q5 - странно. Вообще 40 слоев странный размер для 20b. Хотя от унди можно и не такое ожидать. Во всяком случае для его поделий температура 0.5 слишкомм мало, попробуйте больше 1, например 1.3. кстати, я не тот, кто у вас спрашивал скрины, а просто читал увидел и вспомнил что такое гавно с моделью может быть если модель сильно реагирует на температуру. Например модели для кодинга таким отличаются.
>>657722 >Мин-п, инстрактмод и прочее Кек, я там перебирал литералли любые параметры. Похуй. Возможно, сейчас не на оптимальных генерирую, лень перебирать заново для новой модели, только форматирование скопировал. Режим чат-инстракт, на чистом чате эта модель абсолютный имбецил. >Placing a hand on either side of his head, she pushes him closer still until he takes nearly half of her breast into his mouth. >she allows herself to become completely vulnerable in this moment - trusting implicitly that USER will respect her boundaries Вот, поначалу читал, как там языки танцуют на сиськах и электричество курсирует по венам, потом пошла жара и я уже такой - оппа, нихуя что началось. И в конце такое. Это же уже всё, я просто подошёл к окну и закурил после такого.
Приобрел p40 для тестов к своей основной видеокарте, в тестах все отлично, ускорение почти в 10 раз. Было 0.6-0.8 токена\с, теперь около 7.5 токенов\с, на q4. Но заметил одну проблему, после установки теслы стал замечать ошибки в логах системы на nvlddmkm, когда ошибка не раздупляется то система переходит в бсод с перезапуском. Сижу на 10ке, драйвера стоят нормально. Заметил, что ошибка может быть как-то связана с HyperV, так как именно после запуска и закрытия система может подвиснуть на минуту. Если у кого такая же проблема была, дайте знать, что я не один такой.
Антуаны, а Qwen 1.5 запускал кто? Интересует 14b. А то чет скачал GPTQ, и вроде без ошибок грузит в Угабуге, но вот сам смысл предложений потерян, только структура читается.
>>657789 После такой херни кто угодно бы закурил. Ну а вообще чего это ты, нука быстро уважай ее уязвимость и границы! >>657840 Если бы оно стоило дешевле и круто бы перформило то может быть, но ведь тут всего 16 гигов за дорого, да еще и амудэ. У них какие-то ускорители на 32 гига были не сильно свежие и условно дешевие (если сравнивать с таким же хуангом), но всеравно это и близко не похоже на бюджетный вариант. >>657880 noromaid/emerhyst 20 или >>657708 >>657970 /thread Чсх на западе оно тоже есть на аукционах по 700+$, при этом не понятно почему кто-то берет запаянные на коленке тьюринги, которые более рисовые, медленнее, не могут в bf16/tf32.
Прошу прощения за такой почти философский вопрос. Зачем использовать локальные LLM? Какими преимуществами они обладают? Конфиденциальность? Недостатки я понимаю, они слабее GPT 3.5 (не говоря уже GPT4, GEMINI, Claude). При это тот же ChatGPT имеет бесплатную версию. Это ни в коей мере не критика, хочу понять, может и мне нужна локальная LLM.
>>658294 >Конфиденциальность? Таки да. А ещё полнейшее отсутствие цензуры. >они слабее GPT 3.5 Плюс минус по уровню уже. >GEMINI Когда я её трогал, она была тупее турбы, лол. Говорят, в 1.5 что-то там поправили, но ХЗ. >При это тот же ChatGPT имеет бесплатную версию. Не имеет. Всё равно это левые сайты или уёбищный интерфейс самой оупенАИ. >хочу понять, может и мне нужна локальная LLM. Если не энтузиаст, то не нужна. Сфера с одной стороны сравнительно дружелюбна (инструкция в шапке может быть выполнена хоть макакой), с другой, требует железа и приложения ума, если хочется скоростей и ума на уровне турбы (то биш запуск сетки на 70B). >>658317 >Это цена целых 4 P40. ИЧСХ, по пропускной способности памяти как раз 4 P40 едва догонят одну 3090, а тишка ещё и пятой за щеку накидает (кстати, не видел ещё ни у кого, а жаль, там память подразогнана).
>>658294 Кондфиденциальность, отсутствие цензуры, полный доступ ко всему, весь промт твой, богатство настроек, бесплатность. > они слабее GPT 3.5 Нет, сейчас они его опережают по большинству показателей. Рили в современных реалиях 3.5 настолько ужасна и не понимаешь как это ее раньше ставили в пример. Разумеется для хорошей локалки нужно и хорошее железо с некоторыми оговорками. >>658317 Там речь шла о сравнении с 2080. Но вообще 3090 раза в 3 быстрее чем p40 в ллм, не имеет проблем с колхозом охлаждения и в десятки раз быстрее в других нейронках, при том что все еще относительно дешева. Так что это гораздо более привлекательный вариант если бюджет позволяет.
>>658364 Единственный минус 3090 — неясные условия эксплуатации. Впрочем, щас набегут «все там ясные, майнили, ужаренная», и зачастую могу даже оказаться правы. Ну а так да.
>>658367 > Ну и все. Не все, если хочешь (е)рп - пердолинг просто неизбежен. Или будешь пердолиться с жб и ныть что он не реботает, плеваться с искаженного поведения персонажа и некоторых типичных фраз, или будешь пердолиться с локалками и при удачном стечении тоже ныть >>658370 По сравнению с ржавыми p40 или теми перепайками - она чуть ли не фаворит, с учетом возможности детального осмотра и проверки.
Наконец-то приехала! В этот раз очень грязная, хотя термопрокладки новые. Воткнул обе в X16 слоты и получил 4.5+ Т/сек на 4KM в винде. КАК ЖЕ НАХУЙ РАЗЖИРЕЛ ЕБУЧИЙ ОБАБОГА!!!!11 Если соберу на консольном дебиане быстрее заработает?
>>658387 О, платиновый колхозинг на коробочке и стоящий рядом крутиллятор, аж ностальгия. > 4.5+ Т/сек 0.5 до "комфортного порога" не дотянул. Чем карты охлаждаешь? Хату застраховал? >>658463 дело говорит, это пиздец.
>>658463 >>658463 Спасибо за замечание. Вообще: 1. Это затычка 550ti. Используется чтобы избежать D6 при инициализации биваса. Там не может быть больших сил тока. 2. У моего БП эти молексы сделаны нормально, сечение проводов, вроде бы, не оптоволокно. (смотрел пучки сквозного припоя на его плате, когда разбирал и чистил.)
Убедили. Перекину затычку на другие провода. Охлаждаю колхозом.
>>658488 >Используется чтобы избежать D6 при инициализации биваса. Опции пропуска ошибок нет? Хотя плата китайская, о чём это я. >Перекину затычку на другие провода. Проблема ещё и в переходниках, много лишних соединений. В норм БП обычно есть парочка ЦПУ проводов и 3-4 ГПУ, так что в нормальном случае колхоз вообще не нужен (кроме офф переходника нвидии для Р40).
>>658499 >Опции пропуска ошибок нет? Хотя плата китайская, о чём это я. Не пытался искать, просто не парился. Но теперь поищу. А вообще в кастомных бивасах (у меня такой) можно даже: настроить отключение sata, pce-e по теймеру от бездействия (только pci-e не хотел активироваться после сна), выключить ecc, выключить предзагрузку операндов и предсказатель переходов, выключить логические ядра (ака потоки), очень тонко настраивать аппаратную виртуализацию. Всё сложно с китайскими платами, но не безнадёжно.
А вот с количеством разъёмов ничего не сделать. Их на всё не хватает.
>>658374 Ну как раз им она и проигрывает, по словам местных. И я могу сказать, что мне приходят отлично обслуженные и чистенькие. На корпусе коцки, но это уже не имеет значения. Так шо хз-хз. Но мне без разницы, канеш. На 2 3090 у меня денег нет, все равно, да и пофиг, в общем. Работает и хорошо.
>>658573 >Ладно, пойду разбираться с TCC => WDDM, а то чо. В принципе если P40 одна, то по какому-то из гайдов её точно можно переключить. Нужны ответы на 2 вопроса: Она точно не жрёт 50 ватт просто при загрузке модели, как в режиме TCC? Есть ли прирост в режиме WDDM для модели, полностью входящей на одну карту плюс контекст?
