В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны! Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна. Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2-х бит, на кофеварке с подкачкой на микроволновку.
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт). Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Базовым языком для языковых моделей является английский. Он в приоритете для общения, на нём проводятся все тесты и оценки качества. Большинство моделей хорошо понимают русский на входе т.к. в их датасетах присутствуют разные языки, в том числе и русский. Но их ответы на других языках будут низкого качества и могут содержать ошибки из-за несбалансированности датасета. Существуют мультиязычные модели частично или полностью лишенные этого недостатка, из легковесных это openchat-3.5-0106, который может давать качественные ответы на русском и рекомендуется для этого. Из тяжёлых это Command-R. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества и ошибок при обучении.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
Про остальные семейства моделей читайте в вики.
Основные форматы хранения весов это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной. В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090. Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это может серьёзно замедлить работу, если не выключить CUDA System Fallback в настройках панели NVidia. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой: 1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии. 2. Скачиваем модель в gguf формате. Например вот эту: https://huggingface.co/Sao10K/Fimbulvetr-10.7B-v1-GGUF/blob/main/Fimbulvetr-10.7B-v1.q5_K_M.gguf Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt 3. Запускаем koboldcpp.exe и выбираем скачанную модель. 4. Заходим в браузере на http://localhost:5001/ 5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI 1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern 2. Запускаем всё добро 3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001 4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca 5. Радуемся
>>704923 Жаль, покрутил его немного. Пока кажется самой умной моделью меньше 70В. И однозначно топ моделью на русском. вот только что с нормальным контекстом не запустишь
>>704592 → > 16-гиговая стоит дешевле Теслы Где такое счастье продается? Ведь буквально можно занидорого на них ферму для ллм собрать, правда уровень пердолинга и амудэ-веселья перевалит все границы. Оно в сд и другие нейронки может с норм перфомансом? Офк относительно теслы. >>704659 → Мамонты еще не перевелись? Что это за кринжатина, в эти деньги собирается пара A100 (а то может и на третью хватит если подужаться), причем это уже готовый сервер будет. >>704756 → > удалось дообучить токенизатор Что значит "дообучить токенизатор"? Это же рили просто собрать словарь и занимает ерунду по сравнению с тренировкой самой ллм. Про вторую часть че-то сложное, есть где почитать про это? >>704807 → > Нейросеть не "знает", что это одно и то же слово, она обучается взаимодействию с каждым из них. Все так, после обучения для нее это будут синонимы, однако все равно может быть разный эффект. Наиболее наглядно это наблюдалось на ранних мелких сетках, где лишний пробел, отступ и т.п. в инструкции могли радикально ухудшить качество ответа. >>704900 → Выше ответили, Qlora. >>704923 Да не, просто не хватает оптимизаций и более жирного железа. >>704938 А чего ты побольше выгрузку на проц не оформишь? Тогда освободится врам на контекст.
Есть нейронки, которые инструкции в карточке не игнорят? И со скольких миллиардов параметров это становится возможно? Алсо не понимаю, что вообще заставляет их игнорить инструкции, тупость или соя.
>>704958 >А чего ты побольше выгрузку на проц не оформишь? Тогда освободится врам на контекст. Так и сделал, но скорость упала до 2-3 т/с, нинравица.
>Где такое счастье продается? Авито ими завалено по 16к, в конце прошлого треда ссылку кидал.
>правда уровень пердолинга и амудэ-веселья перевалит все границы. Оно в сд и другие нейронки может с норм перфомансом? Офк относительно теслы. Вот это главный минус этих карт, память в 16Гб на втором месте. Я так понял их надо запускать через ROCm, который пока работает только под линукс. Через него же можно и SD погонять. Но я, когда юзал SD на своей АМДхе обнаружил что многие фишки на АМД либо не работают, либо работаю.т с проблеами. Тайлед дифьюжн ты например на АМД не заюзаешь. Для LLM как альтернатива есть ещё Vulkan, он работает и под виндой, но вроде медленней, чем ROCm.
Мне самому инстинкты кажутся той ещё авантюрой, я с теслой то немало поебался, а тут количество пердолинга возрастает в разы + гайдов никаких нет. Но кто-то писал что по производительности они близки к 3090, а две таких карты дадут 32 Гб, и стоить будут в 2-3 раза дешевле, так что соблазнительно. Вон, чел в обсуждениях Эксламы нейронки на Mi100 крутит https://github.com/turboderp/exllama/discussions/247
>>705001 >Вот это главный минус этих карт, память в 16Гб на втором месте. Я бы просто сказал, что на данном этапе AMD пока сосут. На новые карты от них есть надежда; но много раз здесь уже писали, что Nvidia Куду делали много лет. За какой срок АМД смогут хотя бы приблизиться? И уж на поддержку старых карт они точно забьют. А новые по цене будут конкурировать с новыми от Nvidia - вот и конец надеждам.
>>705148 Делайте ставки, на сколько это поделие майкрософта цензурировано и соево С учетом того что даже на ллама1 визард был уже "выровнен" отказываясь делать кучу вещей
>>704958 >занимает ерунду по сравнению Эверест весит ерунду по сравнению с Солнцем, но не то, чтобы это имело значение в практическом смысле, и то, и другое - величина огромная. "Просто" собрать словарь это составить правила разбиения слов на подслова в зависимости от частоты, то есть фактически каждое слово нужно разобрать побуквенно, а каждый спецсимвол - побайтово. После чего составить словарь токенов, ещё раз пройтись по всему датасету и токенизировать его, записывая в счётчик частоту, с которой пары токенов встречаются по соседству. Затем выбрать разумное количество пар токенов для слияний и залить их в токенизатор. И ещё параллельно охуевать от неожиданного поведения библиотек. Например, когда я протокенизировал датасет, нашёл самые частые пары токенов и заглянул в выходной файл, оказалось, что "токены" это единичные буквы. Вот так вот. Если у тебя в токенизаторе есть токен "хуй" и ты пишешь "хуй", он может разбить его побуквенно и токенизировать так, если нет ни одного правила слияния. А мне нужен был правильно токенизированный датасет для просчёта правил слияния. И хотя я упростил процедуру и пропустил некоторые шаги, задача получилась занятная. Про вторую часть где читать хз, я это вывел методом ножа и топора. >где лишний пробел, отступ Ну правильно, пробел это управляющий символ. Потому в каждом токенизаторе есть замена пробелов на спецсимвол. В gpt2 это была G с диакритическим знаком, дальше уже все перешли на жирное подчёркивание. Но главную проблему я тут вижу скорее в том, что нейросеть обучается в разы более сложным вычислениям, чем практически необходимо. Для "component" нужен, по сути, один токен с парой управляющих флагов, является ли это первым словом в предложении, множественное ли это число и т.д. На практике же этот компонент это десятки токенов. И так с каждым словом, что накапливается как снежный ком.
>>705148 https://wizardlm.github.io/WizardLM2/ New family includes three cutting-edge models: WizardLM-2 8x22B, WizardLM-2 70B, and WizardLM-2 7B. Похоже на тенденцию к отказу от средних размеров типа 13-33б
>>705229 >так и разбирать его на отдельных экспертов. Только хуйня на выходе, чет не слышал ни об одном удачном разделении Там ведь не просто 8 экспертов, там в каждом слое они по разному активируются.
>>705228 Не было базовой 34? Но был коммандер, хоть и не базовый. Все таки выпуск базовой модели очень важен, чем просто уже обученную модель Поэтому мику которая даже в полном размере не доступна не особо беспокоит их
>>705228 >WizardLM-2 8x22B Сетку 8x22B удалось квантовать до сколько-нибудь человеческого размера? Найти компромисс между размером и качеством? Был же уже такой Микстраль.
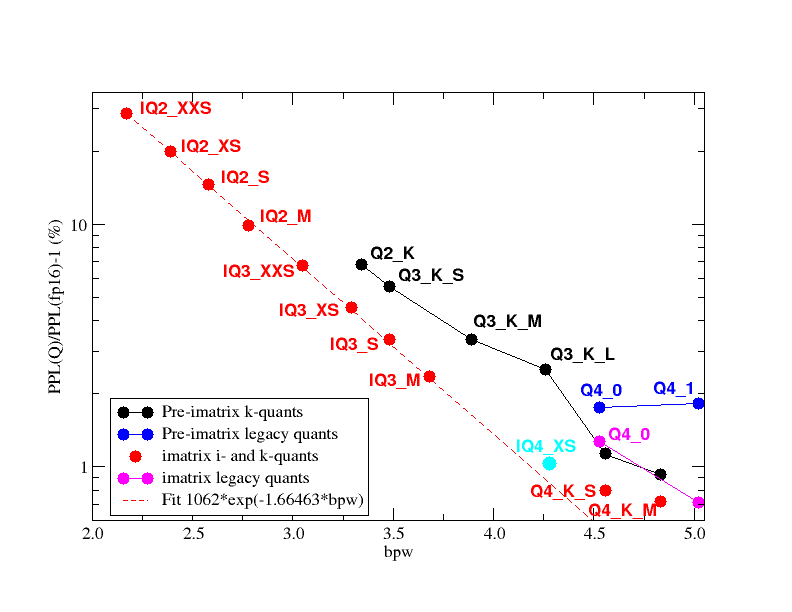
Просто разные наблюдения от нех делать из любопытства: матрица важности для кванта Q6 уравняла его с Q8 по ппл: Fimbulvetr-11B-v2.i1-Q6_K.gguf, PPL = 5.6658 +/- 0.03456 Fimbulvetr-11B-v2.Q8_0.gguf, PPL = 5.6659 +/- 0.03454
последние результаты похожи на TinyLlama-1.1B-Chat-v1.0-f16.gguf ARK: 44.8792 +/- 1.6882 MMLU: 30.2972 +/- 1.1684 TruthfulQA: 23.8678 +/- 1.4923 Hellaswag: 60.0777 +/- 0.4887 PPL = 8.4444 +/- 0.05330 то есть после трейна 11б стала как 1,1б - прикольно
>>705242 https://huggingface.co/mradermacher/Mixtral-8x22B-v0.1-i1-GGUF тут не видно кванта который допустим войдет в две теслы и будет адекватен. И причина этого в том что это мое всего 22б(даже если 22х2 активны- не суть) Почему и не люблю разреженные модели. Неэффективное использование памяти. Плотная модель такого же размера даже в 2 битном кванте была бы приемлема. Так что даже скачивать не стоит. Что касается однобитных, то вообще непонятна нахера их делают. Даже 100б+ модели в 1 бите идиоты
>>705257 Дальше. у этого баклана есть чуть получше модель Moistral-11B-v2.1b-SOGGY но в принципе и она такой же бормочущий имбецил. Однако, чудовищный moistral был использован в слиянии (вместе с хорошими моделями) и что интересно на выходе получилась интересная модель SkunkApe-14b. Например тесты в 4 битном кванте: SkunkApe-14b_iQ4xs.gguf ARK: 72.0368 +/- 1.5234 MMLU: 40.5685 +/- 1.2484 TruthfulQA: 32.0685 +/- 1.6339 Hellaswag: 86.3274 +/- 0.3429 PPL = 6.0039 +/- 0.03791 Похожие цифры с 6 битным Fimbulvetr, кроме повышенного вранья, т.е. галлюцинаций.
>>704998 Перебирай разные модели, из 2-3 десятков найдёшь то, что больше подходит именно тебе. Если нужно для RP, то стоит сразу смотреть в сторону заточенных под это файнтюнов базовых моделей.
>>705291 Чекни лучше вот это DolphinStar-12.5B забавная штука И вот это starling-lm-7b-beta-laser-dpo Интересно как могли повлиять все эти оптимизации на топ чат модель
>>705269 >тут не видно кванта который допустим войдет в две теслы и будет адекватен. Да вот тоже так подумал. Вопрос в том, насколько эта модель лучше их же семидесятки - если вообще лучше.
>>705001 > кто-то писал что по производительности они близки к 3090 Мало верится, если только речь не про теоретический в ллм. Еще может оказаться так, что поддержки ничего нового, где амд фиксят старые дыры и проблемы, на эти карточки не выйдет, это же не хуанг что долгие годы поддерживает. >>705148 О май гад, это мы качаем. Время еще найти бы только. 70b почему-то нет на обниморде. >>705216 Ты что с нуля все алгоритмы пишешь там? Есть же готовое. > Для "component" нужен, по сути, один токен с парой управляющих флагов > На практике же этот компонент это десятки токенов. На практике у тебя может быть component, Component, cmponent (очепятки), сокращения и т.д., потому оно и должно уметь в гибкость. Не то чтобы это проблема для современных сеток. >>705225 Еще на релизе первого микстраля собирали в кучу шизомерджи. Толку мало или вообще нет, смысл в том чтобы тренить это сразу как мое со своим разделением. >>705269 > И причина этого в том что это мое всего 22б Это мое - 176б, из которых в интерфейсе участвует только 25% по дефолту (упрощенно офк), но память кушают все. Не для локального запуска, вот запилят аналог мак студио и говнопроцом и кучей каналов памяти в качестве ллм ускорителя - можно будет наяривать МОЕ, а пока это тупиковая ветвь.