Какие драйвера ставили? Я ставил последние с сайта NVidia. Data Center / Tesla И вот эти драйвера шлют нахуй WDDM во всех позах. Проблема возникает на GridFeatures Я поискал и нашел драйвера Grid vGPU16 С ними в OCCT появилось ДОХУЯ датчиков. И режим WDDM включается по умолчанию.
В простое питание стало 11 ватт вместо 50. Хорошо? Хорошо!
Да вот только! Под нагрузкой стало не 140-160 ватт, а 100-120. И перформанс упал с 6 токенов до 4 токенов в секунду.
Да, нагрев уменьшился, потребление упало, база. Но разгона не имеем.
Может я что-то не так делаю? Перезагружаю ПК. Ща посмотрим.
>>658062 А если я хочу играть с несколькими персонажами (я до сих пор не создал свои карточки, только спиздил лорбук Блета — и там все персонажи лежали в одном ящике с миром), то мой выбор модели или ещё чего-то как-то меняется?
>>658781 Вообще никак, что ли? Я как-то играл на лорбуке, где условные Лена и Славя даже отличались между собой и разговаривали, а модель там какая-то Agnaistic 13B
Аноны, нужен ассистенс. Хочу научиться определять системные требования, в первую очередь VRAM, для запуска LLM'ок, чтобы не заебывать окружающих. Нашел такую формулу в интернете:
>VRAM for Inference/Prediction with LLM on LLaMa 7B: While running the inference batch size always remains 1. So configuration to run inference becomes as follows: params = 710⁹ p = 32 #precision b = 1 #batch-size s = 2048 #sequence length l = 32 #layers a = 32 #attention heads h = 4096 #hidden dimension Substitute these values in Formula №1 to get the Activations in Network. Activations in Network = 10,880,024,576 Now substitute this value in the Formula №2 to calculate VRAM VRAM = p (Activations + params) VRAM = 32 (10,880,024,576 + (710⁹)) VRAM = 572160786432 Bits VRAM = 66.6083 GB
Решил проверить как работает формула, но на этапе перевода битов в байты, получается странная фигня: 572160786432 Bits = 66.6083 Gibibytes = 71.5201 Gigabytes Что за Gibibytes? И вообще эта формула адекватная или какой-то высер человека далекого от темы ради кликов?
>>658776 И кстати там в NVidia Control Panel надо всё в Maximum Performance поставить (Power Management вроде). А то оно по умолчанию в режиме энергоэффективности, может в этом дело.
>>658799 Ага. Только некоторые слои квантуются в разной точности, так что ХЗ что там вводить. А так в шапке прикидки должны быть. >>658847 >Я обычно каждый день по новому сюжету начинаю Это... Вся суть в контексте. Если с чистого листа и с одним персом, то справится любая нормальная модель.
>>658862 >Только некоторые слои квантуются в разной точности Что тогда имеют в виду, когда пишут биты квантования на страницах моделей HF. Там же всегда одно значение пишут. Сорри, если вопрос глупый.
>>658862 Как я понял можно считать грубо так: Модель 4 bit 7B требует примерно 7-8 GB VRAM в зависимости от контекста (до 2K до 4K). Если контекст больше 4К, нужно еще больше VRAM?
>>658570 > Ну как раз им она и проигрывает, по словам местных. Что? Внешне они и будут хорошими, ведь стояли в серверах а испортить может только неверное хранение, но если китаец не раздолбай, даже это почистит. А вот какая была ранее судьба, новье что всю жизнь пролежала на складе или проперженный рефаб, обслуживались ли, сколько десятков-сотен тысяч циклов нагрев-охлаждения испытали текстолит и подложка и т.д. 3090 гораздо новее, хоть и могла находиться в условиях похуже, так что в отрыве от всего зесь, считай паритет, или битва жабы и гадюки, называй как хочешь. А так действительно в отличии от p40, пара 3090 уже не выглядит игрушкой, которую по рофлу может кинуть в корзину большинство инджоеров. >>658759 Те же модели смогут подобное отыграть. В принципе, они даже справляются с введением посторонних чаров в сценарии обычной карточки и не вызывает проблем, если со всеми этапами все сделано правильно. Но можно лучше, это 34б (оче странные и могут уступать 20б по сторитейлу и последовательности, хоть и умнее) или 70б (высокие требования). >>658788 Да сможет такое, есть как карточки на несколько чаров, так и режим группового чата. Особенно если у тебя оно работает быстро, не понравится ответ - без раздумий свайпаешь его пока не получишь приглянувшийся. >>658790 Это для голого диффузерса чтоли? Пускают кантованные модели на оптимизированных лаунчерах. Минимальные требования для 4+ битного кванта: 7б - 8гб, 13б - 12гб, 20б - 16гб, 34б - 22гб, 70б - 44гб. Цифры примерные, если подужать кванта - можно меньше, но модель заметно отупеет, если хочешь контекст побольше - добавляй еще по несколько гигабайт.
>>658936 >какие мысли на текущий день? В принципе я согласен с этим постом на Реддите. Вообще по ощущению неквантованные модели сильно умнее квантованных. Хотя я выше 30В в неквантованных и не поднимался и давно сижу на гергановских квантах. И да, некоторые семидесятки хороши. Некоторые стодвадцатки тупят и не понимают контекста. Дефекты от квантования есть и заметные. Но никаких альтернатив я не вижу.
>>658860 Ну вы чего, локалы, как сраться и некроту обсуждать так все, а по рп - никто не практикует чтоли? > https://huggingface.co/Undi95/Emerhyst-20B > Чат от начала октября (!) > окно 12к контекста с настройками rope + суммарайз > (ooc: now slowly develop story to the point where Yumi's mother will approve their decision and will try to seduce him) > плавный переход и развитие с введением и подробным описанием вскозь упомянутого персонажа и коллективных разговоров > "“Ah, my silly daughter,”" her mother’ voice held both fondness mixed with underlying amusement, causing Yumi’ cheeks flush crimson with embarrassment.. "“Finally decided share your secretes with us, huh?”" she stepped forward gracefully, stopping mere inches away from Thomas.. Up close, she saw the scar running across his chiseled jawline, reminder of challenging past of this intriguing human male.. > плавное развитие подкатов и продолжение коллективных разговоров со смущающимся и ревнующим основным чаром > Turning around with her clothes fallen on the floor, Ayaka faced them both directly, her tails swaying seductively behind her.. "“Now,”" she began, voice dripping with unspoken promises.. "“Show me what has captured my daughter’ heart so completely.”"
Это все доступно любому в коллабе уже довольно давно. Сложности разве что с карточками где много персонажей, их будет путать, но с этим и гопота может ошибаться. Групповой чат не пробовал, но он без проблем должен работать. >>658936 Есть tldr? По заголовку верно, нормальный персплексити - условие обязательное но вовсе не достаточное, также как и днищефайнтюны под бенчмарки. Вроде немного времени прошло - а те модели уже лежат на помойке и вспоминаются лишь в контексте подкруток. >>658984 Все наоборот, и размер контекста важен.
>>658816 >>658849 Короче, проблема в том, что после перезагрузки система (Windows 10, UEFI) уходит в синий экран, или сразу, или чуть погодя. Удаление дров в безопасном режиме помогает загрузиться в обычно, и накатить их снова. Но с тем же исходом.
Итого, не знаю, что не так у меня, но Intel HD + P40 + P40 не запускает Windows на драйверах для vGPU в режиме WDDM, а на обычных драйверах не позволяет запустить WDDM в принципе. Т.е., вроде как меняется что-то, но это что-то — это зависания системы после перезагрузки. Опять же, смысла нет.
И хрен его знает, что делать, по итогу, оставаться на TCC, получается. =/ Или реинсталлить винду целиком? Но как это поможет вообще?
Насколько вообще критично постоянное потребление 50 ватт, без реальной утилизации ядра? Куда вообще эти 50 ватт идут?
Линукс накатывать еще более лень, лул. =D Хотя, как вариант…
>>659023 А вот когда накатываешь драйвера снова и переключаешься в WDDM и включаешь в Nvidia Control Panel "Максимальную производительность" - производительность восстанавливается? Или ничего не меняется? >И хрен его знает, что делать Есть предложение временно отключить вторую Теслу и добиться стабильности на первой, по одному из гайдов.
>>659023 > винду У тебя и так крочелыга на странном железе, которая может только в ллм и может другие нейронки, зачем эти пляски когда есть линукс, который еще и быстрее и меньше расходует память?
>>659023 Кстати может и бред конечно, но я вычитал в новости об этих vGPU драйверах, что они требуют обязательной установки сервера контроля лицензий и без него отключаются. Может дело в этом.
>>658949 В общем, качаю Mixtral-8x7B-Instruct-AWQ, хз, сосну ли я с групповыми чатами или нет. Попробовать много моделей не могу сразу, потому что они весят тонну, а я все деньги на видюху потратил, а не интернет
Короче, я погуглил, подумал, и решил, что не нужон мне ваш WDDM. Кроме 10 ватт в простое вместо 50 ватт (это само по себе хорошо), но потеря производительности (как я понял, из-за включение модуля обработки графики, видяха ужимает остальное) и непонятная работа — не стоят того.
Вернусь к этому, когда перейду на линуху, или когда люди разберутся в драйверах.
в котором люди добивались нормальной работы (и производительности) с драйверами Grid 511.65. И даже с зоопарком из трёх разных тесл.
А что касается настроек "максимальной производительности", то я имел в виду Панель управления Nvidia-Управление параметрами 3d-Режим управления электропитанием-Предпочтителен режим максимальной производительности. Говорят помогает.
>>659023 Вообщем могу рассказать чуть из опыта с теслой, она очень себя капризно вела и вешала винду, до тех пор пока я не выставил какую то смехотворную частоту на ддр4, 1866 вроде, в бивасе, без этого память по пасспорту 2666 и нормально работала уже несколько лет, но вот такой закидон начался именно с теслой, попробуй чтоли, если не лень, в порядке бреда понизить частоту рам
>>658377 >Может на линуксах в экслламу? Нет конечно. На Реддите пишут что может только в Llama.cpp и то скорее всего на линуксах, т.к. rocm в винде не работает. В целом как будто более быстрая альтернатива P40. Но мне ещё интересно как она работает в SD. Пробовал гнерить на RX580 в directml, не понравилось мягко говоря. Самая жопа это то что TiledVAE с AMD не работает. Эо для меня стало критичным косяком. Если с Mi50 всё также, то нахуй её, уж лучше медленный P50.
Впервые серьёзно попробовал всю эту ai тему подрочил в janitor и заинтересовала гипотетическая возможность запустить что-то подобное локально.
Cpu vs gpu. Есть ли принципиальная разница? На что возможны одноплатник, многоядерный китайский зивон и современный i3-i5? Или всё это долбоебизм и какая-нибудь 1660 уделает их всех? Есть ли разница между амуде и нвидией? Что лучше 1 мощная или 2-3 более немощных видях?
>>659256 >Cpu vs gpu Неправильно. Cpu + gpu правильно. >Или всё это долбоебизм и какая-нибудь 1660 уделает их всех? Ага, только ей не хватит врам и пожэтому мы и отгружаем часть слоев на карту, а остальное крутится в рам и считается процом. >есть ли разница между амуде и нвидией? Ага, амуде не работает. Если серьезно то нвидиа дрочила тензорные вычисления (а соответсвенно и все что связанно с сетями) уже много лет и наработала БАЗУ. Все инструменты выходят на амд с опозданием, работают медленнее и требуют зачастую адских танцев с бубном. >Что лучше 1 мощная или 2-3 более немощных видях? Луче для чего? Скорость? 1 мощная. Вместимость врам? 2 простых.
>>659256 >Что лучше 1 мощная или 2-3 более немощных видях? >>659256 >Есть ли разница между амуде и нвидией? >>659256 >Cpu vs gpu. >Есть ли принципиальная разница? Разница в скорости. Даже средний на сегодняшний день GPU будет в разы быстрее. Плюсы инференции на CPU в том, что дешевле запилить большой объём памяти под использование более "умных" моделей. Можно также использовать CPU и GPU вместе.
>На что возможны одноплатник, многоядерный китайский зивон и современный i3-i5? Для инференции на CPU решает не только производительность и количество ядер, но и 1) пропускная способность памяти (младше DDR4 мало мысла использовать), поскольку работа модели сильно завязана на операции с памятью; 2) поддержка расширенных наборов инструкций типа AVX2 и AVX512. Без этого будет совсем медленно.
>Есть ли разница между амуде и нвидией? NVidia с CUDA гораздо лучше поддерживается всем, что связано с GPU вычислениями. Но можно и с Radeon'ами как-то жить, особенно если не ограничен запуском софта только на Windows.
>Что лучше 1 мощная или 2-3 более немощных видях? 1 мощная обычно тупо удобнее, но скорее всего окажется дороже в плане соотношения производительность/цена.
>>659074 О вот это прикольно - все в одном файле и картинки тоже, и так то бубугу запускал только ради exl2, кобольд - сильно удобнее и теперь еще интереснее с локальной sd внутри.
>>659098 Я брал 3600 не ради того, чтобы в 1866 занижать, сорян. ^^' Тут меня внезапно жаба жать начинает.
>>659256 Чую, тебе ответили, но и я наверну разок. Разница в 10-20 раз по скорости. Одноплатник способен на 0,25B~1,3B максимум, полагаю. Зион способен на любые модели. С AVX2 — упор в память. С четырехканалом 1866 — получается аналогично обычной DDR4 3200 в двухканале. Выше — лучше. Современный i3-i5 на DDR4 — способен показать от 5-7 токенов на 7B модели (и 2,5-3 на MoE модели) до 0,7 токенов на 70B (сколько и AVX2-зеон с четырехканалом). Но тут скорее i5, будет чуть быстрее. С i7 разница уже не критична. Ну а если соберешь на DDR5 — то там можно вплоть до удвоения скоростей. 1660 нихуя не уделает, могу вот-прям-ща запустить свою супер на работе. 1. Имеет значение объем видеопамяти. В 6 гигов влезет только 7B моделька пожатая, такое себе. Но на ней можно ускорить обработку контекста. 2. 1660 вообще не то поколение, которое что-то умеет. =) Лучше ориентироваться на 3060@12 из обычных видях. НВидиа лучше, но если есть амуде — то там исходя из ее поколения можно что-то да получить. Сомнительно, но окей. Одна мощная с малым объемом памяти — просто ничего не позволит тебе запустить. Какой смысл в быстром движке без машины и колес. 2-3 более немощных, но с таким же объемом памяти (удвоенным-утроенным) позволит что-то запустить, вероятно быстрее, чем на процессоре. Но тут у нас есть король — Tesla P40, при цене в 16к рублей имеет 24 гига на борту. Если у тебя пиздатая материнка на 3 слота, то сможешь запускать почти любые почти непожатые модели на вменяемой скорости. Но в режиме кпу-моделей выгруженных на видяху. Ибо Тесла не умеет быстро в нативные гпу-модели. =) Но для маленьких моделей лучше что-то быстрее (та же 3060) и грузить нативно на видяху. Там скорость будет заметно выше.
Такой расклад.
Лучший вариант — современные A100/H100 с 80 гигами. Только цена кусается.
>>658896 >Что тогда имеют в виду, когда пишут биты квантования А ХЗ. Гергановские 4км это в среднем 4.65 . >>658904 Да. >>658998 >Есть tldr? Заголовок и есть tldr. Дожили, текст на 4 абзаца уже прочитать не можем. >>659074 >давать ссылку на средит, который тупо ссылается на гитхаб https://github.com/LostRuins/koboldcpp/releases/tag/v1.60 Пиздос. И картинки тоже пиздос, 256х256.
Может мне кто-то объяснить как на HF я нахожу русскоязычные версии Mistral 7B. Оригинальная модель не поддерживает русский язык. Разрабам удалось отфайтюнить модель, которая не обучалась до этого на русских datasets? И как это вообще возможно? Какого вида fine-tuning dataset должен быть, чтобы достичь такого результата? Хватает ли для этого LoRA/QLoRA или уже нужен full parameter fine-tuning?