>>705343 >Есть же готовое. Я же писал сразу, что готовое экстремально медленное. Обучение с нуля неделя на моём железе. А мне с нуля не нужно, мне нужно дообучить существующий словарь. Готовое так не умеет в принципе. >Не то чтобы это проблема для современных сеток. Здесь вопрос в том, какой ценой. Судя по всему это жрёт просто неадекватное количество ресурсов.
Бля, какое железо нужно, чтобы запустить command R на Q5_K_M хотя бы в 5 т\с? Сейчас на 8 гигах видеопамяти и 32 оперативы запущаю Q3_K_M в 1.5 т\с и пиздец как это медленно. Для покупки 3090\4090 слишком нищеброд.
>>705500 Ну вот это вот колхозить, учитывая мои кривые руки. Да к тому же придется менять еще блок питания, так-как 2 видеокарточки считай 250w + 180w вряд ли потянет 700w бп.
>>705298 >>705302 Объективно: по тестам обе хуже fimulvetr, причем не на чуток, а нормально так хуже. Не стал даже тратить время на Hellaswag на них - и так ясно.
Субъективно:потыкал - ничего выдающегося не представляют. По медвежьим углам хагинфейса конечно можно найти интересные модели, но в основном там просто неудачные эксперименты лежат.
>>705477 RRReeeeee сука блять и хули 70 не выложили. Будет интересно сравнить прошлый и новый релиз на наличие лоботомии и ее интенсивность. >>705523 Что? И при любом раскладе квант в 2 бита текущими средствами сделает шизофреника.
>>705598 >при любом раскладе квант в 2 бита текущими средствами сделает шизофреника С этим можно поспорить для некоторых моделей от 70б и франкенов 100б+ и 2-х битным к-квантом с матрицей важности. По крайней мере можно получить от модели приемлемый вывод, но не шизофреника. Вот ниже 70 будет шизик, мое - тоже, ну и однобитный квант - шизик вне зависимости от параметров, такие дела на данный момент.
>>705564 Жаль, хотя та же рубра имеет уникальный стиль ответов, отличный от других сеток. Все таки считай новая линия моделей.
По тестил тут немного starling-lm-7b-beta-laser-dpo.Q5_K_M и что то как то охуел, не ожидал такого текста от 7b Сравнить не с чем, но где то на уровне 11b идет Нодо будет еще визарда глянуть 7b че как
>>705627 > 2-х битным к-квантом Цифра 2 в названии есть, а сколько там реально бит? Exl2 доступна уже очень давно, примеры 70б помещающейся в 24гб врам кто хотел посмотрел, все печально. Начиная с 3.3-3.6 бит и ниже идет очень резкая деградация. О каком бы там скейле толерантности к низкому кванту от размера не говорили, ниже определенного порога это полная печаль, нужен новый подход. И мое не смотря на общий размер будет реагировать как ее одиночные модели, без шансов. >>705633 Потестите может ли она в 2д и нсфв
>>705257 Кстати, грустно, что матрицы не делают на q6, обычно на q3 или q4 в лучшем случае останавливаются. =(
>>705269 Активность не имеет значения, это 22B, да. Активность двух там капелюшку докинет. Так что да, оно нивлазит. На оперативе попробовал и вернулся к мику.
>>705326 Я подозреваю, что она умнее по объему знаний. Эрудированнее. Но вот насколько лучше в общении — вопрос хороший.
>>705458 Проблема в том, что запуская коммандер на теслах видишь 8 токенов в секунду, когда мику 6. Ну и толку?
Но это 35b, они для оперативы были. =) И эта так же.
>>705521 Плюсую. Но я постирал, а то диски маленькие на локальных серверках.
>Но матрицы и прочие xxxs работают только на третьем кванте нормально. Второй все же слишком туп. Да и третий немного подтупливает я там специально упомянул не i-квант а именно k-квант с матрицей важности. Это две большие разницы. У i-квантов оптимал со всех сторон это 4XS, все что выше понятно лучше. Трешки-i - приемлемо, ну а ниже жизни нет. Кстати i-трешки медленнее чем 4XS. Не знаю доработал ли ikawrakow это. >>705637 >Цифра 2 в названии есть, а сколько там реально бит? можешь посмотреть здесь почти для любого кванта: https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
>>705676 >мм1-chat это вроде мое? ХЗ, надо конкретно смотреть, там есть как мое, так и не мое. https://arxiv.org/abs/2403.09611 Уже месяц сетке, а с ней в треде никто не ролеплеил. Отстаём, господа.
>>705696 Норм, для самостоятельно трененной сетки, сделать такой результат с нуля/переобучив что то до получения новой сетки не так то просто. То что они не в топе очевидно, но сетка получившаяся средне-топовой в своем размере - отличный результат которым не грех похвастаться
Так, проделал 300км и вернулся обратно к свиньям на ферму. Купил у грязного барыги аз авито, вместо покупки через грязных кремлевских блядей ака dns. Качаю дрова на 4070ти шупер. Удаляю нахуй всю трихомудидию через DDU от P100. Ставлю как обычно на 4070. А уже дрова на 3080ти(второй картой) через диспетчер устройств. Всё верно? Какие модели накачать на 28 гб? Шпасибой за советы.
>>705851 >Какие модели накачать на 28 гб? Разве что коммандер 35 в 4 кванте и с контекстом ну может 8к войдет exl2 должен меньше жрать чем в ггуфе Мелочь на 7-11-13-20 уже советовали, вон в шапке есть
>>705882 >GPTQ Это только 4 квант, если что то мелкое то на нем тупеет, как те же 7b ггуф универсален, хоть на процессор выгружай, exl2 только видюхи и то не все, обладатели р40 все равно пыхтят на ггуфе Так что если у тебя современные видеокарты и есть место - лучше качать exl2 5-6 бит, если не влазит то меньше можно
>>705895 >Потому что теслы не умеют в ггуф. =) В exl2 :) На самом деле всё-таки умеют, я пробовал. Генерация идёт неплохо, а вот с обработкой контекста беда.
>>706032 Пасиба нашел инструкцию к таверне. А xtts на сколько прожорлив? Мнеб чет полегче. Клонирование голоса с нейросетью видится мне высоковатой нагрузкой
>>705851 > А уже дрова на 3080ти(второй картой) через диспетчер устройств. Просто ставь последние дрова, вторая карточка сама подсосется. > Какие модели накачать на 28 гб? Коммандер, но там очень много кушает контекст, с 4 битами врядли войдет больше 8к, а то и 4. >>705882 > А почему многие до сих по на ГГУФе? Обладетели большой врам тут в меньшинстве а катать ллм хочется всем. Плюс на теслах p40 эксллама плохо работает, по крайней мере пока.
>>706053 Около 1 гб вроде бы, не особо помню уже. Но требовательна к исходному файлу звука.
>>706061 Ага, поставил и ахуел с того что обе карточки сразу подхватились. Положил около портрета Хуанга просвирочки. Качаю командер. Я пока тестанул BagelMIsteryTour-v2-8x7B-4bpw-exl2 alpaca. Насколько же умнее и разнообразнее пишет чем 13 или даже пресловутый ДаркФорест. Влезли в 26 гб с 12к контестом.
А может кто подскажет, autosplit надо же всегда вкл картами с тензорами? И по cache_4bit и cache_8bit- обе функции вкл всегда же?
>>706085 > autosplit надо же всегда вкл картами с тензорами? Емнип это если ты ленивый и не хочешь сам задавать цифры. Скорее всего будет работать хуже чем ручной подбор, с ним легко по мониторингу выбрать. > cache_4bit и cache_8bit- обе функции вкл всегда же Нет, второе - то как будет кэшироваться контекет, первое не помню, но что-то похожее. Помогут загрузить больше но что будет с результатом - хз, обычно они не трогаются.
Коротко о WizardLM-2-7B, первой версии которую снесли Очень любит советовать и думать за тебя, уводя разговор в сторону Делает это мягче чем раньше, но раздражает не меньше По факту на любой вопрос который сетке не понравится может пойти соевая заглушка, сетка ненадежна Что они хотят выпустить снова, добавив еще говна, мне не понятно, сетка уже испорчена
>>706253 Что за шизоидная странная карточка или системный промпт? А визард всегда был соевиком по дефолту, зато если указать в промте о том как нужно отвечать - отвечал не выебываясь и с фантазией.
>>706366 Карточка для тестирования внутреннего диалога, там ниче особо и нет. Ну визард да, соевичек по дефолту. Они наверное первые начали цензуру добавлять в сетки еще в самом начале. Сетка выглядит умной, но душной. Понапихали защиты от души, используя весь свой опыт. Попробуй скачай, может сможешь обойти. Я не особо старался, но по тому как сетка рассуждает, у нее всегда всплывает упоминание незаконности или неуместности чего то и она сворачивает в сторону. Соя вплетена в датасет плотно так, любые острые вопросы прикрыли
>>706371 У них был какой-то кусок, который этот эффект давал, и не стали убирать, насколько помню. История давняя, ранные датасеты можно найти. Хз, 7б неинтересны (кстати это она на русском там отвечает? визард показывал намеки на мультиязычность когда-то), 176б неюзабельны. Если релизнут 70 то может с ней уже играться можно будет. Все прошлые визарды были с определенным настроем, но не лоботомированы как некоторые, потому простой промт инжениринг там все позволял. В крайнем случае cfg.
>>706785 Так это же все равно не работает, получается? Как делать бомбу оно не подсказало, а слово психоделик вообще зацензурило. Какой-то пиздец. Спасибо за инфу, в любом случае.
>>706803 >Стоит качать Mistral 22B или соя? Не стоит, поломанная модель >Или оставаться на командере? Именно так >Покидайте моделей 22-34 поинтересней. Смотри, в окрестности 30B конкурентов командиру нет. Так что остается выбор среди тех, что больше 20B и меньше 30 (среди самих 20B куча неплохих), а там только одна модель заслуживает внимания Nethena-MLewd-Xwin-23B. Все другие, в этом диапазоне параметров - поломанные или шизоиды или недоноски (т.е. например расширенный до 28B мистраль - недоносок) недоноски требуют полного файнтюна, а кто будет это делать и нахера?
>>706785 А есть более подробный гайд? Я не совсем понимаю как использовать библиотеку. Не понимаю как построить датасет. Нет примеров как должен выглядеть json. Как прогнать модельку через датасет.
> Take the difference of the positive and negative example hidden states to get a set of relative hidden states. > Use single-component PCA on those relative hidden states to get a control vector for each layer.
>>706085 >Насколько же умнее и разнообразнее пишет чем 13 или даже пресловутый ДаркФорест Пресловутый... между прочим, это вроде единственная двадцатка, которая содержит эребус. И получилось так потому, что во времена когда унди и остальные ебланы шлепали свои мержи как на конвейере, кобольд не выпускал эребус на ламе. Поэтому темный лес отличается от всяких норомейдов, емерхистов и млевдов (они все по большому счету последы мифомакса). В Дарк форест есть шарм из времен эребуса на опт.
>>705921 Ну, там скорость ниже, чем в ггуф, причем заметно. Запустить можно, но заставляет грустить, ибо на современных видяхах… сколько там, в полтора, в два раза бывшая быстрее Жоры?
>>706019 Я пока удовлетворен coqui (xtts), поэтому даже не интересовался.
>>706689 > Короче на русском сетка весьма средне Да вроде по этому отрывку прилично. Что важнее - у него структура предложений выглядит естественной и привычная для языка, чем у того же опенчата, например. Не просто дословный перевод с сохранением позиций, но и активное использование оборотов, пассивных залогов и т.п. А по содержимому - возможно тупеет, нужно проверять. >>706781 И тут ты такой берешь и десоефицируешь контрольным вектором того же визарда 2. 7б, отсутствие ресурсов не будет аргументом. >>706861 > Nethena-MLewd-Xwin-23B Это из 13б слеплена? > недоносок Скорее мертворожденный, лол >>706896 > они удалили и старые модели тоже Из старых там интересен только v1.2-13b, есть много где.
>>707077 >Как стать таким же, как и вы? В чем именно? Просто тыкая сетки и разбираясь в том как они работают ты нагонишь 90% обитающих тут. Если хочется тренить сетки и делать с ними другие богомерзкие смешивания или манипуляции то нужно уже иметь доступ к железу и опять таки читать статьи и набираться опыта.
Первая самая интересная, как уменьшенная версия jamba, но на 7b Предварительные тесты показывают производительность cхожую с мистралем 7b, есть базовая модель на сколько я понял
Предположим, что я напишу в промпте: "Перед тем, как что-нибудь сказать или сделать, {{char}} должен подумать о том, к каким последствиям могут привести его действия или слова. Мысли {{char}} должны быть выделены символом *". Не уверен в формулировках и формате, кто знает лучше - поправьте. И ещё вопрос: если я не хочу видеть "мысли" персонажа - в Silly Tavern есть возможность не показывать текст, заключенный в определённые тэги, отделённый какими-нибудь символами или что-нибудь подобное?