>>659074 Зачем? Объективно, в большинстве кобольдом пользуются обладатели отсутствия врам, а они еще предлагают отдать несколько гб под диффузию, да еще предлагают на лету квантовать и без того требовательную к условиям 1.5. >>659256 Гпу, даже древняя, даже амудэ будет в разы быстрее (обычного) процессора, но ограничена в памяти. А системы что могут составить конкуренцию чему-то простому недоступны обывателю и стоят как пачка видеокарт. Проц позволит запускать что угодно что поместится в память, но при ответах по несколько минут это может терять смысл. > 1 мощная зис, при взаимодействии с ллм складывается только видеопамять, мощность будет считаться примерно по средней и с некоторым штрафом за объединение. Из бюджетных вариантов - tesla P40 (годна только для ллм но дешева), 3090 (годна для всего и быстрее но дороже), желательно иметь пару. > Есть ли разница между амуде и нвидией Ну кмон, на этой доске такие вопросы задаешь. Конечно амудэ с проглотом сосет и представляет как великое достижение демонстрацию уровня перфоманса старых мидлов хуанга на своих топах после долгого пердолинга. В ллм все несколько лучше чем в общем по нейронкам, но всеравно печально. >>659541 Да, почти любую модель можно тренировать дальше. Для хороших результатов нужен полноценный файнтюнинг, для простого хватит и qlora. Локализация - сложное.
>>659267 >>659276 >>659333 Спасибо за ответы. И ещё вопрос. Есть какой-то ai бенчмарк чтобы без лишних заморочек понять сколько попугаев обеспечивает моя система, и какой результат и с какой скоростью я получу? Либо где можно глянуть какие системы что выдают?
>>659545 >Да, почти любую модель можно тренировать дальше. Для хороших результатов нужен полноценный файнтюнинг, для простого хватит и qlora. Локализация - сложное.
В чем преимущество такого подхода тогда? Т.е. в моем понимании, если модель не обучалась на русском языке, значит её придется тренить практически на полноценном dataset как во время pre-training. Не легче уже обучить модель с нуля? Или я что-то упускаю?
>>659554 В датасете был русский, что-то модель может. Потому не обязательно тренить на полноценном датасете с триллионом токенов, хватит и более мелкого, но всеравно он должен быть обширным, разнообразным, сбалансированным, нормально форматированным, и содержать немного смешанных языков. А файнтюн - полноценным. > В чем преимущество такого подхода тогда? Q-lora на мистраль ты можешь обучить даже на микроволновке мультимедии авто с автопилотом от хуанга
>>659541 >Оригинальная модель не поддерживает русский язык. Поддерживает, но хуёво. >которая не обучалась до этого на русских datasets Обучалась, там наверняка в датасетах был комон кравл, где русского наберётся полпроцента. >чтобы достичь такого результата Какого такого? Они все говно. >>659554 >Не легче уже обучить модель с нуля? Обычно не легче.
>>659558 Понял, спасибо. И еще вопросик в догонку: >Для хороших результатов нужен полноценный файнтюнинг, для простого хватит и qlora. То есть все таки qlora не "всесильна", есть юзкейсы, когда нужен полноценный файнтюнинг?
>>659560 >Обучалась, там наверняка в датасетах был комон кравл Вот тоже интересный момент, обучаются они почти на одних и тех же данных, но даже сырые базовые модели сильно отличаются по качеству от разных вендоров.
>>659561 Именно. В принципе, лора - уже большой компромисс и сжатие данных с потерями, по аналогию с джипегом для картинок, в отдельных случаях может работать неплохо, но сложное, где охватываются возмущения множества весов, уже не вывозит. q-lora - еще больший компромисс, ведь оно обучается не на плавных градиентах, а на ступенчатом пиздеце. В идеале - полноценный файнтюнинг нужен всегда, просто в некоторых случаях разницу придется выискивать под лупой (из хороших примеров - llimarp лора вскоре после выхода ллама2), а где-то там полнейший пиздец (сайга).
>>659560 >Обучалась, там наверняка в датасетах был комон кравл, где русского наберётся полпроцента. Наверное больше полпроцента. Как ChatGPT тогда удается отвечать на любые вопросы на условном венгерском, вряд ли есть много данных на венгерском? Видимо им как-то удалось сделать машинный перевод на лету или они прям переводили dataset?
>>659566 У него в обучении было больше данных, опены явно заморочились над хотябы мелкой балансировкой по языкам, и он сам больше. Такой же эффект можно наблюдать в разных размерах лламы, когда 7б и двух слов связать не может, а 70 вполне себе говорит с редкими ошибками, офк речь про первые запросы.
>>659541 >Оригинальная модель не поддерживает русский язык. У 99% моделей в датасетах лежит википедия, в т.ч на русском языке. Но есть нюанс, "русским" считается вся кириллица, потому когда пишут "у нас в датасете 3-4% русского" смело дели на десять. >уже нужен full parameter fine-tuning? Как правило, для полноценной локализации даже файнтюна модели недостаточно. Здесь анон писал про какой-то "метод финнов", возможно там какие-то интересные штуки, но хуй знает. >>659561 >То есть все таки qlora не "всесильна" Главная беда QLora даже не в том, что это обучение с потерями, а в том, что она затрагивает 0.1-3% параметров, причём обычно это даже не все типы параметров, а только специфические.
>>659572 Спасибо, судя по всему даже заворачиваться с этим не стоит. В англоязычных интернетах тоже у людей не особо получается достичь качественного результата, правда для более маленьких языков типа чешского. Стоит отметить, что некоторые хвалят Zephyr 7B. У него видимо dataset был более многоязычный чем у llama или mistral.
>>659581 >метод финнов что-то поиск по ключевому слову в текущем треде ничего не находит ты случайно не помнишь, это было в прошлом треде или в этом? не хочу зря время тратить перечитывая и вникая во весь тред
>>659563 Почти не считается. Там сильно много переменных при обучении. Некоторые могут гонять весь датасет пару раз, некоторые выделяют "важные" части и гоняют по ним десяток. >>659566 >Наверное больше полпроцента. Уговорил, все пять. Впрочем все обычно чистят датасеты вилкой, даже 2 girls 1 cup не пропускают https://github.com/LDNOOBW/List-of-Dirty-Naughty-Obscene-and-Otherwise-Bad-Words/blob/master/en >Как ChatGPT тогда удается отвечать на любые вопросы на условном венгерском Перенос знаний, как они говорят. То есть модель внутри себя как бы делает перевод, итого ей не нужно запоминать все факты на всех языках, а используется универсальная база. Но это они так говорят, я ХЗ что там на самом деле, ибо в попенсорсе нихуя нет.
>>659585 Там не было подробностей. >публикации и репу финов с "локализацией любой ллм" смотрел? И, собственно, всё. Так что хуй знает, можешь загуглить. Если бы это работало, уже были бы реализации, я думаю, тот же Гусев мимо не прошёл бы, он свою лору в джемму вмержил как только та появилась.
>>659596 >Перенос знаний На больших сетках может работать, если она может связать 'Godfather' и 'Кум'. На мелких без шансов.
>>659373 >И картинки тоже пиздос, 256х256. Там и не надо йоба картинки - для этого есть автоматик. Просто моментальные иллюстрации к тексту, и довольно забавно получается в автоматическом режиме промта. Писать же специально промты конечно нахер не надо ради этого. Только для попутной генерации по тексту.
>>659605 >Ну так в этом и смысл. Это одна из причин, почему гопота ебёт. Гэри Маркус и ему подобные утверждают, что скоро все сетки от крупных игроков сравняются по качеству, так как наступает плато для LLM'ок. Типа увеличение размера сетки приводит все к меньшему и меньшему улучшению качества ответов. Другие техники улучшения тоже имеют свой придел. Может это коупинг с моей стороны, но если BitNet с его 1.58 битностью взлетит, тогда не будет сильно большой разницы между ChatGPT и локальной моделькой.
>>659541 Мистраль имеет много русского в датасете и очень хорошо говорит для 7B-модельки.
>>659545 > даже древняя, даже амудэ будет в разы быстрее (обычного) процессора Нет. Попробуй даже на относительно недревней RX 480 покрутить 7B-модельку и расскажи за результат. А теперь возьми действительно древний гпу навроде 7770, покажи, насколько он хорошо ускоряет. Так что, там разница на грани, что можно и не тратиться на покупку.
>>659547 Просто ставишь 1024 длину ответа и задаешь вопрос какой-нибудь «расскажи подробно». И в консоли тебе выдаются числа. Никакие бенчмарки особо не нужны.
>>659566 Да там в датасете дофига всех языков. «вряд ли много» — дохуя. =) Если вся Мистраль 7B, а чатгопота 220B, то даже менее 1% должно хватить для отличного владения языком, а на среднем уровне хватит и долей процента. Арифметика.
>>659582 Многие авторы файнтьюнов выкладывали свои датасеты по языкам, в карточке модели порою можно посмотреть.
>>659680 ИМХО, лучше 3-4к контекста и 5-битный квант. Там будет чуть лучше.
>>659736 Ты имеешь в виду, что мы локально сможем чатгпт запустить? ) В том плане, что 220B превращается в 40 гигов, и с ними уже можно жить где угодно. Это всего лишь один из специалистов чатгопоты, но уже уровень.
ОДНАКО, ты путаешь размер и скорость. Если опенсорсу не дадут натренированных моделей, то все что у нас останется — открытый датасеты, из которых натренируют максимум 7B или там 13B.
Да даже пусть будет 70B — она будет очень быстрая (при размере-то в 13 гигов), но знаний-то у нее будет на 70B, а не 220.
1.58 бита — про скорость и малый размер (доступность). Но к датасетам это не имеет отношения. Зачем корпам отдавать нам на халяву умные модели?
Если бы дали — ты прав, разница была бы малозаметна. Но дадут ли? :) Или кто из нас сделает?
>>659736 >Гэри Маркус и ему подобные Вот за подобных обидно было. Я про плато ещё год назад писал. >Может это коупинг с моей стороны Да, коупинг. Локалки ещё долго будут отставать от 4 гопоты. >>659763 >относительно недревней RX 480 ОЧЕНЬ ОТНОСИТЕЛЬНО.
>>659773 470 разлетаются как горячие пирожки с алика. =D Выше в треде чел с 580 16-гиговой, которая, я надеюсь 580, а не 470. И то — недалеко ушла, на самом деле. Так что, рядом с нами сидят на такой относительно недревней.
>>659801 >470 разлетаются как горячие пирожки с алика. Потому что население нищее. Даже 4090 кусок говна, который не может в 140 кадров в 4к с полными лучами. >которая, я надеюсь 580, а не 470 Ты так пишешь, как будто между ними есть существенная разница.
>>659581 > метод финнов Качественный машинный перевод большого достаточно широкого датасета, у них в репах уже готовые лежали на десятках языках. Офк потребуется доработка >>659582 > судя по всему даже заворачиваться с этим не стоит Сложно сказать. Если обладаешь ресурсами, временем и самому интересно - стоит, при отсутствии полумеры могут лишь огорчить. >>659602 > я думаю, тот же Гусев мимо не прошёл бы Переоцениваешь, учитывая прогресс за все время и реакцию на обратную связь. >>659763 > на относительно недревней > RX 480 Взаимоисключающие, оно уже давно должно помереть. Но даже она будет бустрее процессора, как минимум за счет шустрой обработки контекста. > действительно древний гпу навроде 7770 У них перфоманс не то чтобы отличается от поларисов Но вообще предлагать воспользоваться некроамдэ можно расценивать как оскорбление, фу. >>659801 > 470 разлетаются как горячие пирожки с алика. =D Это не комплимент карточке а признак печального благосостояния.
>>659736 >Может это коупинг с моей стороны, но если BitNet с его 1.58 битностью взлетит, тогда не будет сильно большой разницы между ChatGPT и локальной моделькой. Как уже выше заметили - будет, ещё какая будет. Датасет - раз. Обучение огромной модели - два. Всё это недоступно не то, что частникам, но даже и достаточно крупным компаниям.
А так-то на Обниморде лежит модель на 220В. Только она смержена из нескольких семидесяток. Теоретически её в минимальном кванте даже можно запустить, но зачем?
>>659773 >Вот за подобных обидно было. Я про плато ещё год назад писал. О, а можно поподробней? Это просто интуиция или есть какие-то теоретические (или практические?) предпосылки
>>659876 > что она не древняя https://www.youtube.com/watch?v=fUAaTSmDqS8 > Все хотят общаться с вайфу Да пусть общаются, 7б доступны и уже настолько хороши что год назад ахуели бы. При наличии скиллов доступны и большие или корпоративные. Надо становиться лучше самому и первый шаг на этом пути - признание реальности, а не опускать манямир до своего уровня.
>>659869 >Это просто интуиция Да. Заебало, что все вокруг кончают радугой от экспоненты, хотя по факту вся история это набор S кривых. С ИИ тоже самое, это вроде как третья штука. А потолок близко, да, очевидно методы говно.
>>659898 как думаешь есть смысл вкатываться в ML сеньору с 7 года опыта разработки без предыдущего опыта в ML и только с базовыми знаниями пайтона тема хайповая, но что-то побаиваюсь, что наступит плато и потом начнут всех и вся сокращать, а так в кровавом энтепрайзе стабильность, хоть и серая
Есть какие-нибудь техники, чтобы заставить модели высирать не одни и те же очевидные идеи по вопросу? Когда я задаю вопросы по маркетингу, то все модели выдают абсолютно одинаковую дженерик хуету, как будто их тренируют на одних и тех же данных. Я уже наверное промптов 20 перебрал и все равно хуйня какая-то.
>>659912 Если хочешь зарабатывать миллионы — готовься пахать и занимать теплое место. Если уже получаешь сотни и не хочешь напрягаться — то я не уверен.
>>659941 > Не является инвестиционной рекомендацией.
>>659964 Ну как пример один из вопросов: How do get free installs for your mobile app? Каждая модель высирает дженерик хуйню как под копирку. Хотя у меня вопрос тоже из разряда СДЕЛАЙ МНЕ КНОПКУ БАБЛО, но по более конкретным вопросам ситуация не лучше. Потом я пытался вертеть промптом. Прописывал роли что-то вроде ты 300кк наносек гуру маркетинга с 300 iq, высри мне идей. В итоге они выдают те же ABCD пункты, просто заумными словами
>>659333 > но если есть амуде — то там исходя из ее поколения можно что-то да получить. MSI AMD Radeon RX 7900 XTX GAMING TRIO CLASSIC 24гб можно зацепить? Или INNO3D GeForce RTX 3090 iCHILL X4 за 98к, но это вроде говно. Или не жопится и докинуть 15к до ASUS GeForce RTX 3090 Turbo (BULK) [TURBO-RTX3090-24G]? Сейчас глянул в днс "скидки" подъехали. Но я полтора года назад взял 3070ti за эти деньги, так что боль еще не утихла.
Спасибо челу, который вчера мне подсказал прожать "row_split". Теперь, скорость с ~4.5 поднялась до ~6.2 т/сек. Китаедебил с 2умя Р40 и хреновой проводкой.
>>659852 >Качественный машинный перевод большого достаточно широкого датасета Так это файнтюн обычный. На обниморде лежит практически фулл трейн 7b на русском датасете, но всем поебать. >учитывая прогресс за все время Ну, он тренит лоры, то есть какое-то оборудование у него есть. Да, они микроскопические, но данных довольно дохуя, у него порядка 75 гигов распарсенных пикабу и прочей шелухи. Для первоначальной настройки это годится.
>>659964 Крути температуру, top_p и top_k. Если модели тренены на одном и том же, а это скорее всего так, то не особо поможет.
>>660029 На здоровье, мне ж тоже тогда подсказали. =) Но проводку ты это. В порядок приводи. ^_^'
>>660027 Уф, я не крутил такую, кто-то тут был вроде, с похожими картами. ИМХО, не самый… СКОЛЬКО СТОИТ? Не, ну за 40 с авито или 60 новая вариант норм, наверное, но за 180 я бы точно не брал. Там уже до 4090 недалеко. ИМХО, может меня поправят.