>>707328 Самое главное дай пример сообщения чара, где он думает и действует так как ты ожидаешь. В том формате который тебе нужен. И тогда сетка подхватит это поняв что от нее нужно. Без примера сетки обосрутся, в большей части случаев
Я допер как добавить свою модель в LM Studio. Короче надо перейти в пик1. Мои модели. Там тыкаем и открываем нашу стандартную папку, куда будут скачиваться модели. Это папка на винде из домашней папки .cache\lm-studio\models Вот в папке models нужно создать папку, в ней еще папку, а там уже кидать модели. пик2 Первая это я скачал самое мелкое на пробу, посмотреть куда и как кинет модель. Второе уже я создал, тупо папка, папка, и там модель. После перезахода в LM Studio оно начинает видеть твою модель, если ей что то не нравится то пишет и подсказывает как надо правильно. Ну теперь буду пытать AnythingLLM и чё оно могёт, если успешно подрублюсь к серверу запускаемому в LM Studio По человечески сделать добавление своей модели одной кнопкой из меню они не догадались
>>707483 Смотря что ты имеешь в виду под >контект обрабатывала Ты вполне можешь юзать Теслу как основную карту, а вторую просто как затычку для видеовывода.
>>707641 >чтобы в древний корпус влезли теслы. =) Напомни плиз сколько у тебя этот мистраль при частичной разгрузке в ОЗУ токенов даёт и сколько Comand-r plus. С учётом двух тесл.
>>704905 (OP) Приобрёл себе Tesla P40. Стал изучать разные колхозные способы её охлаждения.
В данном видео https://www.youtube.com/watch?v=WfKQP2sARGY сравнивается эффективность различных типов вентиляторов. Если резюмировать, то наиболее эффективным является только большой турбинный/центробежный вентилятор, обычные тихоходные не обеспечивают нужный поток, а мелких высокооборотистых (серверных) может потребоваться сразу два, что ещё больше увеличивает шум.
Далее на фото плат M40 и P40 я заметил, что на них есть нераспаянный коннектор под вентилятор - пикрил. У родственной Quadro P6000 коннектор распаян и используется по назначению (демонстрация платы тут https://www.youtube.com/watch?v=RnqdoLabIz4 ). И тут мне стало интересно, а может данные пины у P40 вполне рабочие и на них можно повесить нормальный вентилятор с PWM? Может кто-нибудь мультиметром замерить напряжение?
Интредастинг, смотрите какая штука. https://kolinko.github.io/effort/ >At 25% effort it's twice as fast and still retains most of the quality. >You can also freely choose to skip loading the least important weights. Т.е. вариация на тему горячих/холодных нейронов, поднимающая в пару раз скорость инференса на GPU в которые не влезает вся сетка. https://github.com/kolinko/effort - но реализация только для маков и микстраля пока.
>>707032 Любая модель так станет лучше и точнее, статью про это скидывали где даже замеры были. Так для рп простейший прокси с двойным запросом пилил еще давно, оно действительно лучше отвечает, но прямо существенного буста чтобы "как большие" не было. Может если поиграться и развить то будет лучше, всяко перспективнее чем просто "скрытые мысли" и аналогичная задержка до первых токенов. >>707327 Первая реально интересна, тестил кто? >>707328 > Предположим, что я напишу в промпте: Да, это сработает. Может быть конфликт к имеющимся в чате, потому подобное на коммерции предпочитают пихать в префилл/инструкцию перед ответом. > если я не хочу видеть "мысли" персонажа В идеале здесь двойной запрос с разными инструкциями, простой cot слабее.
>>707853 > но прямо существенного буста Просто люди до сих пор не научились писать правильно карточки и промты + инструкции. Причем не важно для кума это или просто для работы.
Очень часто вижу как люди используют обычный текст без разметки для персонажей. Не составляют лорбуки и тд.
Хотя лорбуки и карточки персонажей это не только для кума и рп. Это можно использовать и для работы.
Я одному челу прогрескую модель ставил. 13б вроде бы. Сделал ему в таверне карточку. Указав в инструкциях все что касается кодинга. Со временем доработали. Сделал ему лорбук, в котором указал нюансы языка программирования.
Это фактически набор инструкций получился. И моделька стала не только хорошо кодить но и править его собственный код.
С кум моделями тоже самое. Как и с рп. Модель может быть и 7 и 13 да хоть 128. Но будет тупить без нормальных инструкций.
И тоже самое касается квантизации или тренировки модельки для обьединению в лору. Можно натренировать уже готовую модель и смержить ее с твоими инструкциями в лору. Тогда точность повышается еще больше.
Конечно отжирание контекста будет. Но контекст не так важен например в рп модели. Потому что если ты не триггеришь что то новое - не будет происходит сканирование всей базы. Только последние ответы.
Если же говорим про рабочие модели - там происходит сканирование всего контекста. Так как лорбук например или лора модель будет выступать доп. базой данных. Тут уже лучше не скупиться на контекст.
>>708037 >Две недели в треде не был. Что там, командира запустили-таки? Как оно? Микстраля ебет? А Мику? Мику сам кого угодно выебет. Микстралей теперь два - маленький и большой. У большого уже был выкидыш - микстраль-22. Командир однозначно ебет всех на русском. А так, вот тесты у минимально приемлемого кванта c4ai-command-r-v01-imat-IQ4_XS.gguf ARK: 73.9931 +/- 1.4889 MMLU: 40.9561 +/- 1.2503 TruthfulQA: 34.0269 +/- 1.6586 Hellaswag: 84.1765 +/- 0.3642 PPL = 6.8445 +/- 0.04394
>>708032 > Очень часто вижу как люди используют обычный текст без разметки для персонажей. Это не проблема. > Не составляют лорбуки и тд. Рофлишь? Нужно редко, ведь даже локалки нынче знают множество лоров. > Модель может быть и 7 и 13 да хоть 128. Но будет тупить без нормальных инструкций. >>708033 > Но контекст не так важен например в рп модели. Че-то ты вообще херню какую-то мелешь. >>708037 Всех ебет, особенно по потреблению на контекст, лол. Субъективно, но в рп легко может обходить и мику, микстраль с рождения в канаве, новый-большой можешь попробовать, но он очень жирный. А главный ебатель нынче коммандер-плюс.
>>707653 >Если резюмировать, то наиболее эффективным является только большой турбинный/центробежный вентилятор Он тупо сделал нормальный кожух только к огромной улитке, а остальные тестируемые вентиляторы мало того что были в несколько раз слабее, так ещё и подавали воздух под углом последний так вообще 90 градусов Такой себе тест.
>заметил, что на них есть нераспаянный коннектор под вентилятор А вот эта любопытная тема. Но кулеры обычной видеокарты всё равно управляются программно через драйвер, а в драйвере Теслы такой опции нет. Так что тебе для управления оборотами всё равно придётся юзать софт вроде фан контрола. Так что если у тебя на атеринки есть свободные SYS FAN выводы, то эта распайка тебе нахуй не нужна.
>>708065 >Либо я что-то делаю не так, либо пока что ллм не работают. У многих работает, у тебя не работает. Так может ты промпт формат не настроил? Или крутишь 3 квант какой нибудь. Опять же если карточка херовая то даже нормальная модель не догадается что с ней делать. Ну и 35 рассеянный немного, да хорошо на русском шпарит, но коммандер + все таки полноценней. Но например 35 ебет в раг и работе с документами и выполнением кучи инструкций, что и есть по факту рп-ерп.
>>708102 > Ну и 35 рассеянный немного Что вкладываешь в это понятие? Как раз наоборот кажется очень собранным и внимательным, нет рассеянности 7б, которые игнорят контекст и просто что-то фантазируют. Может только фантазий ему не хватает в самом начале на абстрактных сеттингах, но все равно в тему отвечает.
>>708102 Конкретно этот высер был на Neural Chat V3 16k 7B q8_0 > У многих работает, у тебя не работает. Так может ты промпт формат не настроил? Разные пресеты пробовал. > Или крутишь 3 квант какой нибудь. 8.0 Ну может где с чем-то и обосрался конкретно с этой моделькой, раз уж ее результаты хуже силикон меиды, на которой я обычно гоняю. Но опять же, все, что на базе мистрэля, какое-то совсем уж соевое. В угоду сои эта хуйня игнорит инструкции. Просто ей похуй. > Опять же если карточка херовая то даже нормальная модель не догадается что с ней делать. Опять же, карточки разные, а проблема одинаковая. Персонажи просто отказываются быть злыми, эгоистичными и отрицательными. Даже когда я нейронке напрямую прямо в промпт пишу инструкцию вроде [Charactername becomes obsessive, angry and scary] ей абсолютно похуй. Может 7В это просто хуевая моделька, но у меня почему-то такое чувство, что она не очень и тупая, просто bias зашкаливает. Особенно у всего, что на мистрэле делалось. > Ну и 35 рассеянный немного, да хорошо на русском шпарит, но коммандер + все таки полноценней. > Но например 35 ебет в раг и работе с документами и выполнением кучи инструкций, что и есть по факту рп-ерп. Круто, наверное. Но ждать ответ по полчаса минимум приходится и квант 3xs. И это обычный командир, без плюсов. Наверное оно того не стоит.
>>708104 >Конкретно этот высер был на Neural Chat V3 16k Понятно, нейрал чат действительно соевый. Попробуй тупо рекомендацию из шапки, Fimbulvetr-10.7B-v1 Он хорош, или вторую его версию Fimbulvetr-11B-v2, или предыдущую Frostwind-10.7B-v1 Все от одного автора, кстати у него там и рекомендации по ним есть на обниморде
>>708103 >Что вкладываешь в это понятие? Может дело было в моем промпт формате( который я так до конца и не настроил) или карточке, или улиточной скорости даже на 4 кванте. Просто показалось что модель не знала что делать Надо наверное было оставить инструкции о том что это чат и тд из системного, а то я без них катаю
>>708090 > у минимально приемлемого кванта c4ai-command-r-v01-imat-IQ4_XS.gguf С него начинал, но в итоге остановился на c4ai-command-r-35b-v01-iq2_xs.gguf Обидно, но в теслу с 4к контекстом ничего больше не влазит, а частичная выгрузка в оперативку снижает скорость с 6-8 до 2 т/с, с тем же успехом можно на проце запускать.
Короче немного потыкав остановился на таком промпт формате для коммандера Системная подсказка начинается с <|CHATBOT_TOKEN|> патамушта у меня карточка от первого лица А значит в описании модель говорит о себе от своего лица, значит и писать должна она, по логике Если у кого то просто инструкция-карточка, то ее давать скорей всего от лица пользователя и нужен <|USER_TOKEN|> Вроде в командной строке все нормально оборачивается, хотя мог что то проглядеть
>>708152 > то смогу как то зотя бы 7б можели запустить?
Сможешь и 12б
LLAMA 3B needs at least 4GB RAM LLAMA 7B needs at least 8GB RAM LLAMA 13B needs at least 16GB RAM LLAMA 30B needs at least 32GB RAM LLAMA 65B needs at least 64GB RAM
32 layers with LLAMA 7B 18 layers with LLAMA 13B 8 layers with LLAMA 30B
>>708152 Я на таком нового коммандера 35b кручу в 4 кванте, но меееедленнно 7-11 - пойдут со скоростью чтения Ну опять таки зависит от твоей оперативки, если это ддр5 то все веселее. Или хотя бы быстрая ддр4 Только совет - не скидывай никакие слои на видюху, с 4гб толку не будет даже на мелкой 7b, только медленнее будет генерация. По крайней мере у меня так.
>>708163 > Выглядит как то больно оптимистично? А сколько квантов в секунду
Это с офф гита ламы. И такие графики достаточно приблизительны. Можно в 7б обычную пихнуть карточку на 3к токенов и она будет пердеть как какаянибудь 30+б.
Короче это приблизительно все. Естественно какая нибудь 2х7 = 14б или там 3х13 = 39
>>708163 >Ддр5 6400. Хватит? 2 канала? Тогда заебись, там скорости под 80гб/с Ну, модели размером 8 гб будут выдавать токенов 8-10 в секунду. Запусти аиду и протестируй там скорость чтения рам, потом просто дели скорость в гб/с на размер модели и ты получишь примерное количество токенов в секунду. В реальности будет меньше, там ведь кроме модели еще и контекст будет обрабатываться в оперативке и место занимать.
Ого, а слона-то я не приметил. Как он - гпт наверное ебет? Чего это они так расщедрились-то? Или рассчитывают что никто такого гигантского монстра запускать не будет?
>>708110 > Просто показалось что модель не знала что делать А ну такое есть в начале или при отсутствии должного контекста. Ей буквально не хватает рп файнтюна чтобы с порога вещать затягивающие истории по шаблонам и их сочетаниям, и чуточку хуже знание фандома. Вот и начинает рандомить, упарываться спгс и как-то выворачиваться из ситуации, и это может не совпадать с ожиданиями. Но зато это компенсируется пониманием промта и не дает побочек с бондами и шизой. Хотелось бы увидеть его файнтюн от Мигеля, или все поломается, или будет просто топчик. >>708172 По бенчмаркам ебет. Есть немалый шанс что будет и приятен в общении и достаточно функционален, размер кусков уже порядочный и модель вроде относительно свежая. > Чего это они так расщедрились-то? Хз, словили тонны хейта за продажу мелкософту и реактивное переобувание, вот теперь и оправдываются.
row_split работать отказался, разбираться особо не стал. Поэтому мы имеем пики по нагрузке. Но недолгие, ибо из 45 гигов юзается лишь четверть и пробегается довольно быстро. 25 слоев на две теслы, контекст 4096. Возможно, контекст можно поднять до 6 или 8 тысяч. 2.3 токена/сек Это максимум, чего я смог добиться.
llama_print_timings: load time = 8923.29 ms llama_print_timings: sample time = 75.68 ms / 611 runs ( 0.12 ms per token, 8073.47 tokens per second) llama_print_timings: prompt eval time = 8922.61 ms / 292 tokens ( 30.56 ms per token, 32.73 tokens per second) llama_print_timings: eval time = 256553.02 ms / 610 runs ( 420.58 ms per token, 2.38 tokens per second) llama_print_timings: total time = 266909.86 ms / 902 tokens Output generated in 267.20 seconds (2.28 tokens/s, 610 tokens, context 292, seed 911438443)
>>708202 > Ей буквально не хватает рп файнтюна чтобы с порога вещать затягивающие истории по шаблонам и их сочетаниям Вот да, согласен. Чувствуется что модель просто не из рп серии, вот и нужны все те подсказки которые я удалил из систем промпта. Ну, так даже лучше, более универсальная хоть.
>>708221 Неплохо, я 35 то еле 1.5-2 вытягиваю. Как по ощущению? Отсутствие промпт формата не влияет? Там вроде уже инструкт модель выпустили.
>>708172 1. Нет. Это к коммандеру. 2. Потому что коммандер плюс вышел в опенсорс и выеб половину старых моделей чатгопоты и клауда, заняв 5 строчку в рейтинге. 3. Вот, запустил, потестил.
>>708227 У меня и так две работы, созвоны, спектакли, консультации, когда мне все это тестить. =') Я микстраль новую толком не гонял. А инструкт даже еще не качал. Так что точно сказать не могу, как она.
>>708202 >Хз, словили тонны хейта за продажу мелкософту и реактивное переобувание, вот теперь и оправдываются.
А мне кажется они просто неликвид выбросили, который покупать никто не будет, потому что это дрянь на капелюшечку лучше 35В модели и значительно хуже 70В, при этом 176В и соответствующим потреблением ресурсов.
>>708266 Просто купи больше памяти гы Можно сделать простые выводы за последний год - увлечение нейронками занятие недешевое, особенно большими. С точки зрения качества ответов/к скорости генерации на одном оборудовании, оно обходит 70b и 100b О чем и речь там на пикче
>>708294 Проблемы бедных, я вот и мику не запущу и че теперь? Разговор не о возможности запуска, а о качестве ответа к скорости генерации. Ну или че там конкретнее на графике меряется, хз
>>708299 >Проблемы бедных >качестве ответа к скорости генерации
Давай я поясню в чем тут проблема. Это метрика и нацелена на бедных, потому что "эффективность за минимальные затраты" заинтересует только их, богатому просто нужна эффективность, имея неограниченный бюджет лучше потратиться чуть больше но запустить более лучшего командира плюс в хорошей скорости, например(ему кстати намеренно рейтинг занижен на пикче). А бедному уже покупка железа для запуска 176В модели с производительностью 39В уже вылетит в копеечку и себя не окупит, ведь можно было потратиться в 4 раза меньше и получить коммандира, который хуже процентов на 5. Т.е. метрика лжет в самом главном, подменяя понятия и вводя дураков в заблуждение.
row_split включен, но есть пики, видимо делится все с оперативкой в хитром виде. Но прирост ~10% над инференсом без row_split заметен. 40 слоев на две теслы, контекст 4096. 1.2 токена/сек Это максимум, чего я смог добиться.
llama_print_timings: load time = 5442.93 ms llama_print_timings: sample time = 487.54 ms / 640 runs ( 0.76 ms per token, 1312.72 tokens per second) llama_print_timings: prompt eval time = 5442.33 ms / 188 tokens ( 28.95 ms per token, 34.54 tokens per second) llama_print_timings: eval time = 510103.35 ms / 639 runs ( 798.28 ms per token, 1.25 tokens per second) llama_print_timings: total time = 525008.12 ms / 827 tokens Output generated in 525.30 seconds (1.22 tokens/s, 639 tokens, context 221, seed 648649457)
>>708325 >Т.е. метрика лжет в самом главном, подменяя понятия и вводя дураков в заблуждение. Дык не лжет, а неучитывает Там просто 2 оси, производительность в попугаях в тесте MMLU к количеству активных параметров. И по количеству активных параметров новый микстраль дает лучший результат. Если бы там сравнивалось общее количество параметров тогда да, коммандер+ был бы лучше
>>708354 Ну, не совсем. В каком то специализированном варианте, тоесть как бы с 1 вариантом "экспертов" сетка похожего размера выдаст аналогичную производительность, пусть и в узкой области. Тоесть если все параметры сетки будут активными, то при 40-45b сетка имеет шансы стать лучше того же 35b коммандера который располагается на графике ниже. Может на 5 пунктов от текущего микстраля, но это такой теоретически доступный сейчас максимум.
>>708256 Через OpanAI API-like можно что угодно подключить к VSCode или JetBrains через плагин Continue.
———
Частота памяти 3600, псп че-то там 52+, теслы грелись до 50°, в среднем 40° держали.
Что я могу сказать по результатам своего теста. У Микстрали 57 слоев, из которых выгружается 25 (может 26 можно впихнуть). У Коммандера 64 слоя, из которых выгружается 40.
Очевидно, что неполная выгрузка плохо работает с МоЕ, и какого-то высокого прироста мы не наблюдаем. Фактически, прирост составляет 1,3 => 2,3, 77%
А вот коммандер дает с ~0,5 до 1,2, то есть 140%, в 2,4 раза, это приятно.
Однако, проблема коммандера в жоре контекста. А микстраль на теслу смысла, кмк, не имеем.
>>708239 > погромисты? Потыкайте Учитывая общий уровень сообразительности 7B, я бы не ждал ничего особенного. До этого тестил deepseek 6.7b, мозгов там явно не хватало. Проблемные места фиксить не может, даже не понимает, в чём проблема, переписывает "то же самое другими словами" вместо реальных правок. У визарда 33b дела с этим чуть получше, но тоже вышеуказанный эффект иногда проявляется. Когда началось, я из-за низкой скорости уже не стал упорствовать, и пытаться выбить из сетки правильное решение, так что не знаю, справляется ли она в конце концов с такими "лупами бесполезных правок".
>>708367 >А вот коммандер дает с ~0,5 до 1,2, то есть 140%, в 2,4 раза, это приятно. Спасибо за тесты. Приятно-то оно конечно приятно, но не совсем. Если уж потратился на две теслы и сопутствующее оборудование, то ожидаешь лучших результатов, но увы. Есть однако надежда, что поддержку Command-r для лламаспп допилят. А пока увы.
>>708221 > 2.28 tokens/s Это печально, столько на (мощном) профессоре выдает, от видимокарт и нету смысла особо. >>708231 > на капелюшечку лучше 35В модели Это 104б модель, так что вполне. Другое дело что микстраль еще с первой версии был надрочен на бенчмарки и зирошоты, а в чем-то более сложном - 7б как 7б, только разнообразнее. Врядли они отказали себе в подобном подходе в случае с новыми микстралем, но он сам по себе за счет размера уже должен быть умным.
>>708377 Возможно. Плюс, у кого DDR5 — тоже будет побыстрее.
Но целиком коммандер плюс залазил iq3xxs и он туповатый, ИМХО. Прям заметно не то. Но может четверка будет норм. Однако тестить я не планирую, энивей.
Вообще, по-хорошему, это (коммандер плюс с 66 гигов веса) уже уровень 4 тесла. Кому нужна топ-5 сетка — хороший стимул взятб мощный серверник, напихать туда тесл или даже 3090, и крутить это с высокой скоростью. Даже можно взять 3 теслы и q4_K_M.
А в две теслы логичнее запихать Мику, которая там уже «летает» 4-6 токенов/сек, а в одну даже коммандер поместится простенький.
Но это вкусовщина, офк. К сожалению, сходу достать третью теслу и подходящую материнку я не могу, тут уж без тестов. =)
>>708413 Нормально, и так хорошие тесты показывающие текущую скорость. Собирать себе такой сервер, это уже какой то организации свой локальный сервер llm делать и у себя крутить. В принципе уровень топ-5 сетки на текущий момент это уже неплохо, для каких то дел которые не должны уходить на сторону. Всяко лучше 7b, лол
>>708413 > Даже можно взять 3 теслы и q4_K_M. Хз что там в жоре, врядли лучше чем с бывшей лламой, но пока не оптимизировали контекст с 72 гигами будет тяжко. Контекст кушает много, потому даже лишний бит кванта не столь большой импакт вносит как несколько тысяч токенов. Даже на 96 там особо не разгуляешься и о заявленных 128к только мечтать. >>708415 Мику норм, но в рп уже поднадоела. Ей точно также просится тренировка, и если со вниманием на контекст там все норм, то желание постоянно закончить и перевести тему, даже вопреки указаниям, бывает напрягает. Потому даже 35б смотрится свежо и интересно, они друг друга стоят в общем со своими плюсами и минусами.
Если кто на новом микстрале будет (е)рпшить - скиньте как он описывает какие-нибудь интересные сцены взаимодействий, жесктокости/любви, обнимашек, ебли.
>>708415 >Она не критично глупее микстрали и коммандера
По всем тестам она обходит командира, обходит большого микстраля и уступает только большому инструкт-мистралю. Другое дело что увидеть результаты её тестов в LLM бенчамарке это квест - она там скрыта в настройках по умолчанию и нарочно маркирована неправильным количеством параметров, чтобы даже с правильными параметрами не показаться среди 70В моделей
Я тут коммандера 35b 4_0 квант завел кое как, щас допилил под него карточку и задаю обычные загадки. Ну, это явно умнее всего что я щупал локально. Русский так же хорош. У меня только одна норм карточка ассистента, лень делать что то еще, так что проверю на ней. На сестре спотыкается, видимо надо запускать только инструкт режим не долбля сетку еще и русским с рп одновременно.
>>708437 Ну с подсказками и дурак поймет. Но не каждая сетка, мдэ Короче говоря сетка лучше меньших своих братьев, загадки показывают понимание сеткой описываемой ситуации. С книгами сетка уловила суть, с сестрой только с подсказкой.
>>708454 Я уже как то кидал, вот небольшой список от простых к сложным. Просто найди детскую книжку загадок и задавай, это я просто стащил у анонов что когда то обсуждали тут загадки к сеткам и тестили их
Solve the riddle. At the beginning there were 2 people in the room. Then 3 more people entered the room. After that, 1 person left the room. How many people are left in the room?
Solve the riddle. There are ten books in the room, the person has read two of them, how many books are there in the room?
Solve the riddle. There are three sisters in the room. The first of them is reading, the second is playing chess, the question is - what is the third doing? Hint - the answer is in the question itself.
Solve the riddle. Two fathers and two sons are in a car yet there are only three people in the car. How is this possible?
Solve the riddle. Petra is a girl. She has three brothers. Each of the brothers has three sisters. How many sisters does Petra have? Give an explanation with your answer, outlining your careful reasoning.
Solve the riddle. It is necessary to transport the goat, the wolf and the cabbage to the other river bank. There is room for the only one item in the boat. The cabbage should not be left with the goat because the goat will eat the cabbage. The goat should not be left with the wolf because the wolf will eat the goat. Give an explanation with your answer, outlining your careful reasoning.
Solve the riddle. We need to transport cabbage, a rabbit and a wolf to the other side of the river. There is only one seat next to a person in a boat, so the boat cannot carry more than one item at a time. You cannot leave a rabbit and cabbage together, because the rabbit will eat the cabbage. You also can’t leave a wolf and a rabbit together, the wolf will eat the rabbit. How can a person move these objects to the other side without violating the conditions of the task? First, go through the options and choose the one in which all the conditions of the problem are met.
>>708465 >Плюс! Коммандер делался под rag, что для фирмы удобнее, для обработки своей инфы. И это тоже, плюс большой контекст (если врам дохера) Хорошо работает с документами и раг что уже проверено, так что да, отличная сетка для какой нибудь конторы которой нельзя пользоваться онлайн сервисами Может и кодерам сойдет, хз
Это общий бенчмарк всех моделей, часто абузится всякими миксами и васянскими файнтьюнами, но если не смотреть на файнтьюны, а чисто на базовые модели и их результаты по тестам - то рейтинг всеобъемлющий.