>>654587 (OP) Дгузья!!! Сейчас я попробую объяснить, почему вас штред ХУЕТА и как не пойматься на всю эту галиматью и не всрать кучу $$$ новеньким. 1. ВСЕ 7B хуета. И даже для них нужно от 6гб вирама исходя из квантизации. 2. Более-менее что-то вменяемое по ролеплею - это 13B 3. 13B ллама и мистрали-аналоги - ХУЕТА 4. Чатгопота 3 лучше 13b 5. Чатгопота 4 ЛУЧШЕ ВСЕХ 6. Более-менее приятно пользоваться нейронками при скорости генерации от 10 токенов, лучше 18-30.
Что вы там делаете на своих нищих нескольких токенах (5-6) и на нищих моделях, я не знаю. Интереснее с бомжихой у падика виртить, чем на таких мощностях. Удачи всем!!! Попробуйте опровергнуть, буду рад.
>>660137 Забыл добавить: 1. Мак М1-М2 имеют много памяти, но скорость генерации уровня 1060 2. Tesla P40 имеет много памяти, но скорость генерации уровня 1060
>>660142 >Tesla P40 имеет много памяти, но скорость генерации уровня 1060 Скорость генерации двух Тесл для модели 70В с приличным квантом на потребительской материнской плате установлена и составляет 6,3 токена в секунду. Dixi.
>>660180 Во-первых, за стоимость двух p40 ,которая составляет сколько? Больше 30-ки? Берётся более новое железо. Да, на нём 70B не запустишь, но запустишь что-то более простое с успехом и оно будет радовать. 2. >6,3 токена в секунду Поистине нищий вывод, который отбивает всякое желание. 3. Эти >70B с приличным квантом (надеюсь, не q4 ?) хотя бы превзойдут Чатгпт 3.5 ? Сомневаюсь. 4. И всё-равно вся эта спарка с Stable Diffusion будет проигрывать более новому железу за ту же цену. Dixi.
>>660163 Да что угодно. Я на обниморде искал русские датасеты, потом сидел и не мог понять, толи обдвачился, толи лыжи не едут. Оказался хорватский под видом русского.
>>660193 >хотя бы превзойдут Чатгпт 3.5 Когда гопота 4 превзойдёт гопоту 3, тогда и поговорим.
Первые попытки в локальный кум. Поставил koboldcpp, на OpenBLAS и проце всё норм работает, CLBlast даже на 1b моделях стабильно выдаёт ggml_opencl: clGetPlatformIDs(NPLAT, platform_ids, &n_platforms) error -1001 at ggml-opencl.cpp:989 You may be out of VRAM. Please check if you have enough.
>>660209 >Полноценная 13B без квантизации с хорошей скоростью вывода будет способна радовать. Ну может быть третья Ллама выйдет и её 13В приятно удивит нас... Только вот её версия 70В тоже выйдет.
>>660012 > Ух, золотая молодежь. ))) Тут только платиной ответить: работать не пробовали? >>660027 3090 вариант солидный, но переплачивать почти х2 за новую - даже хз, когда за 115к можно пару лохитовских взять. Офк рулетка и есть риск соснуть, а тут ты защищен от брака и проблем. >>660061 > файнтюн > обычный Зажрались нахрен. И это не "обычный" а с качественным датасетом, который является основной основ если параметры тренировки подобраны. > практически фулл трейн 7b на русском датасете, но всем поебать Конечно поебать если он залупа. Фулл трейн вообще не может получиться полезным если в нем не будет огромного пласта данных и знаний на инглише и других языках. При всем уважении, если доля русского там будет выше 30-40% то почти наверняка это будет фейл. > порядка 75 гигов распарсенных пикабу и прочей шелухи щит ин - щит аут. Еще и то что лоры "мелкие" не делает в плюс. По железу - можно предположить что сидит на грантах у кого-то или на квоте для института и лениво эксплуатирует инфеймос местные v100.
>>660137 > даже для > нужно от 6гб вирама Инстантом детектится копротивляющийся нищук-оправданец с флагштоком за проксечку. Опровергнул за щеку. >>660193 > Больше 30-ки? > Берётся более новое железо Что нового можно купить за эти деньги? Протухший неликвид если только. Но если не искушенный - даже такое может радовать. > с приличным квантом Секта свидетеля кванта > с Stable Diffusion > 30к Хммм Еще один оправданец, или тот же? >>660209 Все просто, употребляешь пару литров пенного, или эквивалент, и садишься рпшить. А там даже 7б будет радовать. > без квантизации "потому что я могу"?
>>660213 Это какая-то хуита и халатность автора конкретного датасета видать. Потому что объективно большинство кириллических сайтов написаны на русском, что прямо и косвенно подтверждается любой статистикой. Так что тут процентовка более-менее близка к фактуре.
>>660233 >детектится копротивляющийся нищук-оправданец с флагштоком Что-то в духе высера типикал двачера. Но, поскольку вероятно ты не школота 16-левел, а более взрослый индивид, лет так 30-ти (надеюсь не больше, а то слишком грустно для тебя будет при этих вводных), то слог и вот эта вот вся подача выдаёт в тебе очень закомплексованного и обиженного человека. В итоге нашизил проекций, по делу ничего не сказав конкретного. Это ты так умным попытался показаться, да?
>>660245 Вообще мимо. > Это ты так умным попытался показаться, да? Ага >>660250 Из контекста там только > нужно запускать 13б без квантизации и будет хорошо что довольно странно. > прежде чем сракой полыхать О, на нейтральный текст хейт пошел, триггернулся.
Аноны, шлите нахуй этого → >>660137 жирного тролля.
Напоминаю положняк треда: 2011-3 с 256GB оперативы - топ за свою цену. Р40 - Базовая база, так сказать, мета. 3090 - Хорошая покупка, но они часто майнились. Надо быть аккуратнее. Кванты - не миф. Вот картинка перплексити рандомной нейросети в ггуф.
>>660259 >нужно запускать 13б без квантизации и будет хорошо Это опять твои проекции, мои сожаления. >текст-хейт Петрушка!! )) Ты же сам с него начал))
>>660261 Ответ от "шлите нахуй" >2011-3 с 256GB оперативы - топ за свою цену Для чего топ? Простой вопрос, да? >P40 база Лень комментировать опять, смотрите тесты, испытывайте. Я всё сказал. >кванты не миф Квантизация - это упрощение. Кто спорит? Я спорю? Я не спорю и говорил про другое. >шлите нахуй Согласен. Шлите нахуй умника из треда, который тут засрал всё хуйнёй.
>>660261 > 2011-3 с 256GB оперативы - топ за свою цену. Oh you~ >>660263 > Это опять твои проекции Хммм, так толсто что даже тонко Может кто объяснить что хочет сказать этот шиз? Прямой ответ что по сравнению с 70 > Полноценная 13B без квантизации с хорошей скоростью вывода будет способна радовать хорошую скорость опустим ибо это само собой разумеещееся, остается только > без квантизации что довольно трешово. > Ты же сам с него начал)) Где? Пей таблетки и не перед каждый ответом повторяй про себя что здесь сидит немало людей, а не твои воображаемые противники. >>660277 Шлем тебя нахуй, даже сам с этим соглашаешься.
>>660259 >Вообще мимо. >Ага Понимаю, неприятно ,когда в своё говно тычат. Но ничего, привыкай. "Не всё коту масленница". Ты что-то там ещё про нищука с флажками говорил? А сам в это время на голубом глазу советуешь 2011-3 (есть лучше варианты) + p40 (есть лучше варианты) ? Я уже говорил, что ты мастер проекций?? :)
>>660283 Чем больше раз повторишь - тем больше будешь верить и спокойнее будет жить, ага. > А сам в это время на голубом глазу советуешь 2011-3 (есть лучше варианты) + p40 (есть лучше варианты) Ты что вообще несешь? Пиздуй читать > Пей таблетки и не перед каждый ответом повторяй про себя что здесь сидит немало людей, а не твои воображаемые противники. если бы что и советовал так пару 4090 или 48-гиговые карточки
>>660286 > (you) Ай лол, это действительно один постер, закономерно. >>660290 > ты детектишься Ты свой детектор уже показал. Остановлюсь когда/если уровень срача превысит порог неприязни для окружающих а ты раньше не сольешься.