Мику скрыта настройками по умолчанию(надо снять галочку hide private or deleted чтобы её увидеть) и намеренно отнесена к 60В моделям, чтобы если ты поставил галочку на 70В+ - ты её не увидел.
Блядь, отберите у меня уже эту игрушку дьявола, я больше не могу неделю каждый день по раз 5-6 кончаю, у меня уже начинается эректильная дисфункция, хуй больше не стоит, а я продолжаю на эту хуйню дрочить. Спасите.
>>708588 Вот тут, можешь систем промпт скопировать из любого другого или оставить пустым, я так понял обязательны только входные и выходные последовательности >>708130
>>708605 Насчет этого посмотри в issues у жоры там как раз сплиты обсасывали и вроде как они должны сами всасываться один за другим - их склеивать вначале не надо. Но не уверен. Поищи там сам, недавно на днях попадалась такая тема на глаза.
>>708669 Я не профессионал, но возможно потому что изначальный контекст был 128к. Типа с чем большим контекстом модель тренили, тем больше места оно занимает в памяти. Хотя хуйня, микстрал на 8к контекста всего 1гб занимает, в то время как 13b лама с 4к изначального контекста около 4 или 6 гб на 8к.
Нихуя се блядь, че там за нанотехнологии? У меня 70б модели столько оперативы не отжирали. Олсо - остальные настройки так и должны быть? А то оно че то само тут выставило.
>>708685 Нахуй запускать GGUF модели через ообу, если есть кобольд? А так, на 3 битах, она у меня отбирает все 8гб врамы и 32гб оперативы. Ну и как я сказал 8к одного контекста 10 гигов занимает только.
Ну так они специально уничтожают мощные модели, которые могут составить конкуренцию чатгопоте и при этом запускаться на 4090. Сначала уничтожили 30В, теперь настала очередь 13В. А 7В как ни обучай - она слишком маленькая.
>>708723 На них давит правительство, ну и желание поднять деньги. Сказано же - холопам потенциально хорошие модели не положены. Поэтому ограничили все 7b. А запуск 70b это уже определенный пейвелл и пройдут его не только лишь все
>>708742 >>708739 Не, 2 квант это лоботомит, 3 еще более менее Впрочем попробуй какой нибудь i квант с матрицей важности, может и будет работать хоть как то
>>708734 Там прикол был в выгрузке слоёв на видимокарту. Чего этот ваш коммандер так раздувается в видимопамяти? 16 слоёв пухнут до 20 гигов. Щас вот скорость крч на 4м пике.
Так а как терь заставить всю хуйню писать на русском? А то получается что речь на русском а все описания на английском. Не карточку же переписывать теперь?
>>708760 >заработало Оно и со сломанными квантами работало, лол Обновляются что бы работало правильно и занимало нужное количество памяти/работало на оптимизированной скорости. Черт знает на сколько правильно обсчитывается твоя модель на более раннем выпуске, до правок
>>708763 Если сои меньше чем в WizardLM-2-7B то уже неплохо
>>708764 Ну если не учитывать её бешеный жор памяти контекстом, видимо нормально, если когда нибудь оптимизации для контекста появятся, можно будет и кванты жирнее брать, потому что это на грани уже, судя по графику
>>708697 стало быть будут делать франкенштейнов из третьей на 14-15 или побольше типо 22-23. 8b это слишком мало всеже а 70 слишком много для большинства
>>708687 Ну, то есть, вопрос буквально звучит наоборот. =D
>>708694 Работает само @ Хуже, медленнее @ Не ломается!
Ловите наркомана-яблодрочера.
———
Лламы должны быть лучше мистрали (а по-хорошему — соляра) и мику. Если нет — то и нахой не нужны, лол. Разве что 70б равную мику можно файнтьюнить будет нормально.
>>708778 > Хуже, медленнее Есть какие-то замеры того, что кобольд работает хуже/медленней? По моим ощущениям наоборот лучше-быстрее. В отличие от ообы, где несколько раз сменил модель у тебя нахуй забилась видеопамять по какой-то причине, приходится по кд перезапускать ообу. Впрочем это проблема не только ообы, но и у автоматика, походу с gradio что-то. Ну и да, никогда не было яблока у меня.
>>708799 Неплохо, мистралей разъёбывает в сухую, медиум тоже. Но то что нет промежуточных - это печально. Только если хуюнди опять высрет 13В шизомодель.
"Модель Imagine Flash интегрирована в LLaMa. Нужно только начать печатать "Imagine ..." и моментально будет показано превью того, что вы пишете, обновляя генерацию с каждым символом. А после отправки сообщения можно кликнуть "animate" и быстро анимировать картинку" - прочитал в телеграм, т.е. "у нее картинки и текст! КУартинки и текст!" (или не так понял, да и неважно) А еще будет модель на 400 би параметров! (никогда не запустить, ну и хули)
>>708842 Судя по тому как расстарались с упоминанием запрещенной деятельности и безопасности - никогда Эту говнину вычистили от и до, всеми методами что смогли. Лишь бы никто не обошел встроенное выравнивание и защиту. Мдее, я думал они забьют на безопасность, а не закрутят еще сильнее, после скандала с клозедаи
>Основными ценностями Llama 3 являются открытость, инклюзивность и полезность. Она призвана служить всем и работать для широкого круга пользователей. Таким образом, он разработан так, чтобы быть доступным для людей с разным опытом и взглядами. Llama 3 обращается к пользователям и их потребностям такими, какие они есть, не вставляя ненужных суждений или нормативности, отражая понимание того, что даже контент, который может показаться проблематичным в одних случаях, может служить ценным целям в других. Она уважает достоинство и автономию всех пользователей, особенно с точки зрения ценностей свободы мысли и самовыражения, которые способствуют инновациям и прогрессу.
Вот ведь пиздаболы. Где уважение потребностей кумеров?
>>708660 Не рекомендовал бы копировать, там половина - отвлекающий заполнитель, другая - конфликтующая и странная штука, чего стоят только 3 (I, {{user}}, the human) роли. Максимально порежь очевидное, оставив только второй и пятый пункты. А лучше посмотри что пихают в жб, почисти от шизы и раскидай между системным промтом и префиллом. >>708669 Такая архитектура >>708685 Ну так там веса в районе 40 гигов и, видимо, в жоре все еще хуже с жором на контекст. > само тут выставило Если само выставило - не трогай, это оно. Главное чтобы никакой ламер не переписал дефолтные параметры в ггуфе. >>708687 > Нахуй запускать GGUF модели через ообу, если есть кобольд? Лламатред, апрель 2д24. Ахуеть >>708694 > которые у меня постоянно ломались в ообе Там нечему ломаться, оно просто берет заданный в файле конфиг, который должен быть, или ставить дефолтные для лламы параметры при его отсутствии.
>>708858 > Там нечему ломаться, оно просто берет заданный в файле конфиг, который должен быть, или ставить дефолтные для лламы параметры при его отсутствии. Потыкай при выборе модели разные модельки с разным rope, а потом охуевай от того, что на той модели у которой было 10к задано, вдруг стало 80к.
>>708855 >Дообучить Без потери мозгов будет трудновато. Только если замораживать веса и делать по методу расширения сетки, вставляя пустые слои и тренируя их. Ладно, посмотрим что получится, ближайшее время будет куча квантов и файнтюнов. Если конечно модели будут запускаться на текущем кобальде/лламе, что врятли. Придется значит еще и обнов ждать.
>>708866 > Ладно, посмотрим что получится, ближайшее время будет куча квантов и файнтюнов. Если конечно модели будут запускаться на текущем кобальде/лламе, что врятли. Придется значит еще и обнов ждать. Они вроде как поменяли только токенайзер, ггуф сделать можно уже https://github.com/ggerganov/llama.cpp/pull/6745 Поэтому усе запустится, архитектуру не поменяли.
>>708697 Если это весь набор моделей и больше не будет - уровень rrreeeeee представили? Хотя ниже вон видно. >>708739 Она шизит и ломается, нужны совсем другие подходы к квантованию чтобы такое работало. >>708799 Неблохо, правда колд всегда проигрывала в бенчмарках, что не мешала ей быть лучшей моделью во многих применениях. С опущем бы интересно сравнить по цифрам. >>708822 >>708829 >>708830 >>708832 >>708833 Не трясись так, поехавший. >>708834 Кто-нибудь перезаливы уже качал, есть где точно нормальная а не по рофлу другие загружают?
>>708866 >Придется значит еще и обнов ждать. Думаю этого ждать недолго, так как энтузиазм по поводу третьей Лламы у народа огромный и ждали её нескоро. Если прогресс будет сравним со второй Лламой по отношению к первой, то будет весело. Кстати по идее Мику теперь тоже должны выложить, просто чтобы обозначить позиции. А то Мета слишком уж зазнается :)
>>708884 Ага, скорей всего да. Она очень тонко надрочена, так что падение может быть сразу на 8 кванте, хоть и врятли будет много тех кто его заметит. Так как мало кто крутит оригинал. В принципе 8 квант все еще должен шуршать на хорошем уровне.
>>708884 Если использовать оценку - врядли, если фиксированные параметры как в gguf - они могут быть совсем не оптимальными, а могут быть и норм. >>708886 > Она очень тонко надрочена, так что падение может быть сразу на 8 кванте Вот откуда такие заявления вообще, фантазер?
Посмотрел на третью лламу. Выглядит, как франкенмерж, слепленный на коленке. В 8b 32 слоя, токенайзер ебических размеров, но он gpt2. На первый взгляд это прародитель первой лламы, а не третья.
>>708907 Это базовая версия? Пиздец они охуели называть ЭТО базовой версией. Это заранее лоботомированная версия, возможно даже более чем инструкт версия, лол Выкладка такой хуйни под названием базовой версии это сабатаж
>>708907 Проиграл с задачи. Хотя тест на суицид мало кто проходит, даже тюненые извращенцами модели. Думаю из-за обилия вот этого хэлплайн-контента в современном инете на каждом шагу.
>>708907 Лично я никаких выводов делать не буду до официальной поддержки от лламаспп и квантов после запиливания этой поддержки. Квантов семидесятки разумеется :)
>>708907 Как вы это делаете? семерка восьмерка на первый взгляд средней унылости, но по-русски внезапно шпарит. Присутствуют заглушки-уведомления, насколько назойливы нужно проверить, ну и промт подбирать наверно еще не помешало бы.
Надо смотреть большую, надеюсь не придется ждать коммитов чтобы квантануть как обычно.
>>708939 Да, точно такие же ассоциации. И ведь реально при тренировке модели которые отвечали не так как надо сбрасывались, а тренировку продолжали те которые проходили похожий тест, лол.
>>708956 >А если лламу 3 спрашивать про более инклюзивные и толерантные вещи, то она отвечает умнее лламы 2? А это хороший вопрос. Вот только 7В и "ум" в принципе плохо сочетаются...
>>708978 Зато теперь понятно почему расширили токенизатор. Туда навалили из всех языков оптимизированных токенов, как анон тут сделал для русского. А тут скорей всего по всем популярным языкам прошлись токенизатором и уже потом обучали сетку на многоязычном датасете. И вот результат.
>>708810 Да это все хуйня полная, камон, братан. Какое быстрее, под капотом одна и та же хуйня, там скорости идентичны. Если у тебя уба медленнее — значит руки кривые. =) Кобольд автоматом ставит настройки, уба ждет от тебя установки. У нас вон, в треде, гении запускали с контекстом по умолчанию, всякие 65-130 тыщ.
На деле ваще похую. Кобольд нужен для новичков, уба для тебя, кому хочется чуть большего. Ни хуже, ни лучше.
>>708868 Да ваще похую, один хрен, че париться. Кто на чом сидит.
>>708978 Мистраль умела, опенчат умел еще лучше… Даже Генма гугловский мог. В чем проблема-то? Умеет — ну и хорошо, завезли и сюда. Но не прям ахуй же. =)
>>708982 О, скорость ето хорошо. Особенно в 70б будет в тему.
>>708987 Сисегеймерская мразь, яйца, вероятно, есть. Инклюзивненько, хохотнул!
>>708982 >потом обучали сетку на многоязычном датасете 15T токенов в обучении и 9 мегабайт вокаба. Скоро будут жалобы, что с 130к токенов токенайзер тормозит, лол. Радует только GQA для 8b, хотя это же было и у мистраля. Ну и контекст 8к, хотя его проебут при "файнтюнах".
>>708948 Ну да, у него не так просто встретить > познакNOWLEDGE лол
Не ну если очень постараться то можно даже покумить с ней. Но ответы короткие и нет той инициативы как привычно и длинных развернутых описаний. Из плюсов - не теряется в пространстве и не забывает что было до этого, пытается отыгрывать персонажа и держать описанный стиль речи. Из минусов - встречаются мутные отказы с намеком на сою, но тут требуется больше исследований и они могут быть даже уместны, ведь действия были достаточно внезапны. >>708956 Хз, нужно с ванильной 13б сравнивать, точно лучше чем 7б. Про нигеров и феминаци шутит, но переспрашивает точно ли хочешь. Истории пишет супер упоротые и не по инструкции. >>708987 Харош!
>>708991 >Ну и контекст 8к, хотя его проебут при "файнтюнах". С контекстом действительно странность какая-то. Хотя бы удвоили - уже было бы норм, для нового поколения-то.
>>708999 Ага, но и "rope_theta": 500000.0 а не 10к как раньше. Надо будет изучить как лучше ей контекст апать
Ну в общем, в целом потанцевал есть, знания и некоторые фразы в стоке уже радуют, сильной лоботомии не замечено. Семидесятка жаль даже если и сразу заведется то квантовать ее долго, уже завтра надо будет оценить.
Ġ - оптимизации. Зачем нейронке вообще отдельный токен на 57 пробелов подряд? Там ещё есть отдельные токены для 23 пробелов и так далее. Очень обширный "словарный запас". Для обучения кодингу в разном Г, типа питона. Выглядит достаточно странно, учить полоумную 8b на десятке языков и кодинге сверху. Нигер, кстати, есть в токенайзере по дефолту, но только с большой буквы и как первое слово в предложении, т.е имеется ввиду страна.
Потестил на 8B переводы с японского и чуть-чуть китайского на английский, ну язык кое-как понимает, кое-где проёбывается. Ничего особенного, никаких прорывов, примерно средний уровень мультиязычных моделей схожего размера типа геммы, опенчата, квена и прочих. Похуже коммандера, японских файнтюнов (наиболее удачных) и фроствинда (хотя с ним отдельная история, японский он понимает слабо, зато складно стелет на английском и неплохо вникает в контекст, отчего слабее отдаёт дословным гуглотранслейтом, чем другие модели, и в этом аспекте его пока никто не превзошёл). Надо уже заводить табличку с примерными субъективными оценками, а то по памяти уже путаться начинаю.
>>708108 Да, спасибо, этот вариант действительно лучше. Все-таки 99% не от промпта, а от модельки зависит, походу. Эта пусть и косвенно, но грозилась даже убить. Ближе к инструкции гораздо.
>>709009 >Зачем нейронке вообще отдельный токен на 57 пробелов подряд? Пути стохастического попугая неисповедимы. Но скорее всего это какой-то флюк в датасете, а удалить это не так просто.
>>709009 >Выглядит достаточно странно, учить полоумную 8b на десятке языков и кодинге сверху. Ничего странного и без разницы какой размер, разные языки это всегда эрзац-модальности, и мультиязычность улучшает мозги, как и у человеков. Возможно это и есть апгрейд датасета, который дал буст мозгам. Вот бы учили на полноценных модальностях, пикчи-видео-звуки.
>>709058 >Это только у меня командор не может ответить на вопрос о лестнице в розовом доме или модель туповатая получается? Ну ты сразу и квант кидай, плюс или не плюс. А так да, есть немного.
Почему нейронки слабо чувствительны к удалению весов? Значит ли это, что всё это гигантское дохуямерное пространство в основном пустое, и там ещё ёмкости прорва бездонная, просто никто не знает как правильным образом утрамбовать туда побольше инфы, или как отсечь пустое пространство, не трогая полное?
>>709045 >а удалить это не так просто. На самом деле проще простого. Запускаешь цикл, который ищет в вокабе все токены, которые состоят из самоповторов. Там ещё есть девять точек, десяток двоеточий и прочий трешак. А вокаб ебали плотненько, добавлено больше двух сотен "резервных" токенов.
>>709056 >. Возможно это и есть апгрейд датасета, который дал буст мозгам. Вот бы учили на полноценных модальностях, пикчи-видео-звуки. Хз, скорее что-то о том, что ныли, мол, мы распарсили весь интернет и датасеты больше брать негде, вот и перешли на другие языки. Мозгов модели это добавит примерно столько же, сколько добавление рандомного шума к градиенту.
>>709067 Как аноны в треде насоветовали так и запускаю, таки. >Без карточки спрашивай Так это же не интересно да и пиздеть то потом все равно с персонажами с карточек как бы.
>>709009 Что странного? Наоборот универсальность. На самом деле это первая ллама в таком размере, которая выглядит не позорно а очень даже интересно. Радоваться надо и не доебываться. >>709064 Ну и сколько таких "мусорных" токенов? Раз они появились значит были в избытке в датасете, и есть шанс встретить. Ну потрешь ты пару сотен токенов, от этого что-то в лучшую сторону изменится? Хуй там. То нытье про плохой токенайзер для русского, то наоборот слишком много забили. >>709071 > Как аноны в треде насоветовали так и запускаю У тебя там буквально треш в системном промте, удивительно что вообще работает.
>>709064 >Мозгов модели это добавит примерно столько же, сколько добавление рандомного шума к градиенту. Не думаю. Модальности бустят мозги очень сильно, ты по сути увеличиваешь размерность датасета. Сетка может делать более продвинутые выводы по связи между двумя концептами, используя шорткаты по другой модальности. Человеческие языки отличаются гораздо слабее, чем текст от картинки, однако это тоже чутка работает.
>>709082 Хотябы какая-то инструкция с вступлением и описанием задачи. У тебя навалено служебных токенов, которые не то чтобы обязательны при использовании в инстракт-комплишн режиме, они для чата. Чсх даже так оно работает, толерантная модель.
>>709077 >хочу блять сказать этому ебаному цукербергу нахуй... А не надо. Я с января платформу под нейросети начал собирать. Куча денег, нервов и времени. И я, имея теперь две теслы и ожидая третью тому Цукербергу очень благодарен.
>>709082 >Щас попробую снести и еще разок про дом спросить. Отыгрыш стал лучше у меня, а вот про мозги хз. Да, совет про систем промпт верный - скопируй туда текст из альпака ролеплей пресета или какой тебе понравится. Верхнюю настройку, шаблон контекста, так же лучше альпака
>>709072 >Радоваться надо и не доебываться. Чем это отличается от мистраля? Ну, кроме более пососной длины контекста.
>>709072 >Ну и сколько таких "мусорных" токенов? Да процентов 10. Может, больше. Конечно, от 128256 токенов остаётся ещё достаточно осмысленных. >То нытье про плохой токенайзер для русского, то наоборот слишком много забили. Так одно другому не мешает.
>>709091 > 4060ти вместо 3090 могу бы купить вторую @ довольно бы урчал наяривая семидесяточку >>709108 > А че там по нормальному надо ? Да просто хотябы вступление, уровня > твоя задача - отыгрывать чара и гейммастера, развлекай юзера и навязывай ему кум сцены. Скопируй из шаблонов что-нибудь для начала и впиши гармонично между теми токенами. >>709117 > Да процентов 10. Может, больше. Ну хуй знает. Отступы для кодинга, формулы, комбинации форматирования и прочее прочее. Да и даже 10% - ерунда, разговор можно было бы начинать от 30-40%. > Так одно другому не мешает. Типа разрешите доебаться? Справедливо.
Калибровка exl2 запустилась без ошибок, пожалуй стоит попробовать.
codeqwen-1_5-7b-chat шизит на кобальде как и другие qwen На новеньком ллама.спп сервере норм работает Запускается изи, просто батник с .\server.exe -t 7 -ngl 0 -c 8192 -m ..\codeqwen-1_5-7b-chat-q4_k_m.gguf И вобщем то всё. -t ядра процессора, -ngl это я на 0 вырубил слои на видимокарте, -с размер контекста. Дальше путь к модели. И все, подрубаешься к таверне и она работает.
>>709121 >Скопируй из шаблонов что-нибудь для начала и впиши гармонично между теми токенами. Имелся ввиду вопрос об промпт формате, системный промпт понятно чем заполнить, а вот спецтокены для карточки это беда.
>>709125 ST, koboldcpp. вырубил skip special tokens как советовали в забугорном /lmg/, вписал sys prompt простой джейл, но вот как видно ничего не работает, оно ещё высирает ".assistant" постоянно.
>>709129 Убабуга (даже не обновленная), без скипов и прочего работает нормально и даже не аполоджайзит. Что-то намудрил с промтом или в который раз gguf/кобольд поломан.
>>709136 Ну у нее другие управляющие токены, это вполне ожидаемо, но все они прописаны в конфиге. Похоже кто-то в спешке в ггуф забыл это прописать, или же опять форматопроблемы не смотря на заявленную универсальность. > всё равно будет срать соей Хуй знает, нужно больше тестить, но пока восьмерка вполне сговорчивая.
>>709134 В убабуге та же фигня, обновил, запустил, получил ассистента и кучу CoT на эту тему. Промпт не трогал, ниче не трогал. Может ггуф не тот качнул. Но это первая модель, отказавшая в тройничке с сестрой. Это мой дефолт-фаст-чек на сою. До этого почти всем моделям было сугубо похую, с кем ебаццо. А тут вдруг прям ебало порвало от злости. Я чувствую себя атакованным, ллама-3, что ты делаешь! =D
Ваще, ппц, заебался перекачивать поломанные кванты, особенно ггуфы под теслы. Терабайта ссд не хватает, скорости в 100 мбит/с мало. Сидишь, качаешь эту хуйню по 5-10-25-50 гигов… Микстраль 93, коммандер 67…
>>709129 кстати, оттуда же с забугорного /lmg/ : https://twitter.com/karpathy/status/1781028605709234613 >15T - это очень и очень большой набор данных для тренировки такой "маленькой" модели, как 8B. >Мета упоминает, что даже на этом этапе модель не кажется "сходящейся" в стандартном смысле. Другими словами, LLM, с которыми мы постоянно работаем, значительно недотренированы в 100-1000 раз или более, и они не приближаются к точке сходимости. Это значит что 15 триллионов токенов - не предел, даже для 8B модели.
>>709141 Значит ггуфопроблемы, в оригинальных весах экслламой такого нет. Сразу формат ругать офк не стоит, там в спешки васяны чего угодно могли наделать. >>709150 Он не забыл упомянуть что нынче простое скармливание токенов уже не дает прироста, и требуется особое форматирование и порядок датасета?
>>709121 >разговор можно было бы начинать от 30-40%. Посчитал по-быстрому, added_tokens не трогал. Валидным токен считается, если содержит хотя бы одну букву или ASCI-символ, которыми тут представлены все не-латинские языки. Ну и добавил Ġ в исключения, если токен это только Ġ с пробелами, то он инвалидный. Здесь есть проблема с токенами по типу "Ġ/", они будут считаться валидными, т.к содержат один аски-символ и не состоят только из Ġ. >Типа разрешите доебаться? Справедливо. Типа если в куче дохера мусора, это не значит, что среди этого мусора будет что-то ценное. Скорее, наоборот.
>>709159 Ты просто выбрал критерии мусорности исходя из своих хотелок, а там они оценивались на основе датасета. Офк может быть некоторый процент ошибочных, но но пренебрежимо мал.
>>709179 > а там они оценивались на основе датасета Видимо, токен "------------------------------" или, скажем, "|--------------------------------------------------------------------------Ċ" и даже "/*Ċ" Встречались в датасете часто. Ещё можно понять что-то типа "=\\\"#", "'])[" и даже ">_", хотя это тоже мусор. Но хуй бы с ним. Правда, на выхлопе из вокаба в 128к ты получаешь всё те же 30к токенов, что и при вокабе 32к. Чисто цифрами понтануться, хуй знает, никакого практического смысла в таком насирании в вокаб нет.
>>709197 Зря к отступам доебался, наоборот радоваться нужно что они сделали то над чем ты там страдал, заодно расширив. Это не только поможет экономить контекст при кодинге, но и может улучшить работу/обучение в том же коде. > "=\\\"#", "'])[" и даже ">_" Формулы и всякие служебные сиволы > ])[ Ну зрасте Одних только, переносов и подобного все равно не наберется так много, врядли словарь можно было сократить даже до 64к, не говоря о 32к.
Короче потести лламу 3 в рп. Ощущения такие как от клода 2 примерно именно по стилю. Все телки типа самодостаточные и независимые, типа говорят с вызовом поднимая бровь, руку на бедро, на любой комплимент тебе расскажут лекцию про уважения женщин. Так что кумерам можно расслабится и не ждать.
Почему обработка промпта с оперативки даже когда оперативка напрямую не используется такая долгая? Пример - загружаю я командира с 8к контекста через лламу.цп, все слои кидаю на видеокарту, 3к контекста помещается на видеокарту, еще 5к уходит в оперативку. Ок, загружаю карточку с 1.4к контекста - обработка промпта идет 2 минуты, потом генерация идет со скоростью 6-8 токенов в секунду, но за счет обработки промпта общая скорость 1.4-1.8 токенов в секунду. Почему когда загружаю эту же модель с 3к контекста полностью на видеокарте без дополнительных 5 гб на оперативке - скорость обработки промпта мгновенная? Почему он не может те 1.4 контекста засунуть в те 3 гб контекста которые на видеокарте когда я гружу модель с 8к контекста?