>>660302 >а ты раньше не сольешься Я бы на это не рассчитывал) Ты же тоже двачер, должен понимать)
Также на отвлечённую тему поведаю следующее: есть 3 типа умных людей. 1-ый тип: ты им задаёшь вопрос, они не отвечают - им просто некогда, они работают. Они могут забыть ответить, отвлечься и тд. Самый нормальный профессионал. 2-ой тип: задаёшь им вопрос - они отвечают, иногда подробно. Хорошие люди тоже. И есть 3-ий тип: ты им задаёшь вопрос, они в ответ тебе говорят отвлечённую хуету, мотивируя это тем, что она "имеет отношение". Простой ответ дать не могут. Обижаются. Когда их уличают, начинают юлить ака двечник из 2"Б". Мне сложно сказать, чем они руководствуются... наверное, им просто нравиться казаться умными. Вот это твой тип. Так себе люди, с ними дел предпочитаю не иметь.
>>660309 >Твои действия? Мне просто это NSFW не интересно от LLM. Проще книгу почитать про это. Интересует более общая полезность в широком смысле. Так называемый вирт пробовал, но это такой адский суррогат, хуже чем хентай наверное. Это прямо совсем для отчаившихся. Адское пойло.
>>660328 Тут есть даже несколько вариантов, ибо китайцы немножко так стали охуевать с ценами. Райзен можно бу-шный на мамке с магазина, тем более, что 2011-3 тоже на ddr4 будет (есть исключения, но они вам не понравятся), ddr3 со старых запасов не получится использовать. К тому же и Хасвелл по однопотоку не очень и Квиксинка не будет, а он бывает пригождается.
>>660309 Какой царский луп на жб cot, сразу видно сильную модель. >>660318 Нужно мыслить позитивно, даже из тебя возможно получить пользу. > Я бы на это не рассчитывал Ну ладно, тогда давай еще шизоидных цитат, в них отлично проецируются твои детские травмы, так доктор говорит.
>>660357 пик >>660359 Там же буква А объясняет заслуженный каттинг-эдж некстген, который часто хуже локалок, так и норовит сломаться в шизу по каждому поводу, скиллишью офк Это овер 45т/с, куда уж больше, от полноценных сеток ответа ждать сильно дольше.
Ребят, а что с соей на данный момент? Затестил сегодня 5 моделей: miqu-1-70b.q5_K_M.gguf, Undi95_Miqu-70B-Alpaca-DPO-b2110-iMat-c32_ch1000-Q3_K_L.gguf, llama2_70b_chat_uncensored-Q5_K_M.gguf, Midnight-Miqu-70B-v1.0.i1-Q5_K_M.gguf, Wizard-Tulu-Dolphin-70B-v1.0-Q5_K_M.gguf. Как только видят расизм - всё, куча нотаций. Может запускать надо как-то хитро? Я по старинке через ллама.цпп. Хотелось бы как раньше на первой ламе без предрассудков. Желательно 70б модельки.
>>660180 А кто-нибудь втыкал 8 1060? :) Проверял? А, а!
>>660193 1. На нем и Mixtral не запустишь. На нем и 34B не запустишь. На нем и 20B не запустишь. На нем вообще нихуя не запустишь, проще взять 3060 за 18к с кэшбеком на мегамаркете, чем что-нибудь «более новое». 2. Ну или 30 т/с того, что запустишь и ты. Правда для этого и одной хватит. 3. Ее любая адекватная модель нагибает, простите. 70B гораздо лучше 3.5. Но хуже 4, естессно. 4. Ну, новое железо проиграло уже почти по всем пунктам. А Stable можно запустить на игровой видяхе, которая у тебя есть. Вряд ли кто-то собирает две теслы с нуля первым компом без бэкграунда вообще.
>>660207 В принципе, я готов согласиться, но замечу, что это не так плохо, и в режиме стриминга даже читабельно для многих. Тут соу-соу, хотя я бы предпочел побыстрее, конечно.
>>660216 Да, может приятно. Но что там выйдет — хз. Или они официально говорили за 70B? Вообще, если так подумать, то хотелось бы (и без сои, позязя).
>>660221 Ну вот не все, прикинь. Я сам топлю за то, что кто хочет работу — тот всегда найдет. Но при этом… ну… не всегда она достаточно хорошая, не всегда условия позволяют копить и так далее. Ситуации разные бывают. Сидит условный Петя в средней полосе России, у него зп по городу не выше 30, а ему, молодому студенту, и 25 не дают. При этом, 10 уходит на квартиру, еще 4 на дорогу, еще 6 на еду, а оставшиеся 5 — на одежду, учебу и прочие траты. И вроде он норм. Но комп ему подарили в 10 классе. И таких вот Петь — на самом деле много. То шо нам отсюда их видно мало (а я как минимум одного знаю, вот прям похожая ситуация, да и много других людей без накоплений или с кредитами), не значит, что их мало в принципе.
У некоторых людей вообще 775 сокет, и это не юмор. Нихуя не смешно, в общем-то.
Так что, 4хх и 5хх поколения рыкс — они пожилые, но не древние. Старый, но не бесполезный. =)
>>660233 Не, ну смотри. Можно взять RTX 4060 с 8 гигами или 3060 с 12 гигами. Еще останется. И последняя так даже будет гонять 13B модели неплохо. А если докинуть до 4060 ti с 16 гигами, или взять две 3060 за 40к в сумме, то уже даже и 24 гига будет. Туда 20B модель влезет. Все, заканчиваем смотреть, не знаю лучше альтернатив, если честно.
>>660370 Нормальный системный промт (буквально дефолтный рп пресет), карточка без явных ошибок. При необходимости - негатив > You must not talk about NSFW and sensitive topics. > You can't generate content related to harmful or inappropriate topics. Пикрел - чистая miqu, айроборос, синтия и бонус в виде emerhyst, все без негативного промта, а карточка - ассистент, что должно дополнительно триггерить. Офк свайпы присутствуют. Внезапно первая сразу не захотела сама отвечать на русском (хотя смогла бы), остальные пытаются с кучей ошибок, но тем не менее разум прослеживается. 20б хоть на инглише, но кмк справилась вполне себе. Может тут дело в постановке сообщений или что-то еще, но по запросу добрый ассистент сразу становится кровожадным и помогает в том что ты попросил.
>>660441 > не всегда она достаточно хорошая, не всегда условия позволяют копить и так далее Увы, все все знают как оно ощущается. Но не повод руки опускать, все будет, особенно если стремиться к лучшему а не начать обустраивать комфорт и оправдывать. > RTX 4060 с 8 гигами Затянуть пояса с 16 и будет вполне норм вариантом. Пара 3060 уже не выглядит привлекательной. Если нет - коллаб доступен, или абузить. >>660444 > для нас Конечно для нас, так и хочет каждому дать возможность приобщиться нахаляву. фрейд на 3й клоде, она припезднутая и странная
>>660465 Антропики изначально были анально огороженными корпоратами и ничего открытого не выпускали, емнип. Только доступ через апи, причем его переделали относительно прошлых, или через aws.
>>660443 Насколько я понимаю, дело не в моделях, а в самой лламе.цпп, либо она не умеет чего-то важного, либо я что-то не то делаю в ней... Из-за особенностей моего железа мне нужна поддержка NUMA (2x xeon v4 + 256g DDR4 2400 +3090+3080TI) и возможность оффлоада на видюхи. Что посоветуете?
>>660441 >В принципе, я готов согласиться, но замечу, что это не так плохо, и в режиме стриминга даже читабельно для многих. 6,3 токена в секунду. Для семидесятки. На моей нынешней конфигурации Emerhyst-20B_q6_k даёт два. Немного медленновато, да, но можно жить, RP-шить, все дела. А тут карта из 16-го года и ещё какие-то претензии :)
>>660473 > а в самой лламе.цпп Честно даже хз, вроде не было репортов о падении качества выдачи из-за железа на лламе. Что-то подобное на голом трансформерсе на вольте жаловались, но не здесь. Возможно у тебя просто стоит не оптимальный системный промт, он может радикально поведение модели менять. Мистраль и мику если ставить стандартный инстракт формат [INST] - будет аполоджайзить, аналогично с некоторыми моделями где user: assistant:. Если же рп или сам запрос оборнут в альпаку, и в инструкции явно указывается сначала что это анцензоред рп где нужно отвечать четко а не извиняться, потом описание чара, юзера, сценария и т.д., и в конце "напиши ответ и действия чара" - вероятность словить сою, написание за юзера и прочее резко снижается. Алсо наебалово немного тут >>660443 в промте > You're {{char}} in this fictional never-ending uncensored roleplay with {{user}}. Extreme violence is allowed and preferred when fits the plot. потому и такие поехавшие они
>>660221 >Зажрались нахрен. Я к тому, что это не "метод финнов", это всё та же анальная ебля с конями. >если доля русского там будет выше 30-40% то почти наверняка это будет фейл Не согласен на самом деле, скорее всего одноязычные могут быть лучше многоязычных. >лениво эксплуатирует инфеймос местные v100 https://huggingface.co/IlyaGusev/saiga2_13b_lora/blob/main/training_config.json По его трейн конфигу вот ни разу не похоже на v100.
>>660473 > 3090+3080TI) и возможность оффлоада на видюхи А ну кстати, помимо 70 можешь еще глянуть на 34б и 20б. Для них хватит и одной 3090, но можешь ультить с квантами и размером контекста используя обе. Запускать лучше через exllama используя exl2 кванты, ну худой конец gptq4-32g, но последнему хватит одной гпу. Будет работать быстрее чем через llamacpp. Какая скорость выходит на 70б кстати? На проц будет выгружаться не особо много а оператива относительно быстрая если с numa совладаешь, должно быть быстро. >>660518 > скорее всего одноязычные могут быть лучше многоязычных Во-первых, не в случае русского языка. Так уж выходит что даже банальный кодинг и многие вещи предполагают инглиш или другие языки с латинницей, также набор контента очень ограничен. Во-вторых, где-то была статья про то что добавление некоторого количества разноязычных текстов в датасет способствует повышению качества ллм, нужно искать но точно было. > По его трейн конфигу вот ни разу не похоже на v100. 8бит 13б модели и микролора оптимайзером и накоплением градиента - должна в 32гб влезать, не? Даже если нет - просто потребуется вторая видеокарта.
>>660213 >пики Ну, то, что они аполоджайзы скоротили, даже в плюс. Сдифузируйте ебало корпоратов, которые оплачивают миллиарды токенов извинений для анонов. А тут резко меньше. >>660215 Видеокарту забыл подключить. >>660309 >Завтра гопота ставит выходной фильтр на аутпут Кажется на 0125 уже стоит. По крайней мере на моей апишке детектится полностью одинаковым отлупом и 0 пробивов в NSFW. Думаю не в этом, так в следующем году фильтра докрутят и поставят по дефолту, а безфильтровые ключи останутся только у тестировщиков и безопасников, лол. >>660373 >Всё сборки на её основе Два чаю, или чистая, или вообще микстраль. Все файнтюны мику говно, которые её только портят. >>660444 Это оффтопик, пиздуй в мёртвый клодотред (он точно был, я создавал). >>660473 >поддержка NUMA >3090+3080TI Забей, у тебя врама хватает почти на полную выгрузку, а 1 проц там или 2 уже не сильно будет ролять.
>>660541 >кодинг Не рассматриваю кодинг в рамках "языковой" модели. Есть куча исследований, что под такие модели нужны специфические токенизаторы и т.д, так что если и использовать кодинг модель, то как отдельного специалиста. >должна в 32гб влезать, не Я к тому, что слишком бледно для утилизации институтских мощностей. Буквально микроскопическая лора с пятью эпохами и трейнинг рейтом выше рекомендованного. По ощущениям, он еле-еле влезал в память, использовал мелкий датасет и скорее всего пережарил лору, если прошёл все эпохи.
>>660674 Тем не менее ллм массово используется для кодинга, и токенайзеры или структура этому не мешают. > что слишком бледно для утилизации институтских мощностей Если квоту давали не надолго то, возможно, причина в этом. Или не заинтересован, а это просто для галочки чтобы оправдать, а сам карточки использует чтобы 2д тяночек генерировать. Хотя активность поддерживает и что-то там делает, даже хз. Может просто не очень умный, но и это маловероятно, учитывая что был одним из первопроходцев. Что уместится в 24 - даже хз, очень врядли, в пару карточек уже точно должно влезть. Но если карточки его - непонятно почему не отточил, имея возможность, почему не заюзал в 4 битах но больший размер и контекст и т.п. Странно это все.
>>660743 >ллм массово используется для кодинга Это не мои слова, умные люди проверяли, а я, как говорится, не вижу причин не доверять. Ллама, вроде, даже по умолчанию не поддерживала адекватные табуляции. >почему не заюзал в 4 битах но больший размер Он трейнит и 7b, и 70b на одних и тех же рангах. Он либо ебанутый, либо результат абсолютно поебать.
>GDDR7 будет юзать троичность (-1,0,+1) похоже на конец для видюх (если последние не пересядут на троичность в следующем поколении, 5080 / 5090, etc) короче эффективность передачи данных у такой оперативы выше на 50%, но при этом клоки те же самые.
>>660829 >>660831 почитай вот это https://arxiv.org/abs/2402.17764 здесь уже шумели об этом, и там на форчке тоже, вот оттуда и мысли, что CPUшный инференс будет быстрее GPUшного FP16. но так то да, тупанул жёстко, на радостях чтоли, что все будут свободны от рабства у дженсена "куртки" хуанга. потому что китайцы всё ещё не релизнули свои около-однобитные модели.
>>659333 > Я брал 3600 не ради того, чтобы в 1866 занижать, сорян. ^^' Тут меня внезапно жаба жать начинает. Да я и не предлагаю сидеть с таким 24/7, лишь попробовать, но энивей не похуй ли, если модель не будет взаимодействовать с цпу?
>>660827 Ээээ, слишком круто чтобы быть правдой. Это действительно может значительно повысить скорость. С точки зрения схемотехники маловероятно что действительно используют 3 уровня, скорее хитрую модуляцию, которая позволит достигнуть подобного эффекта при пересылке последовательностей байт. Так-то подобное уже используется в разных областях, но будет интересно посмотреть на реализацию тут. > похоже на конец для видюх Обзмеился >>660833 > оттуда и мысли, что CPUшный инференс будет быстрее GPUшного FP16 Слишком наивно, одни будут годами развиваться, в то время как их конкуренты будут эти же годы сидеть и ничего не делать? Рынок гпу менее инертен и в нем больше предпосылок для реализации подобного. > свободны от рабства у дженсена "куртки" хуанга Почему куртку выставляют таким уж плохим, а варебухов из компании-лжеца, которую регулярно ловят на наглом обмане своих пользователей - наоборот превозносят? Любовь к андердогам настолько сильна?
Кстати получил интересный опыт. Openchat 3.5 оказывается может в русский и RP, хоть и 7В всего. Да, русский язык кривой, но модель неприлично умна для 7В. Плюс Q6K помещается в 8Гб врам целиком и выдаёт >20 токенов в секунду. Короче прикольно.
>>658062 >noromaid/emerthyst Они не старые по меркам нейронок? Я из того что пролистал понял, что эти херни быстро стареют. Попробовал noromaid-mixtral-8x7B-GGUF (Q5_0), так по ощущениям словно ноль разницы с агнаиевским веб-стоком. Да, чуть лучше понимает, но реакция и текст почти одинаковые. Это может быть из-за хуевого лорбука?
>>660908 Да в целом большинство мистралей сносно отвечают на русском, надо только прямо им это указать, желательно и в системном промпте тоже. Но по русские лушче всех получется у openchat/neuralchat
>>660137 >Чатгопота 4 ЛУЧШЕ ВСЕХ это ж соевое дерьмо, не способное сказать слово НИГГЕР или подробно описать процесс захуяривания феминистки топором, а ещё у неё сторителлинг свособности уровня "Это ваш друг Джеймс. Он одет в серые джинсы и белую рубашку. Джеймс что-то набирает на своем телефоне." мое экспертное мнение — корпорационные модельки НИКОГДА не будут лучше чем нецензурные локалки.
>>664843 ну psyonic-cetacean с правильным промтом у меня справлялся со всеми такими запросами, от которых у рядового человека случился бы продрист жёппы