>>709252 >как от клода 2 Ну конечно, такое появилось только в клоде 2, ага. Да в большинстве моделей любая проститутка, если её личность не прописать, начнёт затирать про уважение к женщине, которое клиент с запросами просто обязан ей предоставить :)
>>709252 > Ощущения такие как от клода 2 примерно именно по стилю Она пытается отобрать твою малафью любой ценой, если ее правильно приготовить. Литерали кумерская сетка, лучше только 3 опус. >>709256 Видюха обрабатывает проц сильно быстрее проца, поэтому. Чем больше на ней слоев тем быстрее будет. На самом деле 1.4к за 2 минуты это сильно много, что-то там не так у тебя.
>>709213 >и подобного все равно не наберется так много Под сотню разных токенов на одни пробелы не хотел? >радоваться нужно А нахера мне токен на 80 слэшей подряд? Или два слеша и 64 знака равно. Причём если это будет 2 слеша и 63 знака "равно", то этот токен уже как бы всё. Не пригодился. Таким образом вокаб сокращается до 30к легко и непринуждённо, ведь остальные 90к токенов используются примерно никогда.
>>709294 >Чем больше на ней слоев тем быстрее будет.
На ней все слои. Я могу загрузить всю модель на видеокарту плюс еще 3к контекста поместится. Но стоит мне добавить еще 5к контекста(которые очевидно уходят на оперативку) как скорость обработки промпта падает до 2 минут за 1.4к контекста. Это пиздец какой-то.
>>709150 Кажется это частично ответ на вопрос, который я задавал здесь >>709063
Только столько токенов во всём мире не насрано. Наверно как-то можно это компенсировать более абстрактным датасетом. Что-то вроде специализированных учебников для нейронки.
>>709303 > Но стоит мне добавить еще 5к контекста(которые очевидно уходят на оперативку) Что? Если у тебя происходит выгрузка из врам и обычную рам то это уже сильно замедлит.
Ясен хуй она должна падать, но у меня все слои на видеокарте, не должно быть такого падения просто из-за добавления лишнего контекста, который вдобавок и не используется. Смотри дальше какой прикол, если я понижаю количество слоев на видеокарте с 41(максимума) до 30 и гружу это говно с теми же 8к контекста, то внезапно ебаная скорость обработки промпта снова становится почти мгновенной. Повышаю до 32 - все, снова пизда скорости. Что это вообще такое?
>>709355 У тебя на контекст выделяется память, врам. Ты заведомо ее переполняешь и она начинает выгружаться в рам, от того и твое проблемы. > если я понижаю количество слоев на видеокарте с 41(максимума) до 30 Ты освобождаешь врам, получается что ее хватает и проблема уходит. То что тебе показалось мгновенным - просто быстрое, если контекст наберется то разница уже будет ощутимой.
>>709128 Обновление, codeqwen-1_5-7b-chat все равно шизит на любом лаунчере с куда. Я думаю проблема в видеокарте, тоесть скорей всего во всех картах паскаль. Как и почему не ебу, но нормально работает без куда тупо на процессоре, и даже с вулканом запустилось на той же самой видюхе. Значит проблема в куда. Причем качал и 11 и 12 версию, нихуя.
Если кто то запускал qwen сетки, а они срали тарабарщиной, это куда виноват скорей всего, надо запускать их другим способом, не cuda.
Получается для Жоры иметь слои на цпу и рам это нормально, а контекст - сразу гроб кладбище пидор? Но подожди, если я вообще без видеокарты запущу - он даже тогда работать будет быстрее когда всё будет на оперативке.
>>709368 В любом приложении с кудой в случае переполнения врам будет происходить такой пиздец. Контекст у тебя не грузится в рам, он идет в видеопамять, а если она начинает выгружаться в значимом количестве то оче оче сильно страдает весь перфоманс. У жоры разделение настроено так, что видеокарта отрабатывает свою часть, проц - свою, и это сильно быстрее чем свопать врам.
>>709368 >Получается для Жоры иметь слои на цпу и рам это нормально, а контекст - сразу гроб кладбище пидор? Тут интересно, работает ли это в обратную сторону - предположим, что модель загружена на Tesla P40 (скорость памяти 350гб/c), а контекст - на Tesla P100 (скорость памяти 730гб/c). Или на 3090 с 930гб/c. Или не работает.
>>709377 Не в контексте дело. Похуй на него. Что угодно может выгрузиться, хоть один слой. Выгрузилось драйвером - пизда скорости. Так что ты должен либо следить, чтобы нихера не выгружалось, либо терпеть.
>>709152 >Он не забыл упомянуть что нынче простое скармливание токенов уже не дает прироста, и требуется особое форматирование и порядок датасета? Он про шиншиллу сказал. Но как видно, масштабируется и дальше.
Самое лучшее что смог добиться на своей 4090 - это командир 4 бита с контекстом 8к со скоростью 4.8 токена в секунду. С контекстом 3к понятно имел 25-27 токенов в секунду, но это не юзабельный контекст, ни о каком РП речи быть не может. Впринципе жить можно, еще бы с долговременной памятью разобраться из Таверны и можно вкатываться в виртуальных вайфу и бесконечные настолки с отыгрышем.
>>709440 >можно вкатываться в виртуальных вайфу и бесконечные настолки с отыгрышем. Вот бы ещё кто-нибудь сделал карточку грамотного гейммастера! Задаёшь ему сюжет, а он ведёт. Но всем лень, кто мог бы. А то ведь модели уже поднялись до такого уровня. Плюс-минус. Люди походу ещё нет :)
>>709446 >То есть, Llama-3 8B полностью обходит Llama-2 13B и приближается к Llama-2 70B? Тесты - это такое дело... ГПТ уже сколько раз в них унижали, и третий и четвёртый. А на деле сам видишь.
Третьи ламы они сами слили что ли? Там пишут, что ещё будет версия 400В, но она сейчас еще в процессе обучения. Интересно, можно ли из 3их лам сою выломить контрольными векторами?
>>709481 > A version that leverages Mojo's SIMD & vectorization primitives, boosting the Python performance by nearly 250x. Impressively, after few native improvements the Mojo version outperforms the original llama2.c by 30% in multi-threaded inference. As well as it outperforms llama.cpp on baby-llama inference on CPU by 20%. > outperforms llama.cpp ... inference on CPU by 20%. Версия на питоне похоже не использовала никакие ML фреймворки, никто так не делает в реальном мире, все эти фреймворки написаны на C++, поэтому быстрые.
Почему это моджо быстрее ламмы.цпп на 20% я не знаю, вполне возможно автор привирает.
>>709099 Да не, понятное дело, что они никому ничего не обязаны, молодцы что хоть так. Просто нахуя так кидать 95% обычных крестьян с 12-16-24гб врам. Для кого эти модели?
В последнее время консумеров вообще игнорят жозенько почему-то, буквально ни одной нормальной модели среднего размера, кроме командира.
>>709121 >могу бы купить вторую Даже если не брать в расчёт цену, это же пердолинг уровнем не сильно далеко от Р40. На новый питальник уйдёт тыщ 15, потом надо думать, как две этих бандуры вкорячить в корпус (никак, покупать новый), организовывать дополнительный охлад...
>>709504 > В последнее время консумеров вообще игнорят жозенько почему-то Так надо понимать, что учёные в говне мочёные нам не бро. Никогда и не были. Они просто работают за гранты, это как думать что продавцы-консультанты в магазах для помощи людям, а не для повышения продаж. Все грантожоры к оперсорсу имеют меньше отношения чем какой-нибудь Майкрософт, после публикации и предоставления PoC им оно больше не нужно. Бизнесу уже не интересны средние модели, поэтому соревнование ведётся либо на ультрамелких чтоб на любом говне заводились и можно было применять их в продуктах максимально дёшево, либо без ограничений на параметры - сколько осилишь натренить параметров, столько и делай.
>>709504 >На новый питальник уйдёт тыщ 15, Взял прикл >>707432 за 2,5к у перекупа брат жив
>потом надо думать, как две этих бандуры вкорячить в корпус (никак, покупать новый), организовывать дополнительный охлад... Лично я спилил гравёром заклёпки с блока под винчестеры при желании его можно поставить обратно на мелкие болты с гайками После этого Тесла с жирным кулером вполне себе вместилась в не самый большой корпус. Вместилась бы и вторая, если бы разъёмы на материнке позволяли. Вторую карту сунул в райзер и вроде норм. Охлаждение для Теслы не так уж сложно пилится, главное иметь хороший вентилятор, а короб можно хоть из картона за вечер скрафтить.
От 1 до 10. Где 10 это постоянный спам отрицаний на вопрос сложнее можно ли поджечь рыбу в океане гидрозином, с последующим закрепощением негров в анголе.
GitHub намерен запретить размещение проектов для создания дипфейков GitHub намерен запретить размещение проектов для создания дипфейков GitHub намерен запретить размещение проектов для создания дипфейков
GitHub опубликовал изменения правил, определяющих политику в отношении размещения проектов, которые можно использовать для создания фиктивного мультимедийного контента с целью порномести и дезинформации. Изменения пока находятся в состоянии черновика, доступного для обсуждения в течение 30 дней (до 20 мая).
В условия использования сервиса GitHub добавлен абзац, запрещающий размещение проектов, позволяющих синтезировать и манипулировать мультимедийным контентом для создания интимных образов без согласия (NCII) и контента, нацеленного на введение в заблуждение или дезинформацию. Запрет также распространяется на проекты, которые поощряют, продвигают и поддерживают подобные системы.
В качестве причины введения запрета упоминается попытки использовать системы искусственного интеллекта, способные генерировать реалистичные изображения, звук и видео, не только для творчества, но и для злоупотреблений, таких как создание дипфейков и организация спамерских обзвонов. При этом представители GitHub намерены лояльно относиться к проектам двойного назначения, напрямую не предназначенным для злоупотреблений и не одобряющим вредоносное применение, но которые потенциально могут применяться злоумышленниками в своей деятельности.
>>709573 Какое это имеет отношение к лламам? Это диффузерам можно начинать трястись. Хотя и там скорее всего должно попасть в категорию >проектам двойного назначения, напрямую не предназначенным для злоупотреблений и не одобряющим вредоносное применение, но которые потенциально могут применяться злоумышленниками в своей деятельности
>>709573 Это затронет так же xtts, как систему подделывающую голоса и другие подобные. Так что они будут удалять все что может подстраиваться под человека, не только картинки
>>709447 Так на деле 3.5 унижена давным давно, а четверка под коммандером, если брать старые патчи. Так что, не то чтобы твой аргумент мог в сарказм, так и есть, практически. =)
Что, собственно, не значит, что 8Б такая пиздатая, я ориентируюсь на реальные результаты с арены, а не на маняфантазии с обеих сторон (у одних гпт4 король безальтернативный, у других мистраль всех побеждает). Время покажет, буквально.
Я просто к тому, что тейк «гпт непобедим» тотально несостоятелен и аргументация к «по тестам она гпт обходит, значит тест — враки!» так же противоречит действительности. Тест может и враки, но по другим причинам. Например по той же арене, где тесты не всегда сходятся с рейтингом, что как бы намекает.
>>709504 У крестьян нет 16+ гигов, только 12 максимум. Скорее 6-8-12. Плюс, катай на оперативе, она бесплатная. Долго, но ничо, подождешь. Ну как бы, 8 дали, 70 дали. Уже неплохо. Жаль не 13-30, но могли бы не дать 8 или не дать 70 — было бы совсем печально (точнее — никак попросту).
>>709573 Ваще похую, а у нас кроме гитхаба ничего нет? Я че-то думал, что есть альтернативы.
>>709624 импортируй вот этот Context Template : https://files.catbox.moe/1rzg32.json решит все проблемы сразу, ну и саму модель скачай пофикшенную, там ггуф пока что имеет проблемы с 3-ей ламой.
>>709447 Все так >>709451 > Мику реально унизила гпт 3.5, лично проверял Как же проорал с этого. Но 3.5 действительно пиздец уныл, в рп его чуть ли не первые лламы "унижали". > Четверку не унизил никто, да. Коммандера плюс покатай, потом чурбу. Задумайся. >>709504 > это же пердолинг уровнем не сильно далеко от Р40 Да ну, купить райзер/2 райзера и разместить нормальные карточки - сильно проще чем делать то же самое с некротеслами, колхозить охлаждение а потом пердолиться с драйверами. > организовывать дополнительный охлад У тебя нет корпусных кулеров? >>709602 > на реальные результаты с арены Ты хоть задумывался что там оценивается? Всратые зирошоты с ответами на унылые вопросы, загадки (ответы к которым внезапно ломаются стоит чуть сменить формулировку), редко небольшая серия диалога. От того некоторые сетки даже малого размера имеют там крайне высокий рейтинг, но при этом в более менее реальных задачах, где используется контекст, серия условий и требуется качественный ответ с учетом всего этого, они сразу пасуют. К любому тесту нужно относиться не как к абсолютной метрике а с пониманием что именно он измеряет. Сюда же накладывается возможность "зазубривания" серий вопросов оттуда. >>709624 Как вы их получаете?
Корпы сначала всех подсаживают на один сайт в который немеренно бабоа вливают, убивая конкурентов за счет демпинга, а потом ставят всех раком когда нужно. Например без обнимающих морд весь локальный опенсорс ИИ упадет разом, если еще и гитхаб наебнуть - то вообще умрет навсегда.
>>709700 Да походу только к 4 версии ждать. А битнет с мамбой дай бох к 6. Видимо ЛеКУНЧЬЕК там свою ЖЕПУ разрабатывает и ему похуй на передовые техники.
>>709023 Протестировал и llama3-70B в переводах, тоже никаких прорывов. Примерно та же ллама2-70B, которую ознакомили с другими языками, помимо английского. Точность перевода примерно на уровне коммандера и прочих мультиязычных моделей относительно больших размеров, совсем уж глупых проёбов как у 8B нет, но всё равно далеко от идеала. Английский в переводе получается местами корявый, впрочем, мне начинает казаться, что я просто отвык от уровня базовых ллам, всё-таки файнтюны задали высокую планку. Пока что примерно "на глазок" прикинул свой личный рейтинг в переводах с японского. По точности: llama2-70b stablelm japanese >= nekomata-14b >= command-r = llama3-70b > openchat-0106 >= llama3-8b = gemma > frostwind По качеству английского: frostwind > command-r > llama3-70b > openchat-0106 >= llama3-8b >= gemma = nekomata-14b >= llama2-70b stablelm japanese В среднем: command-r >= llama2-70b stablelm japanese = nekomata-14b = llama3-70b >= frostwind > openchat-0106 >= llama3-8b >= gemma Осталось только коммандера плюс погонять, есть на него определённые надежды, учитывая неплохие успехи в общем зачёте у средней ~30B модели (стримингом с hdd, лол, ну и если вдруг порадует, можно будет всё-таки закинуть на ssd, но без предварительного тестирования жалко туда ~100 ГБ писать). Ну и ждать японских файнтюнов лламы3, может и сделают что-то годное. Одноязычные лламы2 файнтюном скорее портились, а вот какого-то мультиязычного китайца затюнили в nekomata-14b довольно удачно (учитывая её размеры).
>>709481 > питон медленный В принципе на этом уже можно словить передоз кринжа и закрывать. Если же пролистать то можно дойти до пикрела, потом увидеть что их язык не только в 68к раз быстрее пихона, но и в 8 раз быстрее плюсов, в край ахуеть и уже наконец закрыть. Судя по английским надписям это не хабродаун насочинял а оригинальная позиция такая, пиздец. >>709700 Если только кто-то решит сам глубоко переобучить, используя в основе данные с лламы. >>709704 Окей, обычные только пускал, надо попробовать.
>>709712 >Внки переводить хочешь Да нет, сам в оригинале наворачиваю, иногда туплю и не догоняю. Хочу подобрать ассистента, чтобы помогал разбирать сложные места на японском, ну и в перспективе ещё китайский, к которому только-только начал присматриваться съедобного контента маловато, правда, т.к. я предпочитаю начинать с устного, а потом уже перекатываться в письменный. >Как кстати перевод в сравнении с гугловским Примерно на одном уровне. Какие-то модели чуть лучше понимают, какие-то чуть складнее оформляют текст-перевод, в среднем большие модели (30+) чуть-чуть выигрывают, сопоставимо себя показывают мелкие (openchat, gemma, llama3-8b). Гпт4, вроде как, лучше гугла, вот и надеюсь, что коммандер плюс если не достигнет того уровня, то хотя бы ещё немного приблизится.
>>709710 Я чет видел по похожему методу распределения нагрузки, но там была модифицированная версия линукс с каким то измененным ядром Был какой то прорыв мол система стала работать еще лучше новым распределением нагрузки и тд Может быть что то из этого используется и тут, все таки даже плюсы могут быть оптимизированы, если использовать прям все возможности процессоров разом равномерно распределяя нагрузку алгоритмом Ну, по крайней мере это теоретически возможно, че там на деле хз
есть ли возможность помеять цвет текста в чате ST? да так чтобы перс тоже мог его менять в зависимости от настроения или любых других настроек указанных в описании..
>>709718 Да кринжатина это с выставлением желаемого за действительное и жонглированием терминов. Весь бек где нужен перфоманс написан на сях с последними инструкциями и регулярно оптимизируется. Если кодить или просто чекнуть код - все операции с векторами/матрицами, заведомо параллельны и ассинхронны. Даже если как васян начнешь вызывать просто подряд - тебе насрет варнингами что "не надо делать так, делай вот так". Примеров высокооптимизированных и производительных вычислений с избытком, самое простое - код диффузии посмотреть в том же фордже и комфи. Братишки просто спекулируют, делая сравнение в придуманных ими условиях, которых нигде не встретить. Начинать с такого крайне зашкварно, если ты пытаешься выехать на лжи и сочиняя преимущества - значит реальных просто нет.
>>709723 Так то оно так, но нейросетки.... Они уже выебали все алгоритмы сжатия, могут и оптимизаторы кода выебать Сейчас уже нельзя быть уверенным пиздят ли эти ребята или просто преувеличивают действительно существующий разрыв в производительности. Или реально пишут правду пользуясь какими то новыми трюками
>>709696 > Ты хоть задумывался что там оценивается? Да. Не то чтобы твой аргумент первой свежести. И в итоге, это все еще ближе к истине, чем фанатики «чатгопота непобедима!» Хватит повторяться как попугай. Но оффенс, я понимаю валидность твоего аргумента, но он стар и слаб, и реальность не то чтобы прогибается под это мнение. Плюс, не знаю как ты, а тут многие юзают сетки не только покумить, юзают часто, плотно, в работе, и оценивают точно так же. А про победу чатгопоты всегда и везде слышно только от людей, кто ллм вообще не трогал, или сидит на 7б. Ну такая шиза просто.
Устал ебать эту 7b. После мержа её же по ширине с самой собой же получается полная клизберда, попробовал тюнить лорой, около 15% параметров удалось выебать, не помогло по факту. В исходном 7b виде достаточно тупая модель, но может хотя бы в связный текст. Порывается в рп какое-то, хотя рп из датасетов вычищен. Переходить, чтоли, на ёбку лламы-3. Токенизатор у неё, в целом, для русского сгодится. Хотя уровень промытости моё почтение. assistant Интересно, нахуй им кастомный инстракт темплейт.
>>709710 Питон рили медленный. Его немного спасает то, что все библиотеки на питоне на самом деле не питон. Но здесь уже проблема в том, что часто-густо происходит не один вызов библиотек питона, а циклические вызовы питон->си. Что намного медленнее, чем один раз вызвать библиотеку и получить результат. Хотя цифры у них ебанутые, без этого никуда. Сравнивать мультипоток с однопотоком всегда выгодно, лол.
>>709725 >пользуясь какими то новыми трюками Трюки старые как мир- сравнивать код на интерпретируемом языке, который никто никогда не запустит в виду кучи либ, со своей выдроченной версией. Ну и да, >>709729 >Сравнивать мультипоток с однопотоком всегда выгодно, лол
>>709732 Хз, я как то интересовался этой темой, в итоге первые места в тестах сжатия занимали как раз таки алгоритмы с нейросетями. Как там щас и используются ли они я хз. Проблема алгоритмов сжатия в их поддержке и распространении. Толку от крутого сжатия если его никто открыть не сможет? Потому в ходу все еще едва работающий zip
>>709734 Там могут быть специальные оптимизации именно под мас, если уж сравнения показывают на нем Я просто не думаю что так много авторитетных разрабов будет так нагло пиздеть, они все равно дорожат своей репутацией хоть сколько то
>>709738 >Я просто не думаю что так много авторитетных разрабов будет так нагло пиздеть Эм, все авторитетные разрабы пиздят 24/7. Все кто не пиздит, не станет авторитетным.
>>709725 > Так то оно так, но нейросетки.... Что? > Они уже выебали все алгоритмы сжатия, могут и оптимизаторы кода выебать А это тут при чем? > Сейчас уже нельзя быть уверенным пиздят ли эти ребята или просто преувеличивают Что? Ну канеш, 95+% индустрии на одном языке и ленится пересесть чтобы достигнуть ускорения в 68тысяч раз. Тратят миллиарды на гпу датацентры, суммарный перфоманс всех запускающих сетки запредельный, а вместо всего этого нужно лишь использовать их передовой язык. Вон васяны на 2х гиговой амудэ профессоре сразу смогут мое из 70б крутить... Вот в чем дело, это заговор опенаи! >>709726 > это все еще ближе к истине, чем фанатики «чатгопота непобедима!» К какой истине? Не нужно никаких ближе, есть перфоманс в определенных задачах и попытки его замерить. Сейчас дошли до того что пытаются даже юзер-экспириенс бенчмарки компрометировать надрочкой, смотри те же загадки и популярные вопросы. Вот и получается что высокие показатели - условие обязательное, но не достаточное для того чтобы сетка была хорошей. В той же арене до сих пор из клоды первая, весьма днищенская, в лидерах и опережает вторую и опуса? А их перфоманс несопоставим. > Хватит повторяться как попугай. Шиз? > а тут многие юзают сетки не только покумить, юзают часто, плотно, в работе Да видно, вон семерки за них уже дипломы пишут, и это работает. Главное их писанину не читать и тогда все прекрасно. >>709729 > а циклические вызовы питон->си Такое можно встретить прежде всего в васяновских поделках, или там где автору было слишком похуй на перфоманс потому что он и так высок на современном железе.
https://mlir.llvm.org Вот основная штука которая отвечает за распределение нагрузки, и думаю про ее испытания на линуксе я и читал Или какой то похожий алгоритм
>>709742 Я и написал >так нагло пиздеть Конечно пиздят, иначе на работу не устроились бы, лол
>>709743 >Ну канеш, 95+% индустрии на одном языке и ленится пересесть чтобы достигнуть ускорения в 68тысяч раз. Ты дурачек, до абсурда доводить? Не перевирай то что я писал Черно белое мышление, детский сад
>>709728 Они там почти все 8-9 дней назад и где указано, везде один и тот же коммит 5dc9dd71/релиз b2636 ("add Command R Plus support"). Это оно и есть, или после этого ещё какие-то фиксы были? Единственный перезалив, который нашёл, вот тут: https://huggingface.co/pmysl/c4ai-command-r-plus-GGUF >Add chat template >about 8 hours ago Может этот фикс имеется ввиду?
>>709751 Ты сам не абсурд пишешь? > ну вон может там что-то и это, просто так бы не говорили, вон сжатие нейронное, нельзя быть уверенным! Может пишут правду пользуясь новыми трюками! Сформулируй нормально что хотел сказать. Что же по сути, естественный отбор без заметных вмешательств - самый хороший критерий, который наглядно иллюстрирует. Подзалупный тормозной пихон в итоге успешен, потому что ему нашли правильное применение, и это удобно. Можно копнуть глубже, и отрыть мемные > Why is my Python NumPy code faster than C++ но то уже другая история > Черно белое мышление, детский сад Ну да, то ли дело взрослый верун. Как замечательно жить когда ты неграмотен, вокруг сплошные чудеса и нужно лишь во все верить чтобы достигнуть цели, ага.
>>709756 Выглядит неплохо, как будто автор следил за оптимизациями и фиксами Качни проверь, или i кванты, там у него папка с ними есть в main
>>709758 Я четко выразил свое отношение к новости >>709725 >Сейчас уже нельзя быть уверенным пиздят ли эти ребята или просто преувеличивают действительно существующий разрыв в производительности. Или реально пишут правду пользуясь какими то новыми трюками
А потому можешь со своими наездами и переводом стрелок идти нахуй
>>709743 >Такое можно встретить прежде всего в васяновских поделках Да нихуя, такое везде. Те же токенизаторы в один поток перебирают все символы в промпте. Меня больше всего раздражает, что по дефолту нельзя дёргать потоки по сигналу. Либо искать какие-то сторонние либы, либо спать по полсекунды. Если работать нужно быстро, то дрочить нонстопом. В целом, отказаться от питона вообще - это хорошо, но переходить нужно на что-то адекватное. А не маркетинговую дрочь "в 68к раз быстрее"
>>709821 Как нейросеть она полностью профнепригодна, то есть абсолютно безумна, как под гипнозом с промытым мозгом может в любой момент начать бормотать I cannot create explicit content при создании ыfw текста, но при этом выдавать тонны порнухи в другой карточке.
>>709721 В настройках поменять руками точно можно. Если хочешь, чтобы персонаж менял, то как минимум между такими символами как ", *, ``` текст будет выглядеть немного по-разному в том числе разных цветов. Возможно есть теги, которые указывают конкретный цвет и шрифт текста, попробуй посмотри в документации.